

alturismo
-
Posts
6102 -
Joined
-
Last visited
-
Days Won
47
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Report Comments posted by alturismo
-
-
i can only confirm what @ich777 pointed, no issues here at all with my server and also with my maintained server(s) using i915's.
the hdmi dummy point here is not causing crashes, just to make safe reboots with no attached monitor (here atleast).
what always leads to random crashes described here is (sadly) the corefreq plugin for me, without adjusting anything, as soon its installed the server will randomly crash after a day, a week, a month ... i never tested corefreq plugin in combination without igpu so i cant say anything about this, this may just as sidenote.
-
 1
1
-
-
1 hour ago, gacpac said:
how do i set it up?
may start here
-
1
-
-
7 minutes ago, Leoyzen said:
I'm not sure it is about iowait.....
you see you have pretty high emby usage there ...
-
33 minutes ago, itimpi said:
I have just checked and I could pass my iPad through to iTunes in a Windows VM.
nice
")
i once tried this, iphone to a mac vm but with no luck (was a special flashing siuation), in the end it only worked by passing through the usb controller here, but thats some time ago ... of course the iphonne was "passed" through, but no chance to interact in dfu mode etc ... so i d say it depends what you want to achieve.
-
26 minutes ago, CS01-HS said:
pass an iphone to a Mac VM
thats mac .... you need a USB Controller passed through
Device passthrough through unraid works for almost anything ... but pretty sure not for an idevice
-
1
-
-
1 minute ago, Vr2Io said:
But I need host access, in general, you should enable host access for that.
me too
here it looks pretty persistent about macs on dockers while using macvlan, ipvlan as mentioned, great feature for those where the router is not struggling with it.
-
luckily im one of them who has no issues with macvlan, i tested ipvlan as alternative.
my experience is with my router (fritz) i ran into a issue as ipvlan assigns 1 mac (the same) to all, so my router was jumping in mapping the ip with the mac address. so first it looked ok but then i ran into timiouts, specially when access "externally" like laptop browser to a service like tvheadend, plex, emby, ... or it took a while until the service could be reached, so i reverted back for now, just as note if some may run into "issues" with ipvlan.
-
11 minutes ago, hawihoney said:
It's a descision that users make. If they want Facebook but not Google (or whatever) - it's their personal descision then. IMHO it's no valid argument to say "If you 'trust' Facebook you must 'trust' Google as well" .
true
i just think its funny what waves come up here for a one time registration
about the connection issues locally, i guess its due most have ssl enabled and try to use this url instead the LAN ip (if all are wanting local access only anyway ...), just makes me wonder why alot have so many concerns or questions while its standing in the release notes what is when ...
-
2 minutes ago, LTM said:
Also, have a read if the links in the quote below. The Qnap one happened only a month or 2 ago.
again i dont understand, then just dont use the feature, dont open the ssl port for your server and it wont be reachable from the url from outside
...
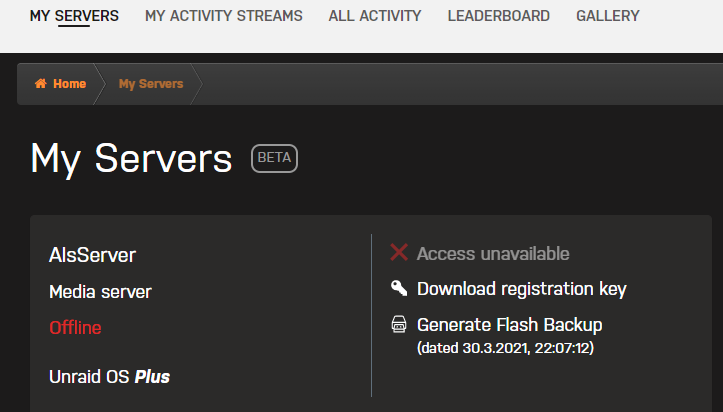
and im logged in ... and once used the plugin for the flash backup (cause i personally like the idea).
its still only optional as described in my point of view
-
 2
2
-
-
@Mik3 its in the release notes ... and btw im also from europe
this is really a fun when i think about it that pretty sure almost all here using a smartphone, facebook, ...
-
1
-
-
then may just log out, dont install the extra plugin, whatever ... all i see here its optional ?
and about new users, when i remember i had to give a email anyway, server needed to be online anyway, etc ...
weird discussion about a nice feature which is optional, my 2 cents about this.
-
2
-
-
not a bug but may a general question about the SMART actions lately
i wonder a little why there are these smart actions without activity ... and how long it takes to spindown ....
as sample
...
Dec 30 05:54:24 AlsServer emhttpd: read SMART /dev/sdb
Dec 30 05:54:42 AlsServer emhttpd: read SMART /dev/sdd
Dec 30 05:54:54 AlsServer emhttpd: read SMART /dev/sdc
Dec 30 08:23:59 AlsServer emhttpd: read SMART /dev/sdc
Dec 30 23:00:49 AlsServer emhttpd: read SMART /dev/sdd <<- here i really had access to a file for 30 minutes
--- spindown 7 hours later ... manually triggered by me today morning ....
Dec 31 05:51:23 AlsServer emhttpd: spinning down /dev/sdd
--- now again spinup and still running while there should be no activity ...
Dec 31 07:37:20 AlsServer emhttpd: read SMART /dev/sdc
Dec 31 07:37:35 AlsServer emhttpd: read SMART /dev/sdb
when i spin them down its all good until the next SMART Trigger coming ... is this meanwhile by purpose ? i know we need access to the drive to get SMART values, but extra spinning up the disks only therefore ? cant be done while the disk is active anyway ?
when the disk would be really active due activity, lets say plex is accessing the file due playback, then triggering the spindown wont help as its immediately up again as plex needs the access, thats why i wonder why a manual spindown is always fine when i see no activity and the auto spindown sometimes just doesnt come, even better would be to avoid these spinups with no activity.
i triggered now the diags in case of interest, and this also spinups the discs also due SMART
but i see its by demand ...
save system variables. + SMART reports
-
20 minutes ago, TechGeek01 said:
I haven't yet spun up a second server/instance to test the beta, but wanted to ask. Has the autostart VM issue been fixed from 6.8.3?
I have no idea if this hasn't been addressed, or if it was fixed in this, or a previous beta, but on 6.8.3, "autostart" VMs don't actually autostart on boot. I have to manually start them.
well, i dont think this was a general issue, autostart always worked here as sample and never been a issue lately.
-
and turning off the VNC VM ... will bring back all to normal
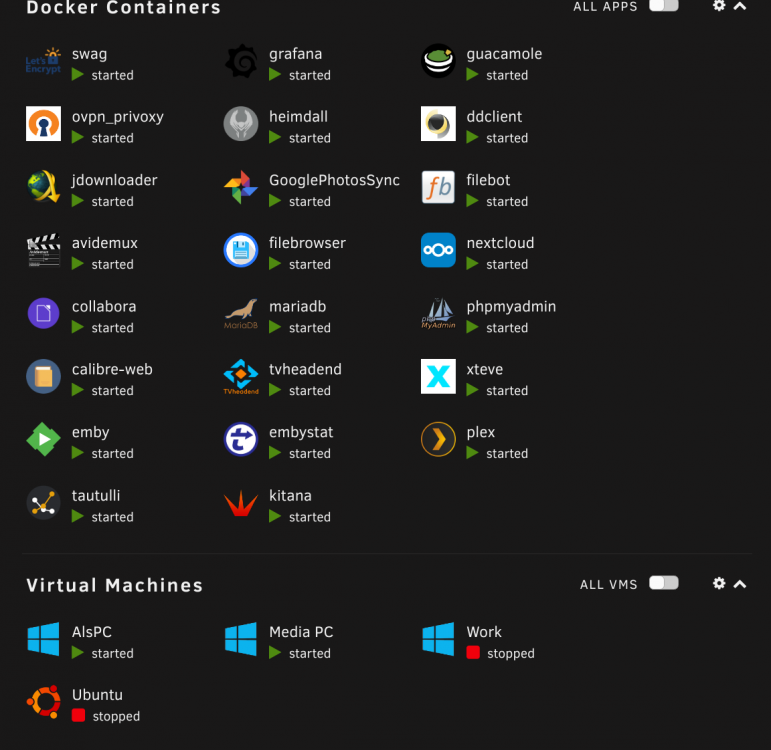
-
same here, dockers are 2 columms only, VM's only show the running with GPU, the VNC one is not displayed anymore when i started it
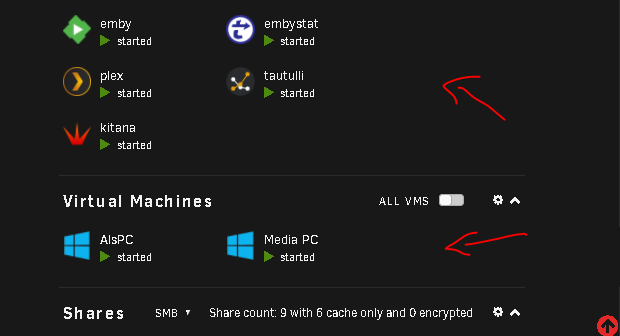
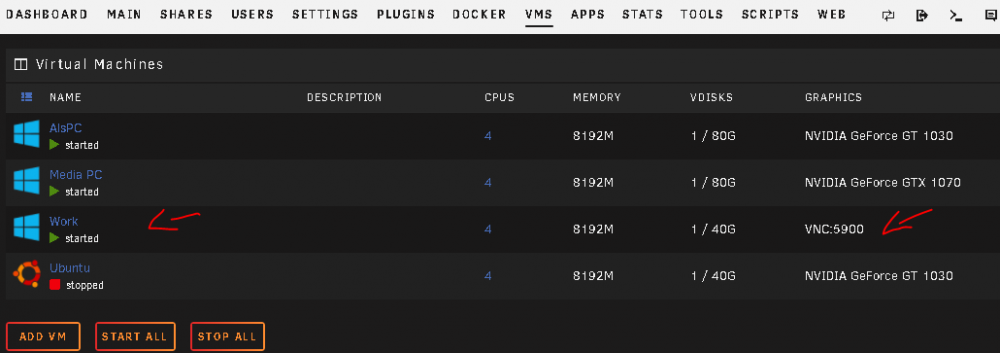
-
2
-
-
Hi, looks like i run now in the 2nd long run issue with 6.9 beta 30 here
it starts now again to struggle with the unraid web services (tested with different browser too)
uptime now 19 days ...
sample, CPU usage doesnt update anymore (and of course there should be something)
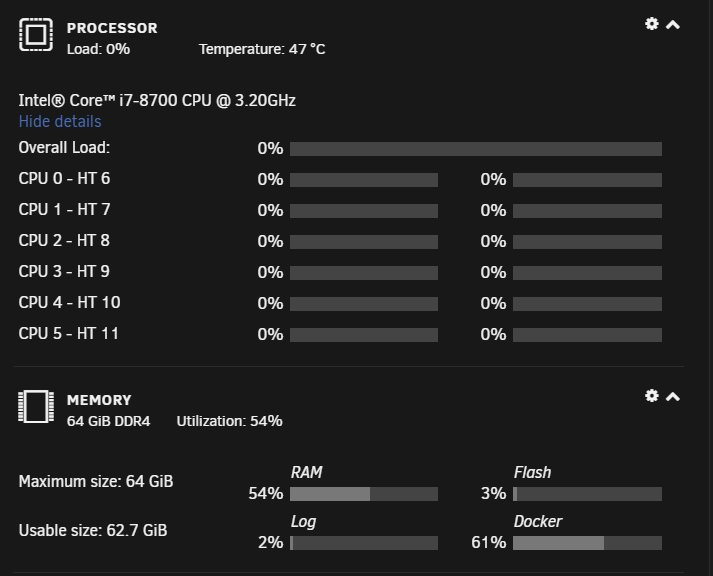
open terminal is broken now
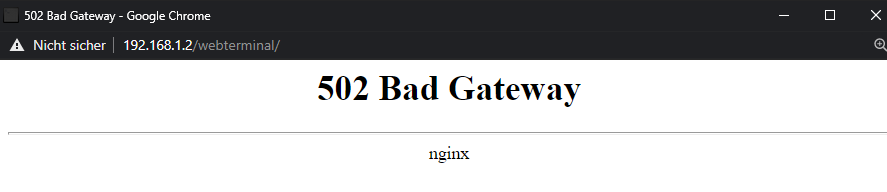
log page is broken (spins forever)
Rest still seems to be ok ... VM's up, dockers up, shares up, all reachable (not like last time)
all this was working a few hours ago.
from the tools/system log these are the latest entries
Nov 4 17:23:06 AlsServer kernel: br0: port 4(vnet2) entered blocking state Nov 4 17:23:06 AlsServer kernel: br0: port 4(vnet2) entered disabled state Nov 4 17:23:06 AlsServer kernel: device vnet2 entered promiscuous mode Nov 4 17:23:06 AlsServer kernel: br0: port 4(vnet2) entered blocking state Nov 4 17:23:06 AlsServer kernel: br0: port 4(vnet2) entered forwarding state Nov 4 17:23:07 AlsServer avahi-daemon[10889]: Joining mDNS multicast group on interface vnet2.IPv6 with address fe80::fc54:ff:feb5:951d. Nov 4 17:23:07 AlsServer avahi-daemon[10889]: New relevant interface vnet2.IPv6 for mDNS. Nov 4 17:23:07 AlsServer avahi-daemon[10889]: Registering new address record for fe80::fc54:ff:feb5:951d on vnet2.*. Nov 4 18:01:21 AlsServer nginx: 2020/11/04 18:01:21 [error] 13223#13223: *6383070 connect() to unix:/var/run/ttyd.sock failed (111: Connection refused) while connecting to upstream, client: 192.168.1.200, server: , request: "GET /webterminal/ HTTP/1.1", upstream: "http://unix:/var/run/ttyd.sock:/", host: "192.168.1.2", referrer: "http://192.168.1.2/Dashboard" Nov 4 18:04:01 AlsServer webGUI: Successful login user root from 192.168.1.200 Nov 4 18:04:36 AlsServer nginx: 2020/11/04 18:04:36 [error] 13223#13223: *6383365 connect() to unix:/var/run/ttyd.sock failed (111: Connection refused) while connecting to upstream, client: 192.168.1.200, server: , request: "GET /webterminal/ HTTP/1.1", upstream: "http://unix:/var/run/ttyd.sock:/", host: "192.168.1.2", referrer: "http://192.168.1.2/Dashboard" Nov 4 18:05:20 AlsServer unassigned.devices: Error: shell_exec(/bin/df '/mnt/disks/192.168.1.45_internal' --output=size,used,avail | /bin/grep -v '1K-blocks' 2>/dev/null) took longer than 2s!diags attached.
i leave it now running for a little before i reboot or even may rather roll back to .29 which was running nice from day 1 to update to .30 (24/7)
if you need any further infos from the system, let me know, but as this is now the 2nd time the system runs into a "more or less" unreachable state ... i guess it has something todo with the emhttpd changes ...
no changes, no new VM's, no new Dockers, ... just a small docker switch a few days ago but that shouldnt be the reason for unraid webgui issues.
may a way to restart the httpd service ? just to make sure ?
external ssh access is still working too (like last time)diags.zip
-
ok, 1st booted in safe mode GUI, no plugins loaded.
-> system is reachable again in LAN, VM and Docker also working
just no plugins loaded ...
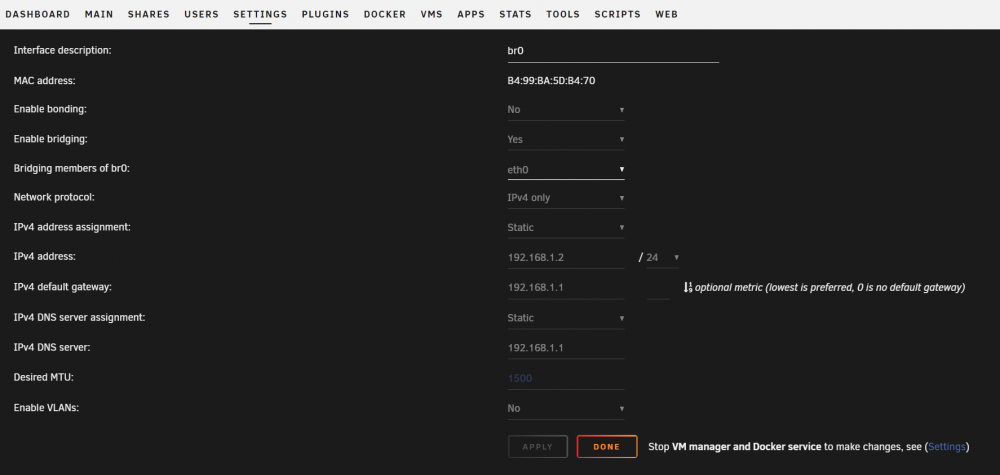
now, changed my append on regular boot, removed isolcpu and stubs as they where managed through unraid meanwhile anyway, rebooted
-> all working again
just the isolcpu was gone, probably due i setted it up through appnd only
changed now isolcpu in GUI to get back as before, rebooted
-> looking all good again now
closing now my external ports again for webgui and ssh usage
but honestly, i cant understand why its working again like this ...
this was my append line before (like the last 1 - 2 years ...)
append pci-stub.ids=10de:1b81,10de:10f0,10de:1d01,10de:0fb8,8086:a2af,1106:3483 pcie_acs_override=downstream isolcpus=2,3,4,5,8,9,10,11 kvm-intel.nested=1 initrd=/bzroot mitigations=off
-
well, cant imagine its a config thing as it stopped working while running ...
i mean its all working besides the system (unraid host on 192.168.1.2) is not accepting connections from LAN, ONLY from external ... which is a bit weird to me ...
also all other connections in the bridge are working, all dockers now (i changed the mysql docker to its own ip) and now the dependant dockers like nextcloud and guacamole are also up and running, all VM's are fine, all connections in LAN from VM's, Dockers, other devices are all fine ...
so like a firewall blocking unraid host from internal access, no http, no smb, no ...
so, when i boot in safe mode, what should i look for ? debug what ? look for ? or just check if system is then reachable from LAN ?
-
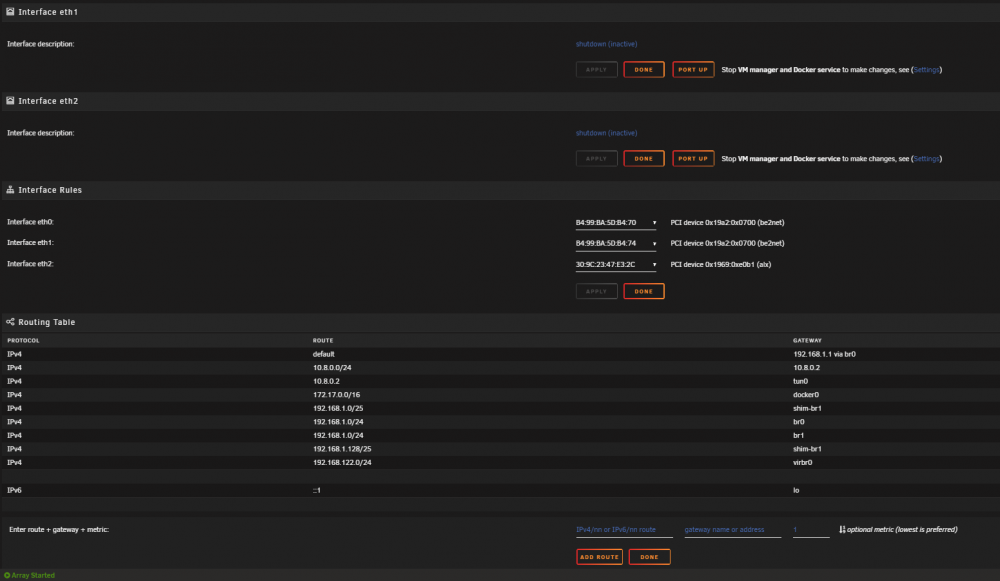
as i am at home now i made another hard reboot, power off / on.
boot sequence etc looking all good, i just cant reach my services anymore related to server ip 192.168.1.2 at all,
all services besides that are working fine.
Shares (not reachable)
dockers running on host in bridge mode like mariadb (not reachable)
webgui not reachable
VNC to a VM using unraid vnc the same, not reachable
and here also, i can forward external port to unraid server and webgui is there ...
so, i can proceed any local connection to the host server (unraid), only via external connections ...
tested from local VM running on top of unraid, also tested from laptop @home ...
may a hint what could be broken here ? no hardware changes, no changes on network config, ...
-
so overall, looks more like a network issue due my srver ip address is not available at all,
as i have almost all dockers on custom br:0 with their own ip's, thats why they are mostly working ...so, somehow local binding is not working in network ... like described
ssh to 192.168.1.2 <<-- doesnt work
ssh to ssh.mydomain.de (port 22 forwarded to 192.168.1.2) <<-- working
from the same VM in LAN running on unraid
-
attached, syslog before and after reboot now
also, i can only ssh from externally now via port forwarding, internal LAN 192.168.1.2 ... like not listening ...
dockers mostly running, not all ... the ones which are related to mysql which is running on host which is not available anymore local ...
VM's looking good
very very weird
i hope someone can help
i also added the network.cfg file, but looking good to me ...
-
ok, server did reboot, but webgui is still gone ...
oot@AlsServer:~# uptime
17:20:18 up 2 min, 1 user, load average: 8.85, 4.20, 1.58
root@AlsServer:~#
-
tried it all, stopped libvirt service fine, just docker service is ...
/sbin/reboot ... lets see what happens
and thanks for the tipp with unmount ... you prolly right
but was too fast now
-
and it looks now its completely stalled ... cant even reboot via ssh, so i have to hard reboot when im at home
seems docker service is blocking from reboot
also stalls when i do
/etc/rc.d/rc.docker stopso i guess docker service is borked
i can tell when im at home, if you have anymore ideas what todo via ssh ... i ll try













[6.9.x - 6.11.x] intel i915 module causing system hangs with no report in syslog (not alder lake)
-
-
-
-
-
in Prereleases
Posted
still can confirm this as my "old" mashine is still in use on my friends place (im maintaining it), never crashes ...
transcoding is done in plex and tvheadend sometimes, even a gvt-g VM is perm running