




dmoney517
Members
-
Joined
-
Last visited
Everything posted by dmoney517
-
When I try to mount a share from my PC in the unassigned devices plugin, It fails every time. I am able to find my PC, enter my credentials, load the shares and select c$. But when I try to Mount it by clicking the button, it errors out and directs me to the Syslog. The syslog is only throwing a -13 error, which google says is auth related. But my understanding is that if my auth was incorrect (which I know 100% it is not), I would not even be able to get as far as this. It wouldnt load the shares (i tested with a purposely incorrect password). What am I missing? I have SMB and SMB1 turned on in my Windows. The strange part is, I had this setup and working previosuly. Im not sure when the share was "dropped" from unraid (I havent had to use it in a long time). But now that I am trying to set it up again, it wont work.
-
Got it! Thank you!!
-
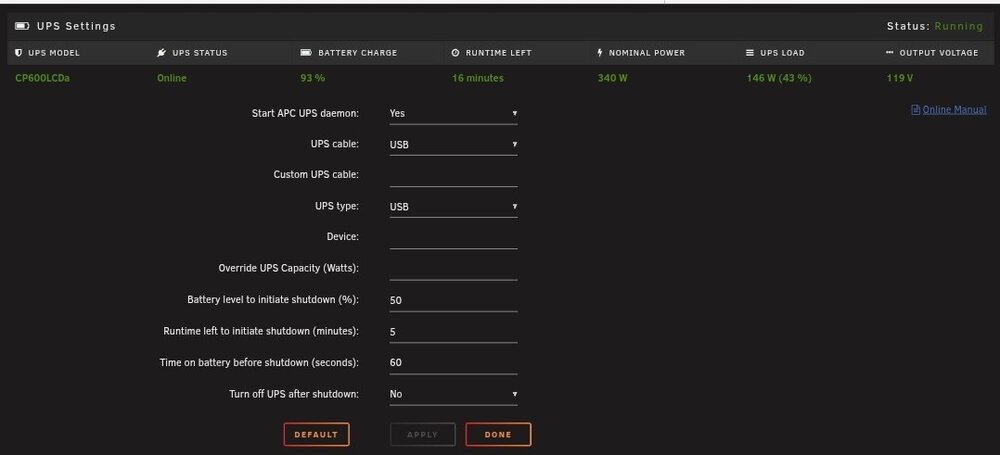
I have updated to these settings now... I want it to shut down within 1-2 minutes of being on battery.
-
That's what I want...I want it to run for a minute. So I need to change the parameters you have shown to be 60? I don't want it to run indefinitely, but I know it's have it configured wrong. You said not to have it set to 10%...what should I set it to.
-
Can someone help me understand why my UPS does not work? All I want is for it to go to graceful shutdown if there is a power outage. I am running parity check when the below screen shot is taken. I feel like I should have enough juice to make it through a power blip, but i don't. Example - just today we had thunderstorms. I did not lose power, but the lights dimmed once and came back immediately. But the server had an unclean shutdown. This happens every time, the UPS doesn't seem to do anything. My expectation would be that it can run the server for 5 seconds if needed, and if it goes much longer, to do a graceful shut down. Can anyone look at my setup and let me know if I need to do anything different?
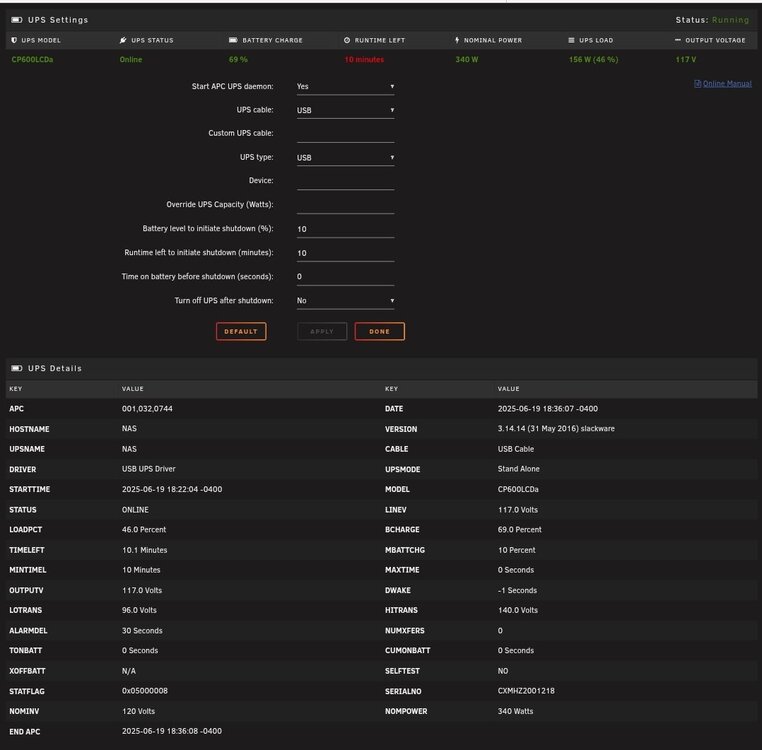
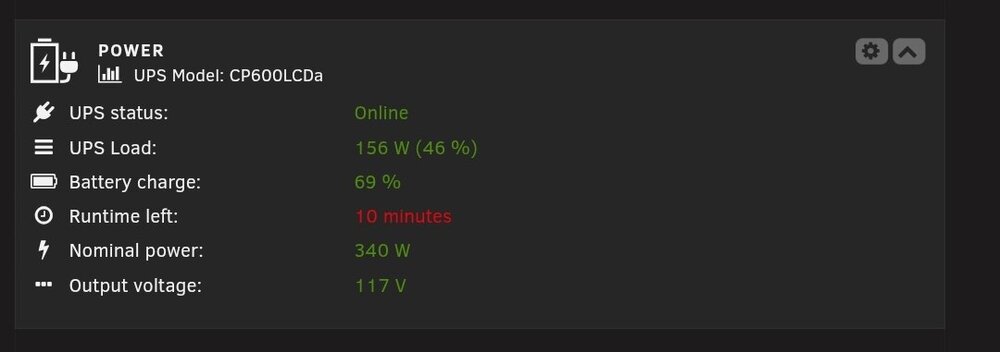
-
Thanks. I was a bit nervous to try an rc release, but it is working perfectly after being upgraded about 8 hours ago. No network issues and everything else is working as expected.
-
I just upgraded from 6.12.13 to 7.1.3. I noticed the external internet connection not long later when I tried to lookup a new docker in CA and they wouldn't load. I downgraded back to 6.12.13, then upgraded to 7.1.2. The internet issue is still present. Everyhting works for about 5 minutes then drops. Is there a more stable version of 7 I should use? Or should I stay on 6.12.13 until 7.1.4 is released?
-
My unraid server has started crashing every other day / every day for the last week. At first I thought it was due to running Tdarr around the clock, but I shut those dockers down and it still crashed at some point this afternoon when i was at work. I have started mirroring syslog to flash, and I cannot find anything in it to point to the reason for the crash. Syslog attached here, as well as a diagnostics that I pulled when I just turned the server back on. The oddest part is before this, I had about 20+ days of no issues and up time. My Parity check ran on the 1st of May overnight, and shortly after it finished the server crashed. I thought it was due to parity + Tdarr running. So I started things back up, crashed again. after a few more daily crashes, I shut down Tdarr (even though it was running all last month constantly transcoding with 20+ days of no issues). I would appreciate if anyone can point me to the reason for this!syslog-previous nas-diagnostics-20240509-1958.zip syslog-previous.log
-
New update....it looks like this is occurring for me with ANY browser page left open. I like to leave my main up, but I am noticing sometimes I come back and see my logs full of this. I have also woken up to my server being off. Seems these logs are filling to the point it crashes the server. Hopefully this is resolved in a future version.
-
Thanks! I started up and ran a parity check just to test all the drives. Ran perfectly, and finished my parity check about 1.5 hours faster than my old HBA. So I'll take it!
-
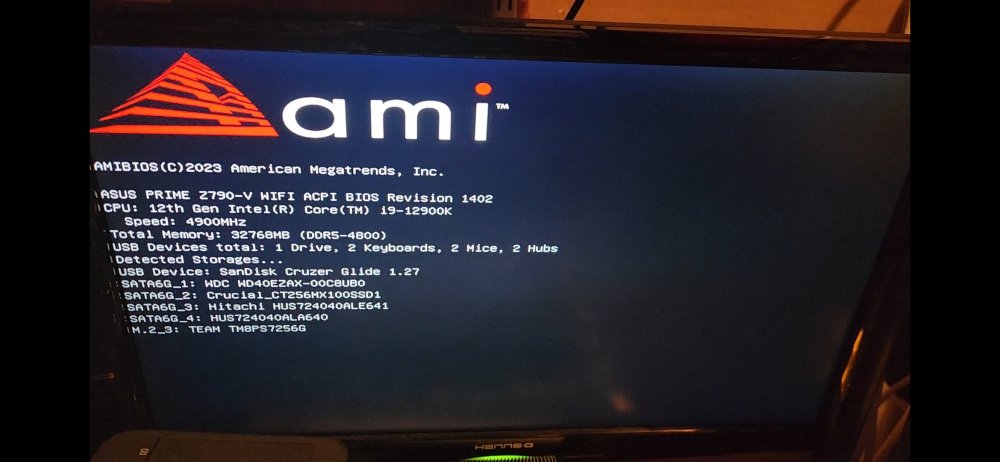
I just changed my HBA from 9201-81 to 9207-8i PCIex3. Needed for various reasons. Anyway, with the old HBA, all of the drives would populate and show on the BIOS splash screen during boot. With the new HBA, they are not. Only the USB, M.2 and 4 on board SATA drives are showing. Once Unraid boots, all drives are present. Is this OK? Diags attached, and a pic of the splash screen. nas-diagnostics-20240407-1005.zip
-
Thanks. It finished overnight. Everything looks in order. Diags attached. My assumption is that the port on my second HBA is went bad? Both DSBL disks were on the same SFF-8087 breakout. I moved that cable to an open port on my other HBA (running 2 9201-8i, but only using 3/4 ports) when one of the disks stopped being read and it came back? I replaced one of my 2.5 SSDs with an M2 during this build (unplanned, I broke it while pulling cables), so I could technically consolidate at this point down to 1 HBA (8 drives) and the 4 on board sata ports and that would cover all my current drives. Should I do this assuming the entire HBA is bad? Or is it possible to have 1 bad port on the HBA? Also debating returning both of them (bought at the same time, still in return window until May) and getting a new HBA all together from a different seller. As always, greatly appreciate your advice and help! Last set of diagnostics attached! nas-diagnostics-20240403-0717.zip
-
I moved cables and the missing disk is back again, albeit in DSBL mode still (obviously). I have intitiated rebuild of both drives. Attaching diags again. Can you please take a look 1 more time to ensure everything is looking as it should? Appreciate all of your help! nas-diagnostics-20240402-1620.zip
-
I rebooted the server, and now Parity Disk 1 is not showing at all. Ugh. I thought I was passed all of this.
-
Thanks...what about the Parity? Should I rebuild both? Or rebuild disk 4 first then parity?
-
Here they are... nas-diagnostics-20240402-0906.zip
-
Cli reboot worked. New diagnostics attached. nas-diagnostics-20240402-0852.zip
-
It wont let me cancel when I click the button. Nothing changes on the screen. 20 minutes after I tried, this just popped up in the log. Not sure if its related. Apr 2 07:46:34 NAS nginx: 2024/04/02 07:46:34 [error] 22158#22158: *4835131 upstream timed out (110: Connection timed out) while reading response header from upstream, client: 192.168.0.105, server: , request: "POST /update.htm HTTP/1.1", upstream: "http://unix:/var/run/emhttpd.socket/update.htm", host: "192.168.0.108", referrer: "http://192.168.0.108/Main"
-
I am not able to Cancel the current Parity Check. When I click cancel / OK, the Parity check dialogue does not go away and STOP Array is still greyed out.
-
Scheduled Parity kicked off laat night 10pm. My health check ran last night 12:20am, no problems. 2:10am 1 of my parity disks and a data disk went to DSBL. 3 am Scheduled Prity Check Paused so Mover could run, then resumed as it should at 3:21am when mover finished. I've been awake for 15 minutes and the parity check has not moved. Stuck at 74.7%, and claiming it is moving at 99MB/s. Any thoughts on if I need to replace? What is my best path forward to fix both disks? I do have 2 disks in unassigned devices on standby, precleared and ready. Diagnostics attached nas-diagnostics-20240402-0644.zip
-
Ok. Not sure what happened with /mnt/user/flash, but I was assuming whenever I connected to \\NAS\flash over SMB from my windows desktop, it was connecting to /mnt/user/flash. But I just went into /mnt/user/flash in the terminal and it is basically empty. so Unraid is sharing the /boot drive over \\NAS\flash by default I guess? Either way, Thanks for the help! I have moved that "share" to a new name and my Fix common problems is now clean. Appreciate the help!
-
Interesting. Glad I found this thread. I just did a server rebuild and upgraded from 6.9.2 to 6.12.8. I thought I was running smooth, then woke up to this. Looked at my phone and saw i left a tab open on Dashboard. Kind of annoying, but glad it isnt anything wrong with the server/build.
-
Ok...If I navigate to the /mnt/user/flash folder, it is the contents of my Flash drive. Should I do the rename procedure? Is it "safe" to rename directory since it is the Flash drive? cd /mnt/user mv flash flash-drive Thanks for the help!
-
I just moved from 6.9.2 to 6.12.8 and am now seeing errors related to flash drive share. However, I dont have a share named Flash. Not that I created at least - But I do see it if I go to /mnt/user - I know the guidance is to manually go to the terminal and run mv flash new-flash to rename it, but I want to confirm this before doing so as I never created this share, it was shipped this way when I initially built my server several years ago.

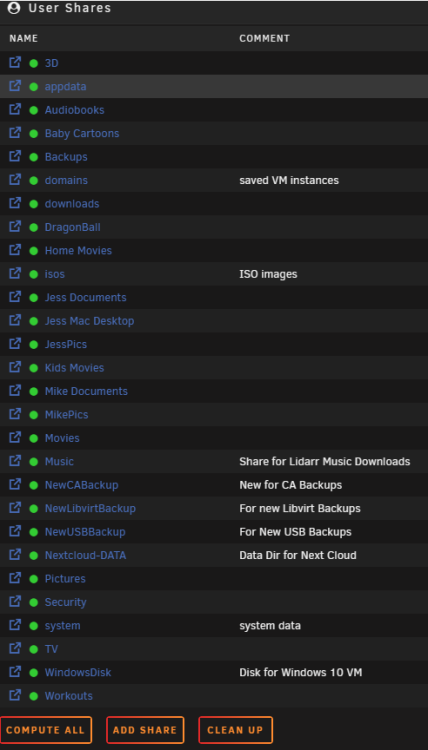
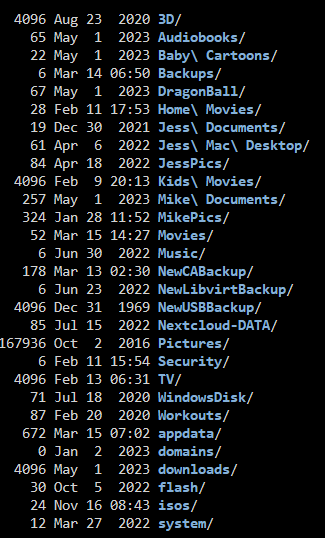
-
I decieded to just let it rip. No issues going from 6.9.2 to 6.12.8.








