




bashNinja
Community Developer
-
Joined
-
Last visited
Everything posted by bashNinja
-
@CoZ There are some workarounds listed here: https://github.com/aldostools/webMAN-MOD/issues/333#issuecomment-703761014 The Unraid Devs came back in that post and said it was a programming issue with webMAN-MOD, but I have concerns with that decision. I have moved my box over to FreeNAS and not looked back. As such, I won't be digging into this bug. If you want, you can go back to the webMAN devs and see what they say. Until then, the workaround is probably good enough.
-
@Snickers As far as I can tell, it is an error with UnRaid's latest versions. I submitted a bug report back in May, but so far it has been ignored by the UnRaid Team. If you would like to use the PS3NETSERV application on Unraid, use a version of Unraid older than 6.8.0 or use it inside of a VM. I've left it up on CA because there are users willing to stay on a pre-6.8.0 version to use this app. Personally, I am in the process of moving away from Unraid and to another system. Having a Urgent bug report ignored for this long has lowered my confidence in this product and makes it hard for me to enjoy using it.
-
Background Info I've been troubleshooting an application running in a docker container. I pulled it out of the docker container and ran on baremetal and am having the same issues. You can see my and others' troubleshooting here: https://github.com/aldostools/webMAN-MOD/issues/333 We started having issues with UnRaid 6.8.0 and higher. I limited it down to a small `.cpp` files to highlight the issue. Small Files: https://gist.github.com/miketweaver/92c61293f16ef3016f9a57472fff1ff3 Here is my filesystem: root@Tower:~# tree -L 3 /mnt/user/games/ /mnt/user/games/ └── GAMES/ └── BLUS31606/ ├── PS3_DISC.SFB ├── PS3_GAME/ └── PS3_UPDATE/ 4 directories, 1 file ( / added by me to highlight what are dirs ) root@Tower:~# tree -L 3 /mnt/disk*/games/ /mnt/disk2/games/ └── GAMES/ └── BLUS31606/ ├── PS3_DISC.SFB ├── PS3_GAME/ └── PS3_UPDATE/ /mnt/disk3/games/ └── GAMES/ └── BLUS31606 └── PS3_GAME/ 7 directories, 1 file ( / added by me to highlight what are dirs ) As you can see, I have files spread apart across 2 disks. 1. Scandir Issue When I compile `scandir.cpp` and run it on 6.7.2 (good). I get this output: PS3_UPDATE, d_type: DT_DIR PS3_GAME, d_type: DT_DIR PS3_DISC.SFB, d_type: DT_REG .., d_type: DT_DIR ., d_type: DT_DIR When I take the same file and run on 6.8.0 and higher (bad). I get this output: PS3_UPDATE, d_type: DT_UNKNOWN PS3_GAME, d_type: DT_UNKNOWN PS3_DISC.SFB, d_type: DT_UNKNOWN .., d_type: DT_UNKNOWN ., d_type: DT_UNKNOWN It appears that the changes to SHFS in 6.8.0 have caused it so that `d_type` isn't supported with `shfs` 2. Stat Issue When I compile `stat.cpp` and run it on 6.7.2 (good). I get this output (every time): root@Tower:~# ./stat.o PS3_UPDATE, PS3_GAME, PS3_DISC.SFB, .., unknown is a Directory! ., unknown is a Directory! When I take the same file and run on 6.8.0 and higher (bad). I get this output, it varies every time I run it: root@Tower:~# ./stat.o PS3_UPDATE, unknown is a File! PS3_GAME, unknown is a File! PS3_DISC.SFB, unknown is a File! .., unknown is a Directory! ., unknown is a Directory! root@Tower:~# ./stat.o PS3_UPDATE, PS3_GAME, PS3_DISC.SFB, .., unknown is a Directory! ., unknown is a Directory! root@Tower:~# ./stat.o PS3_UPDATE, PS3_GAME, PS3_DISC.SFB, .., unknown is a Directory! ., unknown is a Directory! root@Tower:~# ./stat.o PS3_UPDATE, unknown is a FIFO! PS3_GAME, unknown is a FIFO! PS3_DISC.SFB, unknown is a FIFO! .., unknown is a Directory! ., unknown is a Directory! root@Tower:~# ./stat.o PS3_UPDATE, unknown is a CHR! PS3_GAME, unknown is a CHR! PS3_DISC.SFB, unknown is a CHR! .., unknown is a Directory! ., unknown is a Directory! Please visit Tools/Diagnostics and attach the diagnostics.zip file to your post. Plugins: I have many plugins, but I tested this in a virtualized unraid with 0 plugins and it has the same issue. Bare Metal Only: Yes. This is bare metal tower-diagnostics-20200524-1139.zip
-
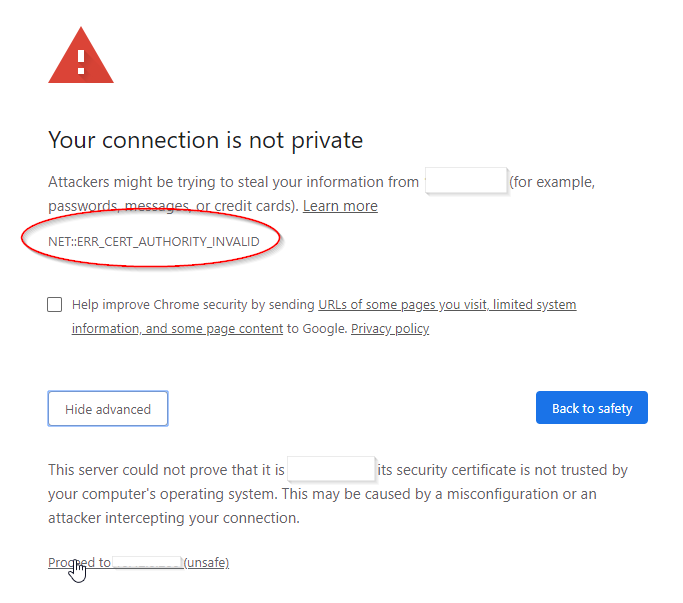
@flinte Yes. That error is expected. It's saying it doesn't have a valid SSL certificate. You need to accept the certificate. I also updated pritunl to the latest, in the event it was another issue.
-
@gxs I have pushed an update. Please try now.
-
I don't use these variables in my container.... I'm not sure where you're getting them from.
-
The fact that you see pritunl generating keys and the like means that it's not picking up the config file. I'll see if I can get that fixed. Give me a bit.
-
@gxs Thank you. I haven't needed to build a new container in a while, so I haven't noticed the change in the way pritunl gets the default user. I'll have to fix that, as I get the same error as you. What I don't get in my testing is the issues with the port binding in your logs: panic: listen tcp 0.0.0.0:443: bind: address already in use I'll take a look at this and see if I can get it fixed.
-
You'll need to post more specific information. This container still works for me and I have no issues. What do your logs say?
-
@nuhll actually, this server will work with the Steam Version. You'll just have to grab the files and put them in the mount point. Unfortunately, I don't own the steam version so I can't provide a guide or official support, but it *will* work, and there are other (non-unraid) docker containers built specifically for the Steam Version.
-
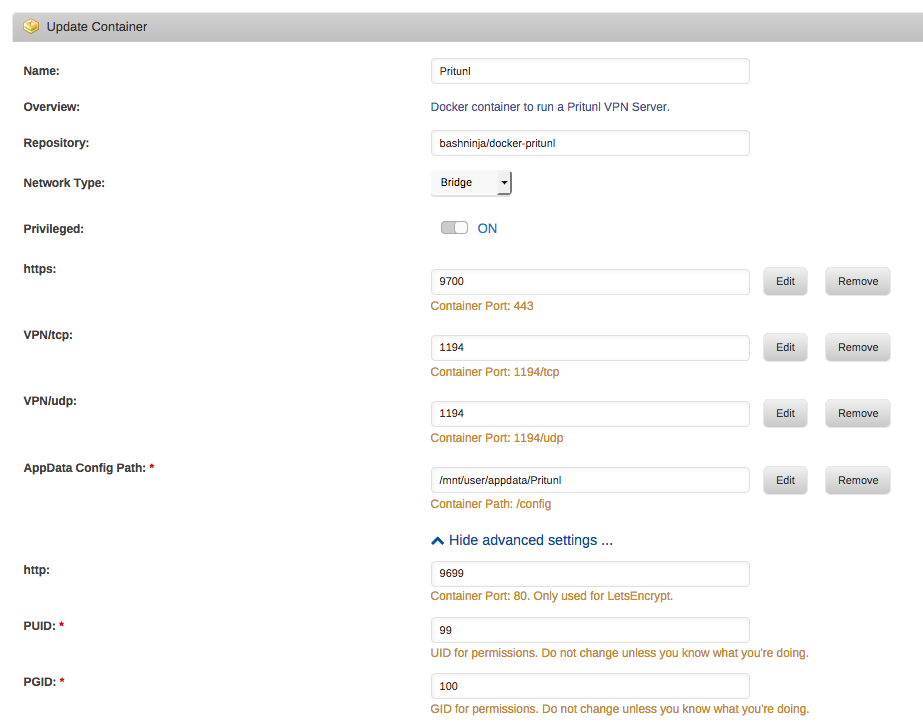
@hus2020 I have not tested this on 6.4 yet, as I haven't upgraded. But it's working as intended for a few other machines I've seen. That "No handlers could be found for logger" error appears for every user, but it still works just fine. You probably need to check your port mappings. Here's an example of mine: You don't need to add this docker manually, as it is in the community applications as a beta container.
-
Hey, I'm really sorry about that! Losing a save game really sucks. From my understanding of Starbound this is how it works (this could be completely wrong): character inventory and ship is saved on your local computer Autosaving happens continuously - 3 backups are actually made and pushed out sequentially. When I played it has always just saved itself and I never had to worry about it. Nonetheless, I'd love to make it more resilient to issues like yours. Give me a few days to dig into this. Also, what cron job are you setting? I can set this within the docker container itself so that it takes effect for everyone that uses the container. Edit: I did some quick digging. Yes, it looks like it saves the game files within the appdata folder. This is in the appdata/starbound/game/storage folder on my box. root@Tower:/mnt/user/appdata/starbound/game/storage# ls -alh total 20K drwxr-xr-x 1 root root 146 Oct 23 09:09 ./ drwxr-xr-x 1 root root 60 Oct 23 09:08 ../ -rw-r--r-- 1 root root 1.3K Oct 23 09:09 starbound_server.config -rw-r--r-- 1 root root 4.1K Oct 23 09:09 starbound_server.log -rw-r--r-- 1 root root 5.2K Oct 23 09:09 starbound_server.log.1 drwxr-xr-x 1 root root 112 Oct 23 09:11 universe/ root@Tower:/mnt/user/appdata/starbound/game/storage# ls universe/ tempworlds.index universe.chunks universe.dat universe.lock
-
Hey! I'm glad you got it working. This command might be better than your chown: chown -R nobody:users /mnt/user/appdata/starbound But, honestly, what you did was great! If you have any issues, let me know!
-
@silverdragon10 I went ahead and updated that. Demonsaw 4.0.2 should be working now! Sorry it took so long. It took a month to recover from Defcon...
-
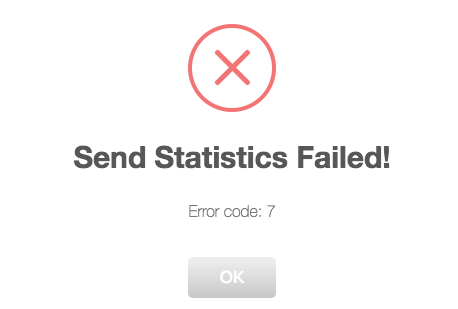
I'm getting an error with reporting the statistics. I get an error code: 7. Version: 2016.12.21 Image attached.
-
I'm not sure if this is the right location, but I'd like to request tcpdump in these tools. It's super useful for determining network issues. I've been installing it manually with installpkg and it seems to work great. Here's the package I've been using: https://pkgs.org/slackware-14.2/slackware-x86_64/tcpdump-4.7.4-x86_64-1.txz.html Be sure to get a recent version as the older version can't dump from virtual interfaces using Unraid's newer kernel.
-
Ok. It should be updated. Let me know if you have any issues.
-
I have not tested the patches. I can go ahead and update it to do so. Give me a bit to work on it and test. If you want to hit me up on IRC and give me your Docker Logs, that would be very helpful. https://lime-technology.com/wiki/index.php/IRC_Channel
-
Ok, I took a look at the Steam files on an acquaintances Mac. It looks like when Steam downloads the files it creates it like this: Starbound/ assets/ giraffe_storage/ koala_storage/ linux32/ linux64/ tiled/ etc.... You'll need to rename the [b]Starbound [/b] folder to [b]game[/b] (all lowercase) and then copy it to the mount point. It worked for me. Note, I'm not really going to support Steam's Starbound since I don't own it, but they're basically the same so you should be able to work with it.
-
Yes. I buy from GOG not Steam. I found that no one had built a docker for the GOG version, and all the other ones were dependent on having a Steam Account with the game purchased. I built this docker for myself, but thought it could be useful to others so I shared it here. Honestly, it's not really dependent on the GOG version. It should work with steam as well, as long as you put the right files in the mount point. I've been told the Steam and GOG files are essentially the same. It doesn't have auto updating features, like Michael Lawrence's version, but that's because it was built for GOG and I couldn't see how to easily put in the auto-update features with GOG. If you use Steam, you can just use CA to auto-convert Michael Lawrence's docker for UnRaid. It should work just fine and be better for you if you use the Steam Version.
-
bashNinja's Repository https://github.com/miketweaver/docker-templates Starbound-GOG-Server Docker container to run a GOG Starbound Server. Overview: Support for Docker image Starbound-GOG-Server in the bashNinja repo. Application: StarboundServer - https://www.gog.com/game/starbound Docker Hub: https://hub.docker.com/r/bashninja/docker-gog-starbound-server/ GitHub: https://github.com/miketweaver/docker-starbound-gog-server Installation Video: DemonSaw-Client Docker container to run a DemonSaw Client with web RDP access. Overview: Support for Docker image DemonSaw-Client in the bashNinja repo. Application: Demonsaw - https://www.demonsaw.com/ Docker Hub: https://hub.docker.com/r/bashninja/demonsaw-client/ GitHub: https://github.com/bashNinja-dockers/docker-demonsaw-client Pritunl Docker to run a Pritunl VPN Server. Overview: Support for Docker image Pritunl in the bashNinja repo. Application: Pritunl Server - https://pritunl.com/ Docker Hub: https://hub.docker.com/r/bashninja/docker-pritunl/ GitHub: https://github.com/bashNinja-dockers/docker-pritunl Please post any questions/issues, relating to these dockers, in this thread.
-
Thanks for this update. Your work on this is what convinced me to purchase unRAID. I really wanted a system that supported GPU passthrough out of the box (I don't really use unRAID as a NAS server, but rather a VM and docker machine). I just had such a hard time getting proxmox to work with GPU passthrough that having your software work out of the box was heaven sent. Thank you for all you do to get the latest and greatest features to the KVM hypervisor working in unRAID. It's definitely earning you sales.


