




Jerky_san
Members
-
Joined
Everything posted by Jerky_san
-
I hope to see it one day as well.. I'm running out of space and I'd rather add another shelf then have an unraid pool span two shelves(which seems ripe for problems). I have 24 drive bay cases so I'm maxed out at 22+2 parity. I looked at buying a 36 bay but it doesn't seem worth it either given how expensive they've gotten and much harder to quiet/cool. Being able to have multiple unraid pools though would simplify everything and make it where perhaps you could even fully spin down one and maybe have an active one and an archive one or something.
-
I changed to host and removed multi home and playing now.. They also posted a quick fix in the github but we can't do that one I don't believe.
-
I'm getting the same error about API people on the subreddit are speculating it's because they added TLS and it's using a self signed cert.
-
Thank you very much.. I'll do this now.. I really appreciate you responding
-
For some reason after this second restart I am able to see all my files but I am unable to begin the rebuild of the parity and of the failed data drive. Is there a specific order I should do or something?
-
tower-diagnostics-20230314-1028.zip Here is the updated diag @JorgeB
-
It won't let me stop the array. Is there a command to make it stop cleanly or should I just use the restart button and let it timeout/force it? Also thank you very much for responding.
-
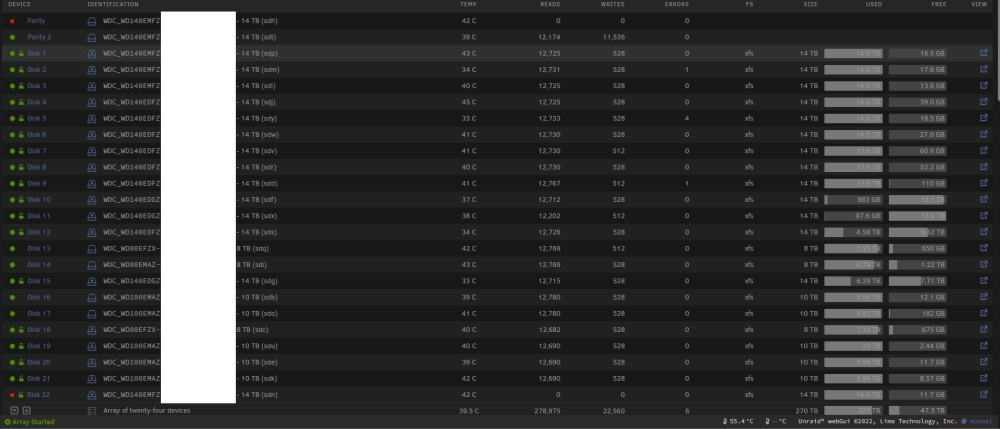
I updated my bios as I was very out of date and I was doing a general system maintenance. When my server came back up everything appeared fine like it usually does but when it booted all the drives errored. It scared me so I stopped the array and rebooted it again. It came back up and said a pairty drive and a 2nd drive were errored but that everything else was fine. I started the array and it said it started cleanly but now all my data is missing even though it shows the space used. All my drives also for some reason showed up in unassigned devices. Can anyone please help me. Am I totally screwed? tower-diagnostics-20230314-0920.zip
-
Sorry I don't know why I said blank.. HTTP challenge over port 80. Even though the port is totally accessible it seems it has trouble completing the challenges stating "Timeout during connect (likely firewall problem)". It will even fail to do the challenge on subdomains it just did a few minutes ago when adding another subdomain to the list. But if I spin up "NginxProxyManager" as a test container just to see if other containers fail. It is able to challenge via http without issue. To my knowledge when it does the HTTP challenge the server redirects to the let'sencrypt folder where the challenges are stored but for some reason it times out sometimes on one or more subdomains and succeeds on others. I almost wonder if fail to ban is kicking in because I have so many subdomains.
-
@aptalca Hey sorry to bother.. I was wondering to do an HTTP blank setup on let's encrypt does it have to have anything special set anywhere besides the standard stuff in the docker like subdomains and stuff? I had an issue trying to add a subdomain but another container would set it properly so made me think I might have something configured improperly. Though I couldn't for the life of me figure it out. The error I was getting was "Timeout during connect (likely firewall problem)”. But if I just pointed my ports to the other container HTTP worked. The other strange thing is sometimes it would work for a subdomain and other times it wouldn't after just a restart. I assume it's something I'm doing but just wondering if you heard of this ever happening. I ended up doing a DNS challenge and it all worked fine. Thanks for any insights Edit Should also mention I only use cloudflare for my DNS now and no longer use it as a pass through so it shouldn't be that to my knowledge. Also the other container shouldn't of worked if that was the case. I have 6-7 subdomains.
-
Slightly off top topic but @Dyonany chance you could make a wireguard docker container for SABnzbd?
-
Figured it out.. Had an old docker that also had 8080 allocated(thought it was set to stay stopped) but it wasn't and it was starting before qbit was. Btw so far the experience has been much better than deluge. Downloads are much faster so thanks a lot for putting out a wireguard docker.
-
Installed it to try. After restarting though it showed it wasn't running even though the log showed it was. Attempting to start or the service even after disabling docker and re-enabling shows "server error" very strange..
-
Welcome have fun
-
If QEMU/KVM works anything like VMWare the switching should basically go as fast as the system will allow it to process. The odd thing with yours is it's only one direction having an issue. I guess I could suggest you try disabling flow control/nic offloading in "Tipsandtweaks" (an app you must first get from the app place) and see if that does anything for you. Honestly though I don't know if will give you any benefit. Also if you've not go download the latest virtio iso and install the latest drivers.
-
Also found this guide https://www.target-bravo.com/blog/2018/7/10/blog-headline-1-6y3tj-49m5s-7tbal-56sar
-
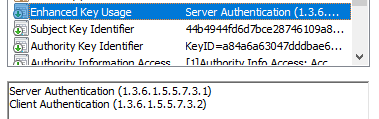
In the chrome address bar if it shows the lock at all click it go to view certificate, details, and look for "enhanced key usage" and see what it says if it will let you. Below is an example of what it should say.
-
Does it do it in IE and Firefox? Also I believe maybe you have the key type wrong perhaps? Not 100% on that as I've never personally got that error but I believe it could be like you have it set as client auth instead of server or something like that.
-
Hmm I assume you could probably go to the file and try to fix whatever is wrong on line 39 of emhttp-servers.conf but might just try restarting. I'm unsure on how to proceed on that one as I assume it won't save whatever you change on reboot.
-
I believe you just say /etc/rc.d/rc.nginx restart without the ./nginx.conf. At least scripts I've seen that automatically import ssl certs for unraid don't ever have the ./nginx.conf on it.
-
@srfnmnk Just to ask did you restart your server or the nginx process after you added your certs?
-
Oh sorry for misunderstanding. Searching for the fix.
-
This may help but not 100% sure as I've never used my own. nginx certificate handling details The nginx startup script looks for a SSL certificate on the USB boot flash in this order: config/ssl/certs/certificate_bundle.pem config/ssl/certs/<server-name>_unraid_bundle.pem If neither file exists, a self-signed SSL certificate is automatically created and stored in config/ssl/certs/<server-name>_unraid_bundle.pem Provisioning a Let's Encrypt certificate writes the certificate to config/ssl/certs/certificate_bundle.pem nginx stapling support Whether nginx enables OCSP Staping is determined by which certificate is in use: config/ssl/certs/certificate_bundle.pem => Yes config/ssl/certs/<server-name>_unraid_bundle.pem => No
-
This morning it appears it didn't do. So perhaps it really is connected to the cron job? It renewed the night before but still went down. Last night it simply said "Cert not yet due for renewal" and everything is running this morning. Very strange..
-
That I see no.. just says "server ready" until I restart it. Ports go completely down but the docker itself is still running. Error logs do not show anything either but it was able to renew the cert last night so it must of went down after that happened.


