




Jimmeh
Members
-
Joined
-
Last visited
Everything posted by Jimmeh
-
Fair enough, I'll make that change. Thanks again!
-
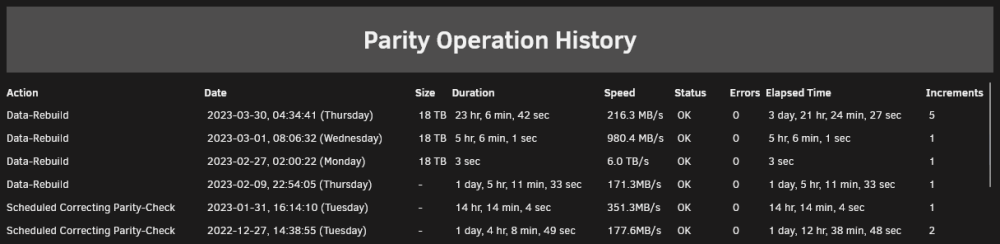
Thanks for taking the time to respond. I noticed that the entries corresponding to the ones in my previous screenshot are identified as "recon D5" rather than "check P" so I assume that's where the "Action" column comes from. config\parity-checks.log 2022 Dec 27 14:38:55|101329|177.6MB/s|0|0|check P|131928|2|SCHEDULED Correcting Parity Check 2023 Jan 31 16:14:10|51244|351.3MB/s|0|0|check P|51244|1|SCHEDULED Correcting Parity Check 2023 Feb 9 22:54:05|105093|171.3MB/s|0|0|recon D5|105093|1|AUTOMATIC Parity Sync/Data Rebuild 2023 Feb 27 02:00:22|3|6.0 TB/s|0|0|recon D5|17578328012|3|1|Scheduled Correcting Parity Check 2023 Mar 1 08:06:32|18361|980.4 MB/s|0|0|recon D5|17578328012|18361|1|Manual Correcting Parity Check 2023 Mar 30 04:34:41|83202|216.3 MB/s|0|0|recon D5|17578328012|336267|5|Scheduled Correcting Parity-Check Requested files attached. Thanks for your help. parity.check.tuning.progress.save parity-checks.log
-
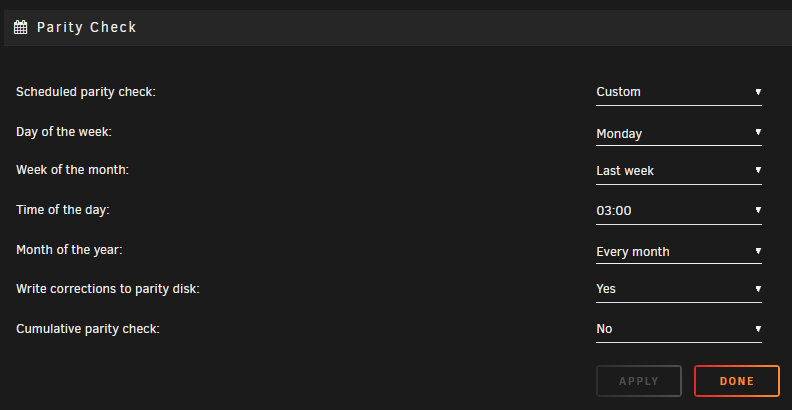
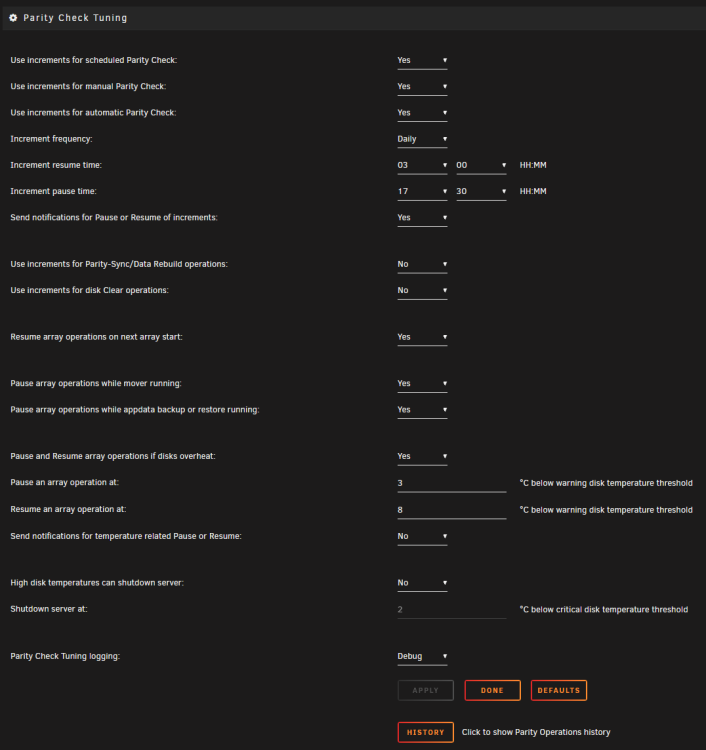
Firstly thanks for this plugin, have been using it for a while and your work is greatly appreciated. I have a few strange issues which I'm unsure are due to configuration errors on my part, let me try to give an overview. My default parity check options are to trigger a custom parity check on the last Monday of every month, and cumulative parity checks are disabled here as shown: My settings for your plugin are to resume daily at 3:00, pause at 17:30 and pause if mover gets in the way. I have just now enabled the debugging option to see if that provides any more detail. Looking through the syslogs I can see the parity check is resumed as expected at 3:00, is correctly paused when mover interferes, but throws exit status 255 after the mover exits and does not resume. Apr 26 03:00:01 medianator Parity Check Tuning: Resumed: Scheduled Correcting Parity-Check Apr 26 03:00:01 medianator Parity Check Tuning: Resumed: Scheduled Correcting Parity-Check (71.7% completed) Apr 26 03:00:07 medianator kernel: mdcmd (63): check resume Apr 26 03:00:07 medianator kernel: Apr 26 03:00:07 medianator kernel: md: recovery thread: check P ... Apr 26 06:00:24 medianator Parity Check Tuning: Mover running Apr 26 06:00:29 medianator kernel: mdcmd (64): nocheck PAUSE Apr 26 06:00:29 medianator kernel: Apr 26 06:00:29 medianator kernel: md: recovery thread: exit status: -4 Apr 26 06:00:29 medianator Parity Check Tuning: Paused: Mover running: Scheduled Correcting Parity-Check (82.6% completed) Apr 26 06:04:11 medianator crond[1200]: exit status 1 from user root /usr/local/sbin/mover &> /dev/null Apr 26 06:06:26 medianator Parity Check Tuning: Mover no longer running Apr 26 06:06:31 medianator crond[1200]: exit status 255 from user root /usr/local/emhttp/plugins/parity.check.tuning/parity.check.tuning.php "monitor" &>/dev/null Additionally, despite the syslog showing "Scheduled Correcting Parity-Check", the parity operation history now references my last 3 scheduled checks as "Data-Rebuild" rather than a scheduled check. Once the check is complete each month there are no errors and everything looks fine. Does this give you an idea of what could have gone awry? Any suggestions would be welcome.
-
5.11.4 was released on July 10th. Will you be pushing an updated docker image or is there something I need to do on my side? https://github.com/pi-hole/pi-hole/releases/tag/v5.11.4 Edit: Thanks
-
Looks like the repo isn't carrying anything later than 1.0.0-RC1 and we're on RC4 now. Not sure what's going on there, any ideas?


