




LSL1337
Members
-
Joined
-
Last visited
Everything posted by LSL1337
-
wow, great. thanks! I want to copy the file daily. Is there a command in can run, to reset this log every day after a copied it? so a copy a file.activity_DATE.log file, and after that, reset the file with a command
-
it worked with the ., but it was in 1 line in the web terminal. I removed the dot and the extra line, now it seems to be working. thanks! I didn't know the different line makes a difference even, it was just more readable for me
-
I have a VERY basic find+cp script, which works in the web command line, but doesn't, when I want to run it with custom scripts (I just tried it manually) Any ideas? #!/bin/bash find /mnt/user/mini/myfolder/ . -iname '*.mkv' -exec cp -n {} /mnt/user/mini/myfolder \; When I click Run Script, I get the find results, and "find: './sys/kernel/slab': Input/output error" And the cp can't start with this error in the find 'results'. What am I doing wrong? Btw i just try to copy files from the subfolders to the main folder. the subfolders will be deleted by the DL client, when seeding is done.
-
Guess when i clicked the button

-
GOD TIER
-
I'm still speechless. Thanks very much. Is there a way to get advanced view without this extra side effect? whatever, i can always toggle it off.
-
are you f'in kidding me? @ich777 it works why does it have any impact even, and why is it ok for a few days after boot? is this a bug, or a feature? and it has impact, when the ui is not even open I can't even find the words... how many people does this impact btw? @INTEL check the previous post
-
6.8.3 normal. i have a 7700T, no dGPU @ich777
-
still nothing, I've given up. What dockers do you run, what motherboard do you have, cpu etc. maybe we can pinpoint something
-
I'm running 2 Tautulli official dockers on my unraid server. (for 2 plex servers) first is on 8181, second is on 8182. I'm getting tired of something automatically misconfiguring it periodically (I guess after an update). First of all, I can't configure the second instance to use 8181 and I'm not sure how did I change it to 8182 anyway. I don't remember that field being blank months/years ago. So i guess when there is an auto docker update for tautulli, my 8182:8182 port forward setting gets overwritten to 8181:8181, which ofc means the second instance can't start. Any idea how to solve this issue? Can I configure the second container even to run on the same port? and map the second instance to 8181:8182? thanks
-
I changed back my cache drive from encrypted xfs back to xfs, but the issue still persist. I can't be the only one with this issue...
-
first of all, thanks for the reply. second: if the baseline would be 15%, i wouldn't care about it, but it is less than 5% (has been for years, without plex transcoding), so the system is doing something, which it shouldn't/ didn't before. based on htop, it might have something to do with containered.toml, which could indicate possible drive usage. this is a 1 line txt file. if it has 10% cpu usage, that would mean something is very wrong... i stopped my containers one by one, and the cpu usage decreased proportionally, which means it's not a single docker which causes the issue, it could be with the docker engine itself. Diagnostics attached lsl-nas-diagnostics-20200527-1300.zip
-
So am I the only one with this issue, and noone has any idea. This is not github on an open source free loveproject. This is a paid software, right?
-
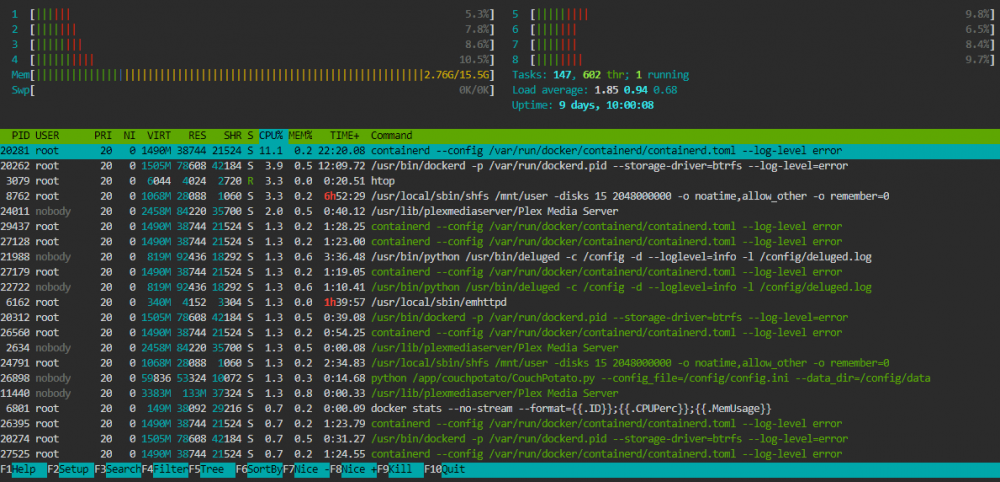
After a few days of running, I can see in the stats window, that my cpu usage is 15%, compared to the normal 4-5% constantly (if nothing else is running, on a daily, weekly stats chart) If I restart docker, it doesn't solve it (In settings, docker enable No, than back to yes) If I restart the server, I think it solves it sometimes, for a few days, than it starts again. I think it started around the time, when I changed some docker log settings or after i switch my cache to encrypted xfs It starts to bother me now, cos if this writes to SSD so much log constantly, that it takes up 10% CPU, it will just kill my SSD in a few months (Or var/run/ is all in RAM?) my docker.img is less than 50%, log is 1% in the dashboard. If I run a htop, I get the following results: My cache drive is now XFS encrypted for a few months, i though it would solve this occasional btrfs csum error. I was wrong, as the docker img is still btrfs... Any ideas? Thank you!
-
is the log, which is shown in the UI, available as a text file in some folder maybe? Can this be written to file periodically? daily for example? I might try to load it into DB, so I can better analyse it, and optimize some jobs, so i can group the disk spin up/down activities better maybe
-
The day has come for nvme temp error. in the auto fan speed plug-in I updated, tested it, it works Thank you! 2020.04.11 fixed NMVE exclusion (courtesy of Leoyzen) ps: "added multi fan selection" i'm not sure what is this, and how does it work? Multiple fans can be set to the HDD tems, or even other temps. The UI is the same, how can I configure this?
-
anyone else have a problem with cpu usage? I have a 7700T, and after every weekly sheduled job (sunday morning), when my docker appdata is backed up, deluge docker always starts with "high" cpu usage. idle my server is around 2% cpu, when nothing happens. after the restart it is a constant 8%. after i manually restart deluge, it goes back to 2%. if i don't touch my server, it will stay at 8% baseline for the whole week. i THINK it was the deluge-web process, last time i checked with 'top'. anyone else has this weired issue, that deluge-web cpu usage spikes on 1 thread after auto backup? (im on the last 1.3 build, before the 2.0 beta) I'm starting to get tired of this, any idea? or an idea where should i start? thanks
-
you are right, but I don't think there is anyone who manages the plug-in anymore. and the problem with the plug-in is that it can't ignore nvme drives, so the 2nd part of what you wrote is impossible/doesn't work. I downgraded to the previous version (without nvme support), but it didn't work on 6.7.0 the github for it is abandoned. If I could fix it, I would
-
It should be, but it doesn't work. it was reported months ago by several users, the developer did **** all about it. it seems like such and easy thing to do....
-
same boat. older versions didn't have nvme support, so i guess it would solve the problem. any way to downgrade to the older version of the plug-in?
-
maybe try 'nct6775' sensor. It works for my b250 intel board. auto detect didn't work for me either
-
multiple people reported this nvme temp issue, no response. Seems like it would be an easy fix, but i guess noone cares. The plug-in could even ignore nvme drives by defalt, cos they aren't really cooled by FANs anyway.
-
Is it Possible to install a previous version of AutoFan, before it had 'nvme support'? It just broke the functionality basicly for every nvme user
-
Marbles: On linux you have access via the webUI only. The webUI doesn't have RSS features implemented yet (I wouldn't hold my breath, it was requested years ago, the devs gave a maybe later answer, but ofc it's not up to the LS.io guys). If you want RSS on unraid, you should use deluge (it's awesome), or give flexget a try, but that's a whole different world.
-
Hi. I'm on 6.6.7, latest plug-in. Auto Fan doesn't exclude my cache drive. It used to work, anyone else has this issue? Now my fan speed is always based on my "hot" nvme ssd. tried restart, disable reanable, tick untick, etc. still. My highest temp (in the log) is always my nvme ssd temp any ides? thanks! edit: I see other people have the same exact problem. On my previous server build, I did not have nvme cache, and it did work as advertised. It excluded my sata ssd cache drive. I guess the nvme support is not great atm. (I also have an unassigned drive, but it's 2,5", always spun down and its cooler then my array hdd's, so I don't think this is the issue) Hopefully it will be fixed later.



