snowmirage
Members
-
Joined
-
Last visited
Everything posted by snowmirage
-
Anyone else having either of these issues? 1) Display problems in certain apps. I'm not expecting to do anything complicated in this VM. Frankly I just need to access find my devices. install went fine for the most part. But if I open safari and try to browse the web much at all pages fail to load. Well I should say they seem to load fine then disappear. Example did a basic google search I saw the results for a split second then I just see this blank screen in the browser. Similar issue when I installed parsec. I can open the app but nothing in the page renders. 2) Every time the vm boots, it sits on this screen until I hit enter to select the macos disc.
-
Got ya... Well since those drives were all very old anyway. I removed the old cache_ssd pool and created a new one with 2 new 1TB SSDs. Now that its back up with the new pool I guess I just need to edit my share "logic" to include the new ssd_cache pool where I desire it. Then I'll let it run a bit to see if any more issues come up. Its using the same controller + cables + power cables as before, so if it was a drive it should be fixed. If it is a power cable or such I would expect to see the same issue. *fingers crossed*
-
Oh my! I assume by "single profile" you mean I was not using btfs version of Raid1 or higher. So I had no redundancy... How did I do that I could have sworn this was setup with at least one spare drive guess I'm wrong. My only option then I guess is to create a new pool. Trying to do that via the GUI I don't see a way to remove the old cache_ssd pool though how can I do that after I remove all the disks and create the new pool?
-
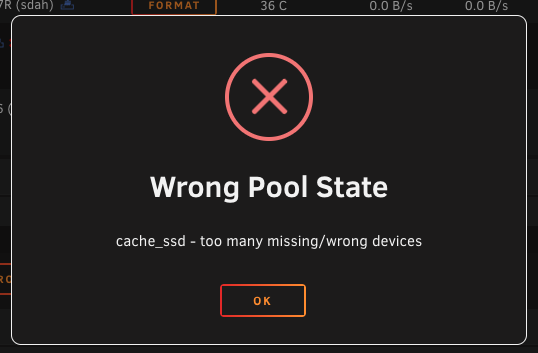
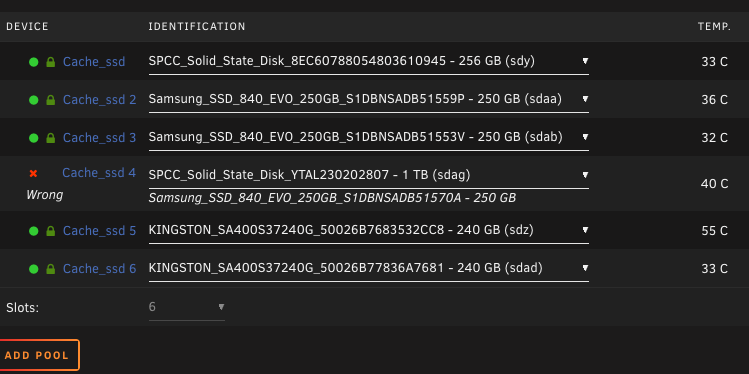
I pulled that drive suspecting it has failed they are old ssds at this point. I was able to replace it with a new larger SSD and I can insert that into the cache pool But when I try to start the array I get an error about the pool. Could have sworn when I did this a few years back it prompted me to format the disk and then rebuild the array.
-
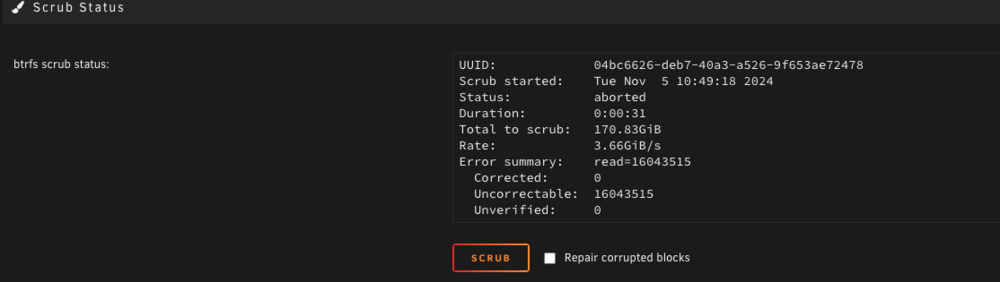
I was able to start the scrub but it quickly aborted Is there one specific drive that is causing an issue? Other than the Hitachi HDD that is unassigned, I need to just remove that after the next reboot I was just testing that drive a while ago. phoenix-diagnostics-20241105-1051.zip
-
Finally got back to this today. Did a clean reboot and started array then grabbed this diag Thank you for the help it is greatly appreciated. phoenix-diagnostics-20241105-1033.zip
-
Had this error popup today, systems been working fine for many months. I noticed I may have an ssd failing maybe thats the cause? Nothing else I see stood out to me yet. phoenix-diagnostics-20241014-1538.zip
-
Never noticed that tiny text oops Here it is nut-debug-20240319083604.zip
-
I recently made changes to my Unraid system to use the "new" cache pool options. Creating one for an NVME drive to put docker and VMs on and a second a pool of SSDs for the array. I noticed this error this morning. I'm guessing I setup something wrong with those cache pools? phoenix-diagnostics-20240319-0834.zip

-
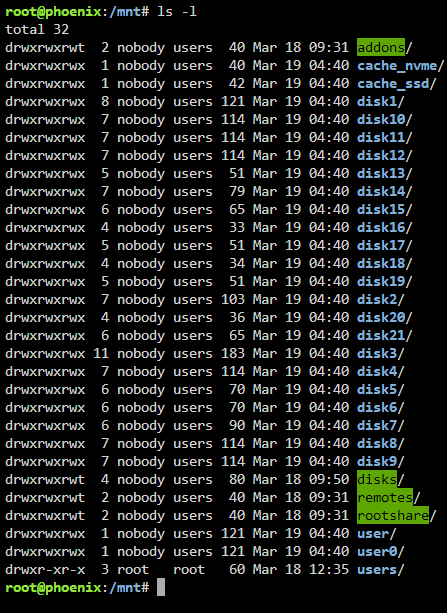
I've had the wireguard vpn built into unraid running for a while but haven't needed it in months. At some point, probably after an update of the Unraid OS if I had to guess. It stopped working. I assumed I probably busted something in the process of moving from the onboard NIC to a new 10gig interface I installed, so I set out to set up the VPN again from scratch. After reading the docs and several guides I'm fairly confident I have everything setup correctly. But I don't see unraid respond to any connection requests on port 51820. Running tcpdump on my firewall I can see the traffic hit my external interface and get passed to the unraid IP, but no response. I noticed after setting things up this active/inactive switch doesn't stay "active" and noticed similar messaging on the dashboard. I initially thought that just meant "no one is connected yet". Something I noticed that may be related. Recently when I rebooted the Unraid Host I noticed on its directly connected display that when the login prompt comes up it no longer lists an IP address. It did before I migrated to my new 10Gig NIC. Additional information: I setup the 10Gig nic with a trunk port on my local switch and have several VLAN's connected directly to Unraid. My guess here is that the VPN service isn't listening on all Unraid's interfaces, or at least not the one I intend (VLAN 2 aka br2.2 10.2.0.16) I've attached the diag file. This is all I see directly in the system logs when I try to flip that "active/inactive" slider Mar 18 17:36:43 phoenix wireguard: Tunnel WireGuard-wg0 started Mar 18 17:36:43 phoenix network: update services: 1s Mar 18 17:36:45 phoenix network: reload service: nginx Mar 18 17:44:40 phoenix wireguard: Tunnel WireGuard-wg0 started Mar 18 17:44:40 phoenix network: update services: 1s Mar 18 17:44:41 phoenix network: reload service: nginx Doing some searching another post referenced "/var/log/wg-quick.log" There I found this wg-quick down wg0 wg-quick: `/etc/wireguard/wg0.conf' does not exist wg-quick up wg0 [#] ip link add wg0 type wireguard [#] wg setconf wg0 /dev/fd/63 [#] ip -4 address add 10.253.0.1 dev wg0 [#] ip link set mtu 1420 up dev wg0 [#] logger -t wireguard 'Tunnel WireGuard-wg0 started';/usr/local/emhttp/webGui/scripts/update_services [#] iptables -t nat -A POSTROUTING -s 10.253.0.0/24 -o br0 -j MASQUERADE;iptables -t nat -A POSTROUTING -s 10.253.0.0/24 -o vhost0 -j MASQUERADE wg-quick down wg0 [#] ip link delete dev wg0 [#] logger -t wireguard 'Tunnel WireGuard-wg0 stopped';/usr/local/emhttp/webGui/scripts/update_services [#] iptables -t nat -D POSTROUTING -s 10.253.0.0/24 -o br0 -j MASQUERADE;iptables -t nat -D POSTROUTING -s 10.253.0.0/24 -o vhost0 -j MASQUERADE wg-quick up wg0 [#] ip link add wg0 type wireguard [#] wg setconf wg0 /dev/fd/63 [#] ip -4 address add 10.253.0.1 dev wg0 [#] ip link set mtu 1420 up dev wg0 [#] ip -4 route add 10.253.0.2/32 dev wg0 [#] logger -t wireguard 'Tunnel WireGuard-wg0 started';/usr/local/emhttp/webGui/scripts/update_services [#] iptables -t nat -A POSTROUTING -s 10.253.0.0/24 -o br0 -j MASQUERADE;iptables -t nat -A POSTROUTING -s 10.253.0.0/24 -o vhost0 -j MASQUERADE [#] ip -4 route flush table 200 [#] ip -4 route add default via 10.253.0.1 dev wg0 table 200 [#] ip -4 route add 0.0.0.0/0 via dev br0 table 200 Error: inet address is expected rather than "dev". [#] ip link delete dev wg0 wg-quick down wg0 wg-quick: `wg0' is not a WireGuard interface wg-quick down wg0 wg-quick: `wg0' is not a WireGuard interface wg-quick down wg0 wg-quick: `wg0' is not a WireGuard interface wg-quick down wg0 wg-quick: `wg0' is not a WireGuard interface wg-quick up wg0 [#] ip link add wg0 type wireguard [#] wg setconf wg0 /dev/fd/63 [#] ip -4 address add 10.253.0.1 dev wg0 [#] ip link set mtu 1420 up dev wg0 [#] ip -4 route add 10.253.0.2/32 dev wg0 [#] logger -t wireguard 'Tunnel WireGuard-wg0 started';/usr/local/emhttp/webGui/scripts/update_services [#] iptables -t nat -A POSTROUTING -s 10.253.0.0/24 -o br0 -j MASQUERADE;iptables -t nat -A POSTROUTING -s 10.253.0.0/24 -o vhost0 -j MASQUERADE [#] ip -4 route flush table 200 [#] ip -4 route add default via 10.253.0.1 dev wg0 table 200 [#] ip -4 route add 0.0.0.0/0 via dev br0 table 200 Error: inet address is expected rather than "dev". [#] ip link delete dev wg0 wg-quick down wg0 wg-quick: `wg0' is not a WireGuard interface Maybe I'm running into a problem simply because I'm using VLANs as my main interface for Unraid? I certainly appreciate any ideas. Maybe its just simpler for me to run a dedicated VM, or docker container? phoenix-diagnostics-20240318-1748.zip


-
I've had the NUT V2 plugin up and running for sometime now, recently I seem to stop getting data from it after a few mins to hours. phoenix-diagnostics-20240318-1711.zip I checked the USB cable, and ran the auto detect in the plugin again which seems to work but after a bit it fails again. I even tried replacing the USB cable with a new one. Might someone have some insight into what is breaking? I see this repeated in the logs. Mar 18 17:12:51 phoenix upsmon[1164]: Poll UPS [[email protected]] failed - Data stale Mar 18 17:12:53 phoenix usbhid-ups[978]: libusb1: Could not open any HID devices: insufficient permissions on everything Mar 18 17:12:55 phoenix usbhid-ups[978]: libusb1: Could not open any HID devices: insufficient permissions on everything Which from my searching seems could be a failed USB cable? I'm just hoping the UPS (or rather the USB controller / port on it) isn't going bad.
-
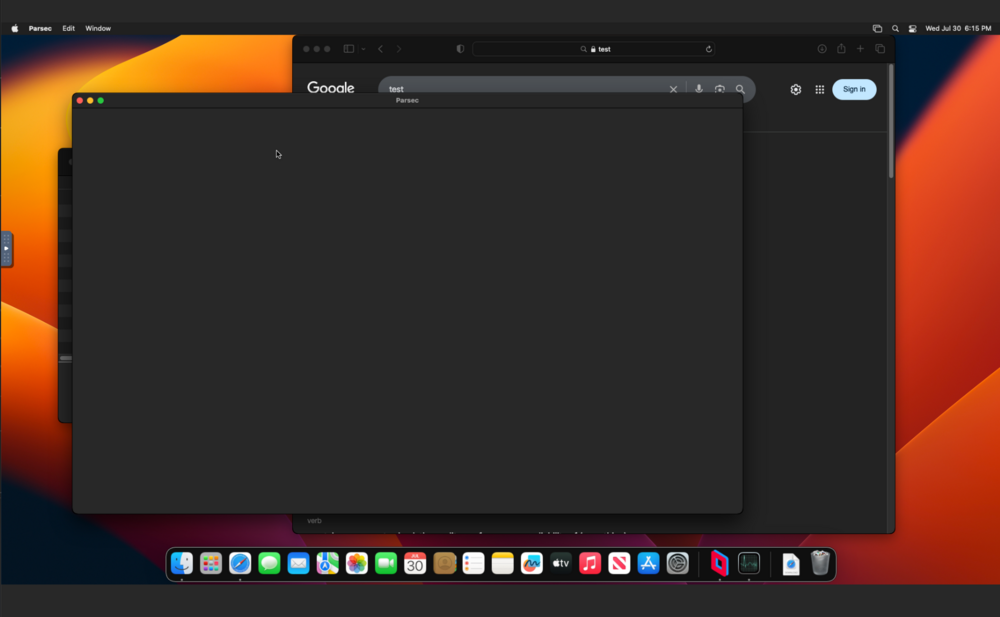
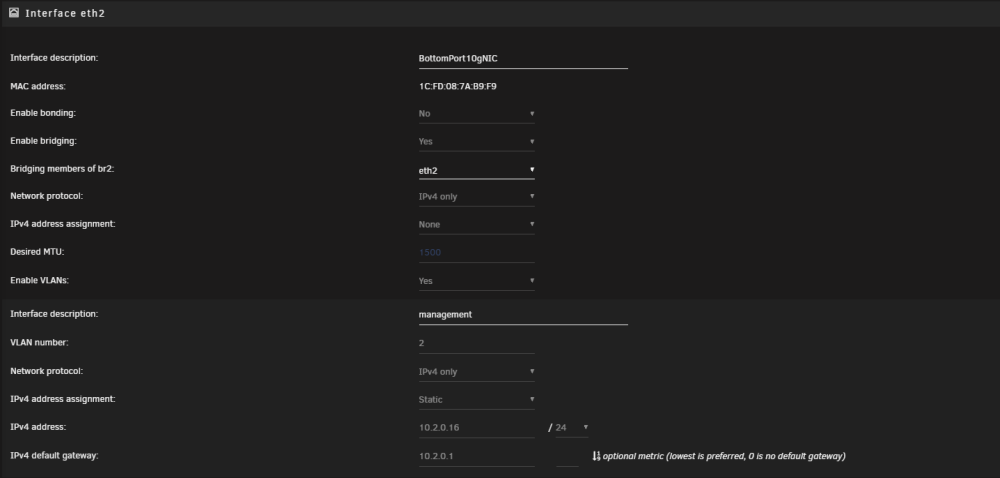
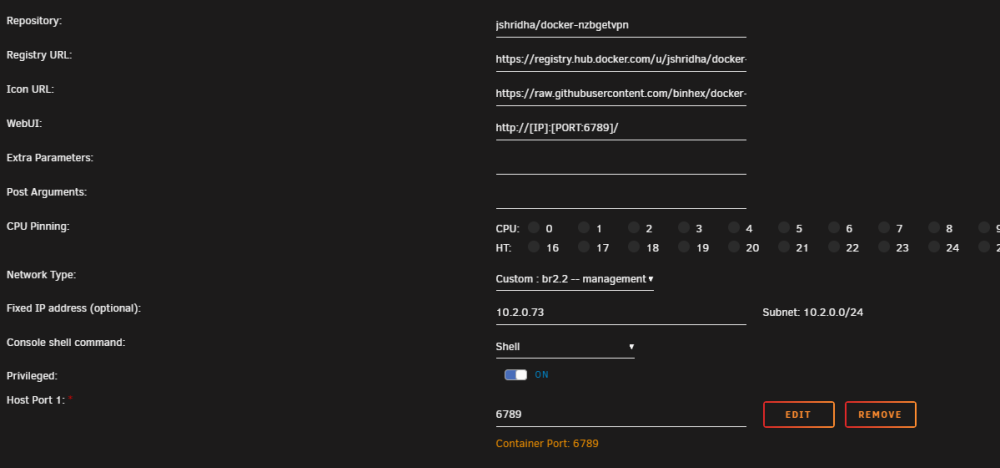
What I'm trying to do I recently did a network upgrade and installed a 10gig NIC in my unraid server. My intention is to separate my network into several VLANs. I have all the networking stuff working, router + switches etc. I believe I have setup the networking in unraid as I should. Settings > Networking I can reach the unraid server on that VLAN (2) as expected. I would like to be able to assign a given Docker Container (or VM but troubleshooting just docker here) to that VLAN. I started with the defaults I already head in the docker settings Docker custom network type: ipvlan Host access to custom networks: Disabled But added a new custom network on interface br2.2. And removed the previous custom network I made sure my local physical DHCP server was passing out IP address in a different range on the same subnet than the DHCP pool configured in docker settings. Then in each container I had running I changed, the network type and set a fixed ip address. For several of my docker containers this seemed to work as expected. However I have two issues that I can't seem to explain. Issue 1 I have an nzbgetvpn container running, when it starts logs indicate its working as normal. I can ping the containers fixed IP address. But when I attempt to connect to the web interface on its ip + port the connection times out. Digging deeper looking at wireshark I can see the containers IP respond as expected to ICMP ping requests, but it doesn't respond at all to TCP traffic to the port for the web interface. During my troubleshooting I change that containers network type, back to "bridge" When I do so in the docker page I see it now has this IP address To my knowledge I don't have anything on my network using a 172.17.x.x address so I have no idea where it is getting that from..... On top of that if I then try to access http://10.2.0.16:6789 I can pull up the web interface of the container??? (Thats the IP address of the unraid host on VLAN2 + the port of the web interface of the container). Issue 2 Moving on to another container... I am running "nut-influxdb-exporter" which tries to connect to the unraid host running the NUT plugin (UPS power stuff) on port :3493 I had this container running with the same custom network I just setup When the container boots I see errors that I can't connect to the unraid host. Dropping into a console for the container I noticed that it can successfully ping other docker containers configured on the same network (10.2.0.68 for example is my InfluxDB container) and it can ping other hosts on that network 10.2.0.1 for example my physical routers interface on this VLAN. But it can't ping 10.2.0.16 the IP of the Unraid host on that VLAN. Even with all my searching over the last week I suspect I'm missing something fundamental about how to get this type of configuration correct. Might anyone be able to point me in the right direction? phoenix-diagnostics-20240311-0624.zip



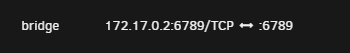

-
Well... I think I fixed it... but I haven't a clue how... I change the docker container from the above network type to give it an IP address on my VLAN interface (br2.2) to the "Bridge" network type. after doing this The UI reports the container has an IP of 172. something.... I have nothing on my network or unraid server using that IP range to my knowledge.... But I happen to try putting in the IP address of my unraid server and the nzbget port in the browser and ... there it is working at 10.2.0.16:6789... No idea what that did or how its working unfortunately ...



-
I think my nzbgetvpn container may have stopped working sometime ago. I got back to doing some upgrades to my home lab. I've setup Unraid with multiple VLANs. I've just moved all my docker containers to one of the new VLANS. "Network br2.2" I can't seem to access the nzbget web ui. When I look at the logs 2024-03-09 12:57:09,145 DEBG 'start-script' stdout output: [info] Successfully assigned and bound incoming port '25361' 2024-03-09 12:57:39,435 DEBG 'watchdog-script' stdout output: [info] nzbget not running 2024-03-09 12:57:39,435 DEBG 'watchdog-script' stdout output: [info] Nzbget config file already exists, skipping copy 2024-03-09 12:57:39,447 DEBG 'watchdog-script' stdout output: [info] Attempting to start nzbget... 2024-03-09 12:57:39,456 DEBG 'watchdog-script' stdout output: [info] Nzbget process started [info] Waiting for Nzbget process to start listening on port 6789... 2024-03-09 12:57:39,460 DEBG 'watchdog-script' stdout output: [info] Nzbget process is listening on port 6789 The service seems to be listening on the port. and I did update the LAN_NETWORK variable and added all my local networks. I can ping the docker containers IP address (10.2.0.73) and get a response but I get no response at all when trying to access the webgui. Looking at wireshark, when I try to connect to the webui there's not return traffic at all from the container. Any ideas what might be wrong here?
-
I recently moved. In the process a bunch of my "old" hardware got mixed up with my "new" hardware.... I now find myself with a box of hard drives (More then 30). I would like to setup some kind of test where I can get a simple "Pass" or "Fail" as to if I should trust each drive with data. Short of just looking at a SMART report is there something else I can do to test each drive? I have an old dell server I can install a few drives in at a time. It actually has server blades, each with 3x 3.5 drive bays. I was going to boot up unraid on each, and systematically try to run a preclear on each disk. If that works then drive Passes If it doesn't then drive fails. But doing so I'd need to go buy 4 more Unraid licenses just to test this bunch of drives which seems a bit of a waste. I suspect I could find the code for the preclear script some place and run it from a linux install of my choice but this feels like one of those problems someone else must have already solved and I'd be starting to reinvent the wheel. Am I already on the best path here or is there something I just don't know of yet?
-
So strange I must have just shock a power cable loose. After double checking all connections and giving them a wiggle, the drive are back. But I'm assuming I have to get the disks reassigned in the right order right? I do thankfully keep backups and was able to go did them up and find the disk assignments at /config/DISK_ASSIGNMENTS.txt from the backup of the unraid flashdrive. Thank you for the help
-
Thanks for clarifying that, once this parity check finishes I'll do a clean shutdown and check all the cables. Now that I think about it I did move the rack a little bit yesterday maybe something got loose.
-
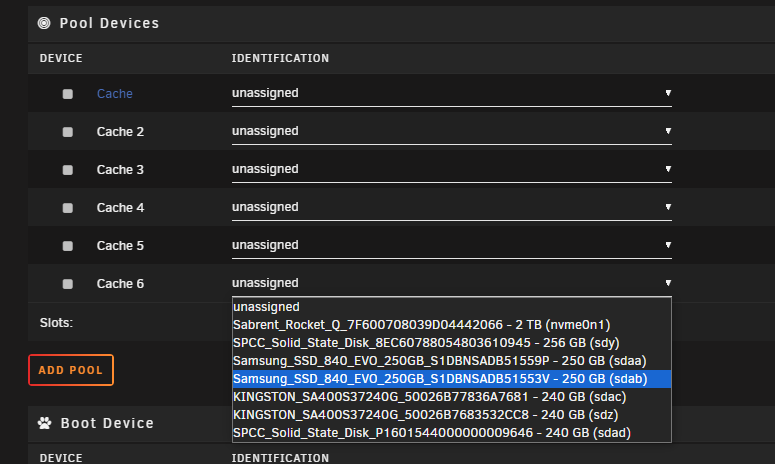
Noticed this morning after a reboot last night Started googling that issue as I recalled sometimes the docker image or something getting corrupted as something I'd seen before. But then noticed this I have 6 (... I'm pretty sure it was 6) SSDs in a pool for the cache. They are getting up there in age wouldn't surprise me if one failed but I wouldn't have expected them all to vanish. Its currently doing a parity check, once that finishes I'll stop the array and do a nice clean reboot + check the cables etc. In the mean time maybe someone might see something in the logs that didn't catch my eye? phoenix-diagnostics-20240202-1057.zip
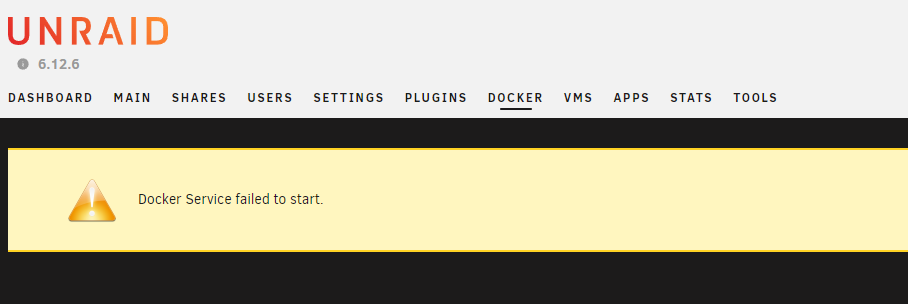
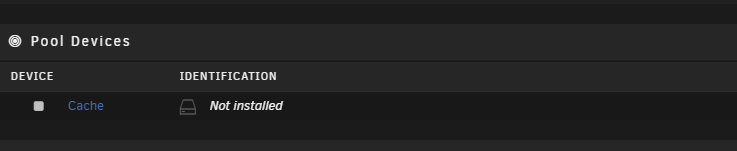
-
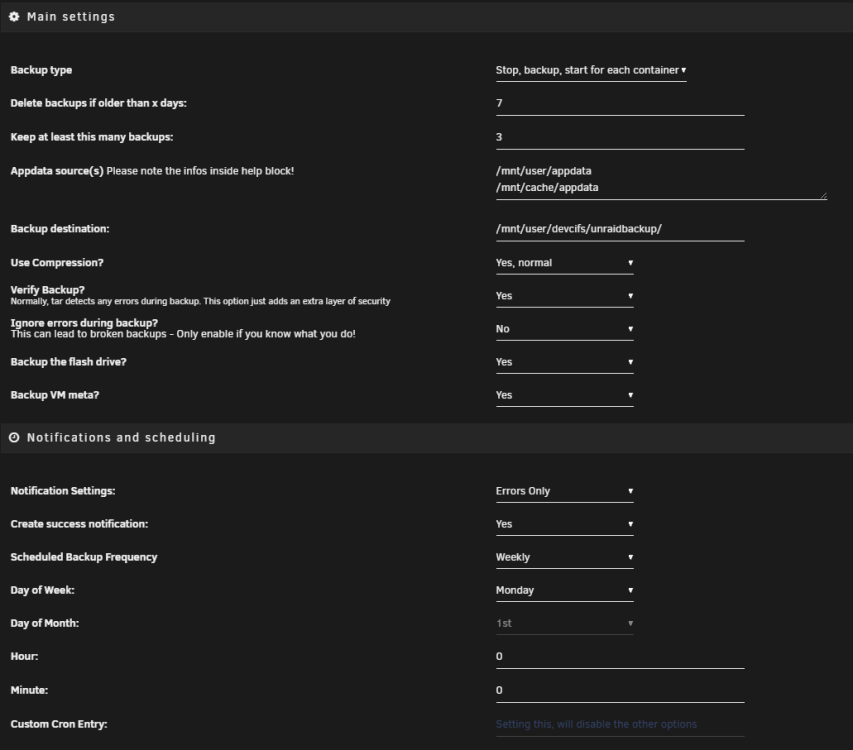
Quick question... I'm looking at what was written to my "Backup destination" path after completing a manual backup to verify it worked and its unclear what I should see there. I was expecting to find copies of my appdata directories, as well as the VM meta data, and the flash drive. Clear enough that it has something for the VM meta data and flash drive. But are all the .xml just a representation of the appdata paths somehow? I'm guessing not... I don't see anything else there to indicate the appdata paths successfully backuped up. But I don't see anything from the backup script indicating it failed.

-
It has crashed once since I changed to ipvlan. Found it that way the morning of Nov 8th if I recall correctly and had to do a hard reboot (reset switch). As of 10am Nov 9th its still up and running. If it crashes and I have to hard reset again, I'll grab new logs and diag files. Hopefully it was just that macvlan setting or something else points to a fix. Thank you for the help
-
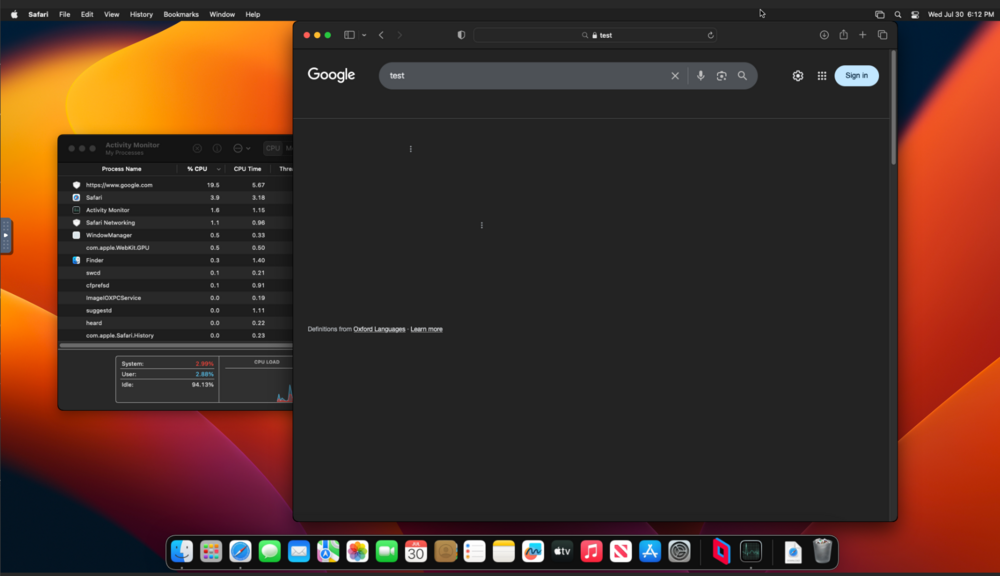
Yes it is. Took longer this time was up for ~2 days. Woke up to it crashed this morning, before I grabbed those last logs above. Same crash screen on the monitor as above (kernel panic).
-
I went back and filled in the server IP of my unraid server. I also adjusted the docker networking setting you suggested and changed it from macvlan to ipvlan I don't see anything different in the logs folder on the flash drive. attached as log2.zip logs2.zip But I did find a syslog file in the appdata folder, maybe that is being mirrored to the flash drive and I just didnt see it? syslog-192.168.0.216.log
-
Ahh I see, here's a copy of the logs directory from the flash drive. That documentation seems to indicate it should have been mirroring the logs to there. But I also noticed this folder selection in the settings, but I guess that must be something else I don't see anything pertaining to system logs in the selected appdata folder. logs.zip
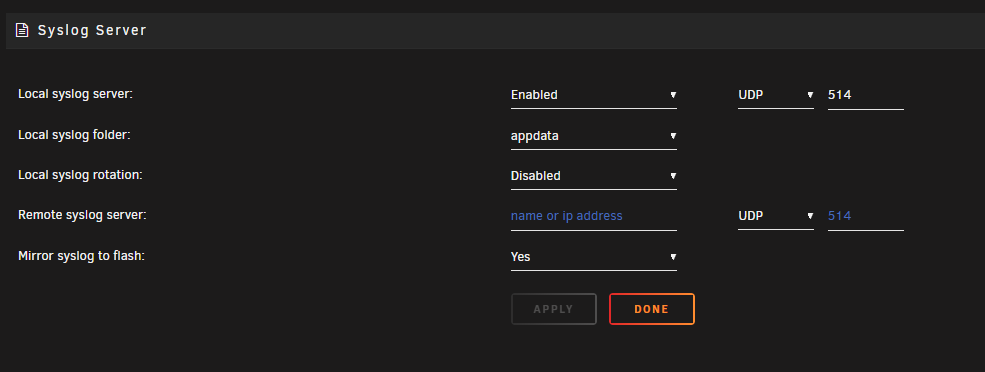
-
Thanks JorgeB I was able to do that, and looks like that syslog data is included in the diag.zip I was able to grab from the next crash. This morning I found unraid again not responding when I try to open the webGUI via its usual IP, and found a similar kernel panic error on screen when I checked it. After forcing another reboot I grabbed the diag.zip again here nothing is jumping out at me as I looked through the logs, hopefully someone sees something I'm not. phoenix-diagnostics-20231105-0912.zip
-
I recently rebuilt my array after some drives failed, or went missing. Things were fine for a day or two then one morning this week unraid wasn't responding checking on it I saw what looks to me a link a kernel panic. <screen shot attached> I was forced to power cycle unraid, and twice now during a parity sync the same thing has happen by the next morning. Anyone have any ideas what may be the problem? Should I just start by running old school memtest or something? phoenix-diagnostics-20231102-1258.zip