

alturismo
-
Posts
6101 -
Joined
-
Last visited
-
Days Won
47
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Report Comments posted by alturismo
-
-
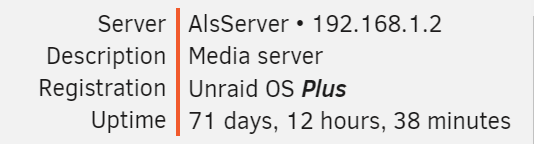
Hi, issue here on 6.9 30 Beta, webui not accessible anymore since somewhen today ...
root@AlsServer:~# uptime 15:56:46 up 8 days, 9:04, 1 user, load average: 16.96, 16.27, 15.04pretty much since the release of the .30 beta, worked like a charm since today
")
before i try to restart nginx (would be nice to have a proper way todo so on unraid) i try to fetch some diagnostics,
bus seems like i have no luck with that ...
root@AlsServer:~# diagnostics Starting diagnostics collection...Resting there forever ...
VM's, Dockers, Shares, ... all seem to work fine, only webui is not working anymore
may some hints howto "safe" restart nginx on unraid ? thanks ahead
-
same here, 6.9 beta25 is stable and no real issues ... besides my docker size point which i couldnt figure out yet ... but thats prolly not beta related.
-
 1
1
-
-
Hi, seems i have a issue now when trying to move my VM's from UAD to a 2nd cache pool.
my libvrt service fails to start after shutting down the VM system and trying to restart it.
made a reboot now with the same result.
any chance to "repair" or only solution, wipe the img file and redo VM's with existing vdisks and hope i match the settings
### EDIT, sorry, my fault, just saw i made a wrong path for default VM's ...
logs and diags attached
-
g morning, after updating to .25 following in the buttom line
Array Started•Warning: file_get_contents(/sys/block/ROOTFS/queue/rotational): failed to open stream: No such file or directory in /usr/local/emhttp/plugins/unassigned.devices/include/lib.php on line 635
all looking good (also UAD), just this error line came up
logs attached
alsserver-syslog-20200713-0429.zipalsserver-diagnostics-20200713-0631.zip
-
may also still open here, exit in webterminal does reopen a new session instead closing it, 99 of 100 at least ...
some small glitches i "feel", hitting stop on my win10 vm's doesnt stop them anymore, i have to either remote login and shutdown or use virsh shutdown ...
-
hi, may someone else came accross stopping the array and it hangs
i tried to install a macinabox install for some purpose, so docker created etc ...
now, when i hit stop array, mashine stays very long at

looks like unmounting a UD disk takes very long, also UD shares etc, log attached
-
6 hours ago, limetech said:
You should just be able to Edit VM and click Update.
if its meant to just update something and then its changed in the background, ok, that seemed to work.
-
ok, seems i was too fast, i guess its another issue why this happens
when i read changelog again
webgui: VMs: change default network model to virtio-net
this virtio-net does not exist here, i only have those
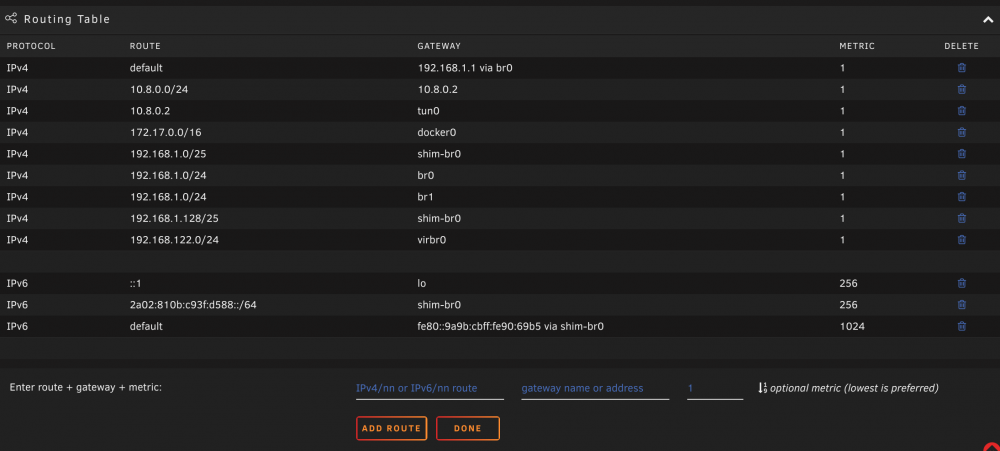
so i have chosen the virbr0 which is 192.168.122.0/24, whatever this is about cause i never added it.
so, how can i add this virtio-net to unraid ?
as note, when i add a new vm i also dont have the option, its still default to br0 and i can choose from br0, br1 or virbr0 only.
-
may another question about VM and virtio network, i see this correct that they have to be on their own subnet ?
its weird here now due my vm's are on 192.168.122.x while my regular net is 192.168.1.x
i never added or changed anything on virtio, so its default i guess.
is this a must have ? cause i guess i ll run into issues when i try to rdp to my VM from non unraid mashines.
### Update, confirmed, i cant reach any win10 vm from either guac or laptop in LAN Network 192.168.1.x .... so, this is still open when i read correctly that the kernel errors appear when using the same network as dockers do ?
-
may some questions before trying the beta
i currently use
1 cache drive (nvme 1tb) xfs formatted
1 UD device where my VM's sit, nvme 500gb xfs formatted
4 drives in array all xfs formatted
when i now upgrade, does this collide with the current setup ? do cache drives have to be btrfs or am i still good to go ? reason why xfs, my cache drive was btrfs before and crashed 2x completely with complete data loss ... since xfs im good. when i read correctly this should still be fine as single drive pool.
Next would be, change my current UD drive to cache2 (sep single drive cache pool for my VM's), also possible as its a seperated pool with single formatted xfs drive ?
or rather keep it UD
VM's need network change so the kernel error would be gone, when changing this (webui) also probably all manual changes still gone or are they persistent now ? (sample cpu pinning)
VFiO PCIe config should be obsolete then when using the new setting feature, uninstall plugin before update or doesnt matter ?
last for now, new kernel fixes nested virt ? ... win 10 wsl2 subsystem activation lets VM crash badly, any changes done there in webui or still same procedure to activate ?
for some notes thanks ahead
-
thanks for the info, reverting to be safe for now.
-
ok, thanks for the info, so no workaround to get the VM´s use another custom br ... to bypass this behaviour
-
installed over 683, so far looking ok for unraid.
my main win10 VM aint booting anymore (blue screen, diagnostic, start issues ...) but i guess its just bad luck cause the 2nd win10 vm boot just fine ... so i guess its not 69 beta related
also the ubuntu mashine spins up fine.
so i look to check if i can repair the win10 vm somehow
-
besides the already mentioned "status" cosmetic thing i had a issue while upgrading from rc4 to rc5, system stalled on reboot and screen was here.
First time i had something like this ...
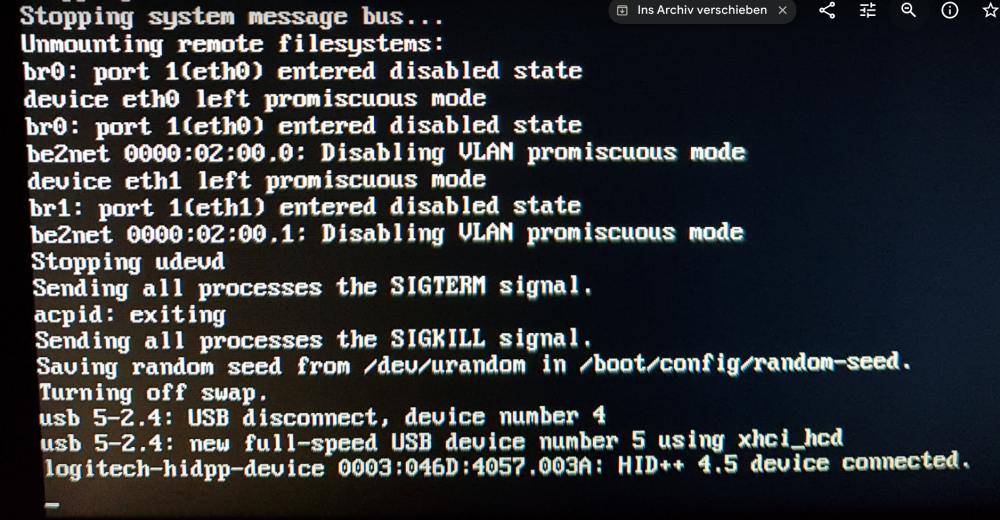
i waited a while and then hard rebooted, all good after reboot
-
11 hours ago, ljm42 said:
Thanks for the fix @bluemonster !
Here is a bash file that will automatically implement the fix in 6.7.2 (and probably earlier, although I'm not sure how much earlier):
https://gist.github.com/ljm42/74800562e59639f0fe1b8d9c317e07abIt is meant to be run using the User Scripts plugin, although that isn't required.
Note that you need to re-run the script after every reboot.
Remember to uninstall the script after you upgrade to Unraid 6.8
More details in the script comments.
also thanks from here to @bluemonster for the fix and @ljm42 for the script
-
ok, happened again today
i was testing some http api commands for tvheadend and one command stalled ... after that there was no more repsond, also could not quit the command at all, even a tvheadend restart (to definately kill the http connection) also didnt help, just as note.
/etc/rc.d/rc.nginx restart <- worked then well here
-
8 hours ago, limetech said:
Finally had this happen on a test server. I could not find any reason why the ttyd daemon quit responding to connection requests. Probably this is a bug in ttyd or libwebsockets it depends on. We have updated the latter in the next release and let's see if this happens again.
To recover from this you can use telnet/ssh/console and type this command:
/etc/rc.d/rc.nginx restartthanks for the Tipp
-
when i killall ttyd instances i then get a bad gateway instead about:blank when trying terminal again
i assume ttyd need a restart, may a hint wich options to use ?
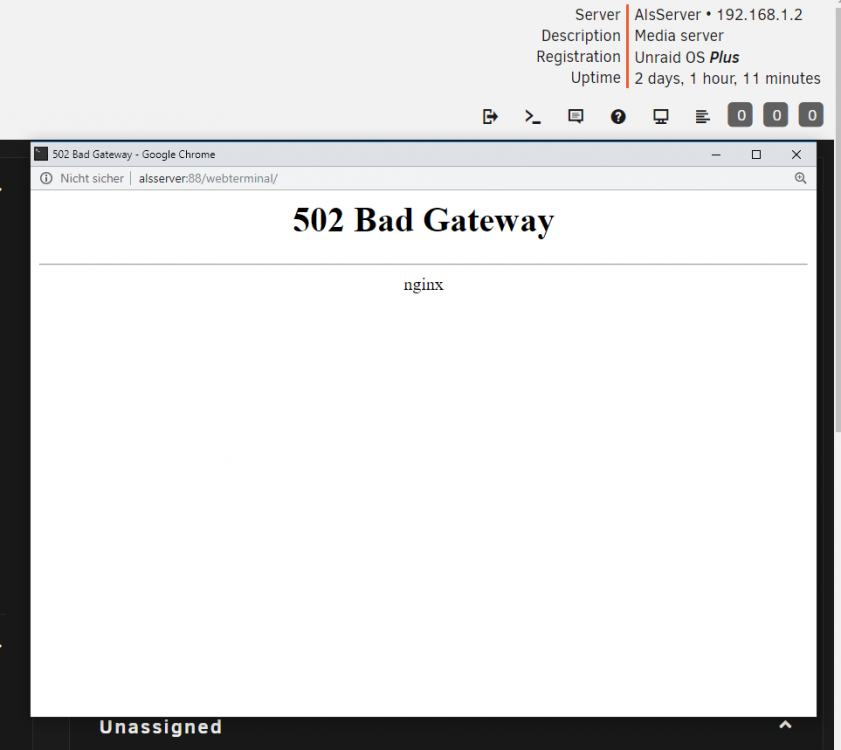
-
g morning, just as quick test today morning i see it happened again, as note ...
command was ps x
the last entry from system log
Mar 1 07:01:42 AlsServer login[12318]: ROOT LOGIN on '/dev/pts/2'
is there no option to restart the service ? exept server reboot ?
-
@limetech anything i could try via cli etc ? otherwise i would take a reboot to get webterminal up again
-
Hi, everything just works as normal, only webterminal is dead.
anything i can do ? its still all open
-
ok, happened again now, i have the webterminal windows open where it "stalled", i opened a new window to see what happens and its the same behavior, about:blank ....
happened in the middle of typing, not even executed anything ...
heres a screenshot and diags attached
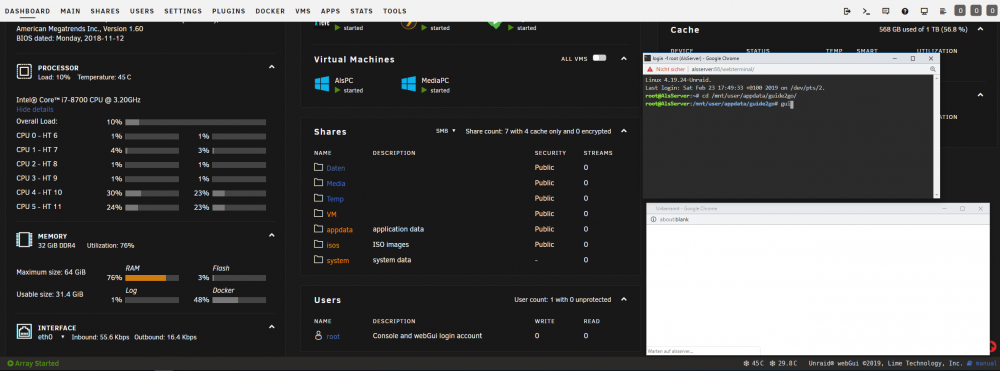
now, what to look for or what diags could be helpful, i keep all open for now ...
-
i did ... happened 3 days ago, i ll next time.
i checked syslog, no entry, i checked cpu loads, seemed fine, i checked ssh, was all good.
thats why i didnt made a diag, next time i will.
-
@Taddeusz now or when it happens again ?









Unraid OS version 6.9.0-beta30 available
-
-
-
-
-
in Prereleases
Posted
cat didnt work out, always "no such file .." on target
cat /var/log/syslog /boot/syslog.txt
....
Oct 15 16:50:05 AlsServer sshd[8312]: Starting session: shell on pts/0 for root from 88.73.177.160 port 47984 id 0
cat: /mnt/user/appdata/syslog.txt: No such file or directory
root@AlsServer:~#
i copied the syslog file now to be sure")