




muppie
Members
-
Joined
-
Last visited
Everything posted by muppie
-
I did a while ago but I started over again before this issue so I don’t think they’re related
-
it’s currently scanning the images again. I’m using a separate mariadb instance. Nothing changed except added GPU support
-
I tried that and that didn’t work either. However, now I get another error message: path lookup '/photoprism/.config/darktable' fails with: 'No such file or directory' ). Should I start over? It has been a bit problematic for me for some time so I think I can nuke it and start over.
-
I tried it but it doesn’t work. Thanks anyway!
-
Hi! I’m getting this error: FATAL ERROR: Creation of the user's processing profile directory "/photoprism/.config/RawTherapee/profiles" failed! ) for many of my raw files, but I can’t figure out how fix the error. I found this thread https://github.com/photoprism/photoprism/issues/1525 but I can’t figure out how to set the home variable in the unraid. Anyone else have this issue? M
-
Does anyone know how to set this up so it can be used with on an ipad via the Obsidian app?
-
I think they were created after I installed the app but thanks
-
Hi! I updated to 6.10-rc2 and lost access to the webgui when I am on my VPN. Before the update and on my LAN, it works without question. I have made some searches but the posts that I have found are relating to people losing access to the gui locally after an update but not mine. I have removed the network settings on the flash drive and rebooted but no change. Have someone else had similar problems and found a fix? I’m currently travelling so I don’t have access to the diagnostics unless they are retrievable from the ssh-ing in to the box. On a separate note, is there a possibility to enter the encryption password via ssh or is it webgui-only? Many thanks in advance for any assistance if possible. //M Edit: It is like the connection is dropped, but there have been no changes in my network between 6.9.2 and 6.10-rc2. It works if I roll back to 6.9.2. rc2 stops letting me access unraid via IP, not it is only .local that works.
-
I’m well aware of how user shares work, thanks. I’m trying to avoid unnecessary spinups of my drives and appropriate order of my files. No need to be rude.
-
Hi! I have looked around and can’t find this topic elsewhere. I believe I have files belonging to the same folder spread across several drives, e.g. one nfo file belonging to a movie on disk1, the sample on disk2 and the movie on disk3. My movie collection is too big to fit on one drive so I don’t think I can use ”gather” in unbalance. Is there a way to output a file where the the folders and its contents are stored or do I need to find another way? Many thanks and sorry if this topic has been raised before and I haven’t been able to find it /M
-
I posted mu question and logs in the github for the application and it appears that you need a special redis version that support json. As far as I can see, there is no template for the correct redis so we need to install it manuallly
-
I’ve filled out the redis IP and elasticsearch IP in the template and I’ve tried to review the screenshots again and to me they look the same. Attaching it here: I cannot spot any errors. If I add port to the redis IP it is duplicated in the logs (as IP:6379:6379) so I removed it.
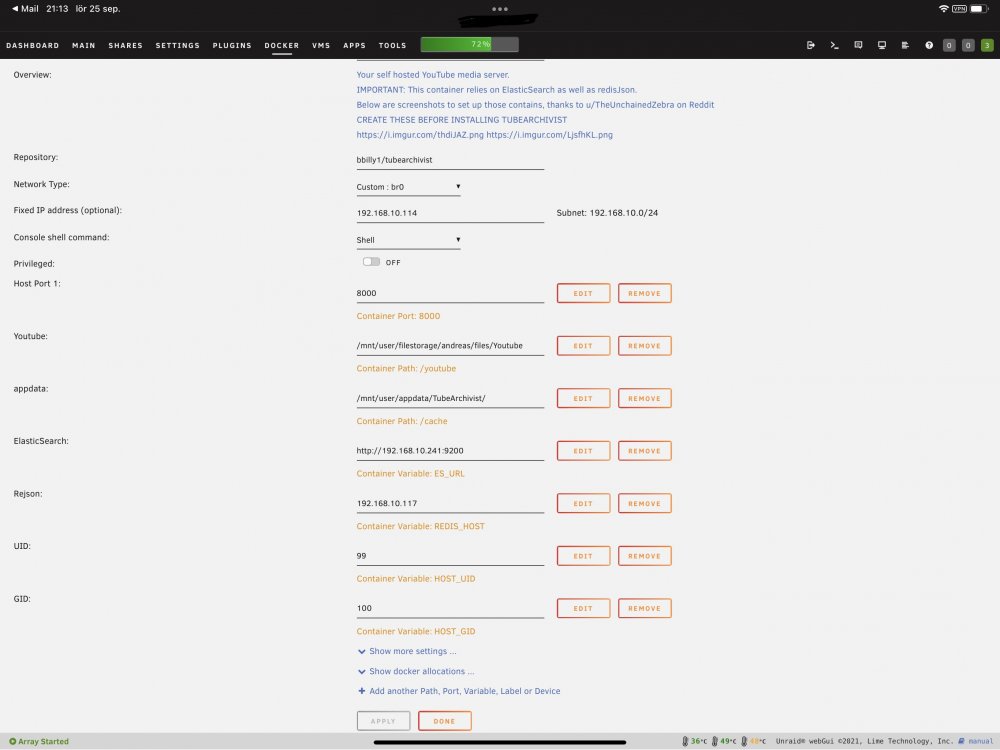
-
I have http in front but I’m still getting a Internal Server Error. Do I have the wrong redis version? I don’t have any special for redis json. Logs here:
-
I have other Redis and Elasticsearch dockers on my machine and it seems like they are connecting but Im getting an Internal Server Error when trying to use the web gui. Posting logs soon. Just not sure if I should exclude anything from the logs, should I?
-
Myabe this is the cause for me as well. https://forums.unraid.net/topic/90062-kernel-sd-7040-attempting-task-abort-scmd/ /M
-
Hi! I’ve recently begun noticing issues I’m not capable of diagnosing myself. I’ve had issues for some time regarding mover speed, cpu staying at 100% for unknown reasons etc. my logs state the following: Jul 19 13:21:52 server kernel: sd 10:0:2:0: attempting task abort!scmd(0x00000000c61bae8a), outstanding for 15140 ms & timeout 15000 ms Jul 19 13:21:52 server kernel: sd 10:0:2:0: [sdf] tag#2963 CDB: opcode=0x85 85 06 20 00 00 00 00 00 00 00 00 00 00 40 e5 00 Jul 19 13:21:52 server kernel: scsi target10:0:2: handle(0x0010), sas_address(0x4433221101000000), phy(1) Jul 19 13:21:52 server kernel: scsi target10:0:2: enclosure logical id(0x500605b0080852a0), slot(2) Jul 19 13:21:53 server kernel: sd 10:0:2:0: task abort: SUCCESS scmd(0x00000000c61bae8a) Jul 19 13:21:53 server kernel: sd 10:0:2:0: Power-on or device reset occurred Is there something wrong with sdf? Is there information missing from my post, like hardware, complete diagnostics etc? //M
-
Wondering too
-
There was nothing wrong with SWAG. I messed up my cloudflare settings which caused the error.
-
If you have the same redis connection refused message as @Geow, it doesn’t look like your connection to redis works. Have you checked that?
-
Hi! I rebooted my containers yesterday and after that my SWAG container won’t listed to the ports I’ve chosen. It worked flawlessly the days before that. I use 80/443 and they are portforwarded in my pfsense. I thought I mucked something up in pfsense so I’ve wiped it and started over, but no success. When I tried Nginx Proxy Manager, the port is suddenly open, even on the same LAN IP. As soon as I stop Nginx and start swag, the port is suddenly closed. I have other port forwards in pfsense set up and they work too. Swag is in br0. Does anyone have a clue what happened? I’m on the latest version of swag. I’ve forced updates and I wiped swag too but no successful.
-
-
## Version 2020/12/09 # REMOVE THIS LINE BEFORE SUBMITTING: The structure of the file (all of the existing lines) should be kept as close as possible to this template. # REMOVE THIS LINE BEFORE SUBMITTING: Look through this file for <tags> and replace them. Review other sample files to see how things are done. # REMOVE THIS LINE BEFORE SUBMITTING: The comment lines at the top of the file (below this line) should explain any prerequisites for using the proxy such as DNS or app settings. # make sure that your dns has a cname set for <container_name> and that your <container_name> container is not using a base url server { listen 443 ssl; listen [::]:443 ssl; server_name paperless.*; include /config/nginx/ssl.conf; client_max_body_size 0; # enable for ldap auth, fill in ldap details in ldap.conf #include /config/nginx/ldap.conf; # enable for Authelia include /config/nginx/authelia-server.conf; #Organizr ServerAuth #include /config/nginx/proxy-confs/organizr-auth.subfolder.conf; #auth_request /auth-0; location / { # enable the next two lines for http auth #auth_basic "Restricted"; #auth_basic_user_file /config/nginx/.htpasswd; # enable the next two lines for ldap auth #auth_request /auth; #error_page 401 =200 /ldaplogin; # enable for Authelia include /config/nginx/authelia-location.conf; include /config/nginx/proxy.conf; resolver 127.0.0.11 valid=30s; set $upstream_app 192.168.10.90; set $upstream_port 8000; set $upstream_proto http; proxy_pass $upstream_proto://$upstream_app:$upstream_port; # REMOVE THIS LINE BEFORE SUBMITTING: Additional proxy settings such as headers go below this line, leave the blank line above. } } Please note that I have Authelia enabled so comment those rows if you don’t use it too. Hope it helps!
-
I’ll share when I’m back home again in a few hours!
-
Did you reboot the swag container?
-
Sorry, i forgot to quote the other post. The one fron Lumpy


