

jimbo123
-
Posts
44 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by jimbo123
-
Yes, correcting as it goes. I've attached the diagnostic zip below. I've also included one that I took about 1 hr into the parity check from yesterday, may be of use. storage-diagnostics-20201106-0837.zip storage-diagnostics-20201105-1026.zip
-
Have now upgraded to 6.8.3. Seems like a similar amount of errors are being corrected during the check: EDIT: Seems to have grown to more than before,..


-
OK,.. so unplugged all drives, board, cables, etc,.. plugged back in and kicked off parity check - still encounters sync errors. While it goes through the check, I'll read up on the upgrade process and then get it current.
-
Hardware is one of the early HP MIcroservers,.. an N36L. Nothing changed really, running onboard controller. I updated BIOS firmware to enable the CD/DVD drive to operate as a SATA disk, or something similar from memory. One parity disk and 4 data drives as mentioned earlier. I'll update to current stable and see how things behave.
-
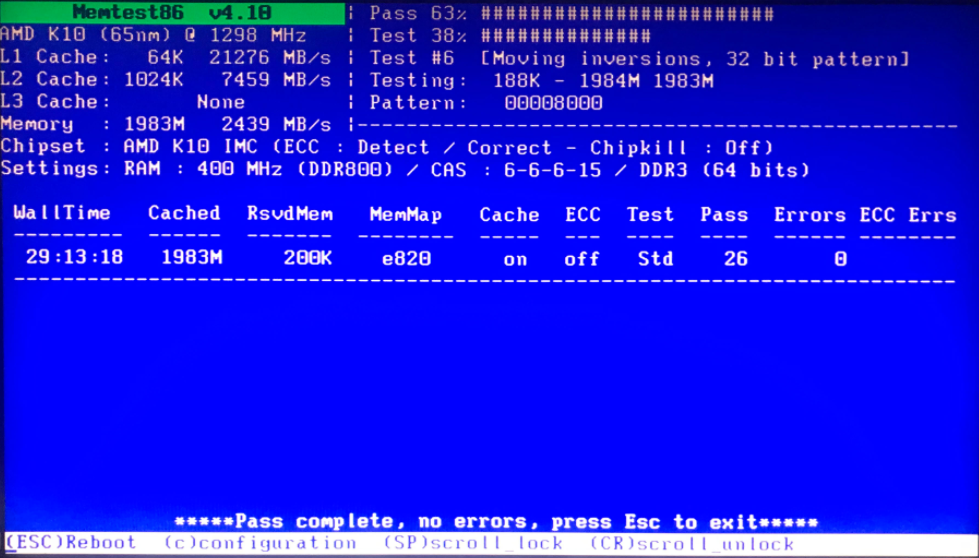
Memory checks seems fine,.. is there anything else I should be checking ?
-
Several hours and passes later,.. sill no errors detected,.. did a couple with ECC on,.. still no errors. Will leave it running memtest for a few more hours. Anything else I should check ?
-
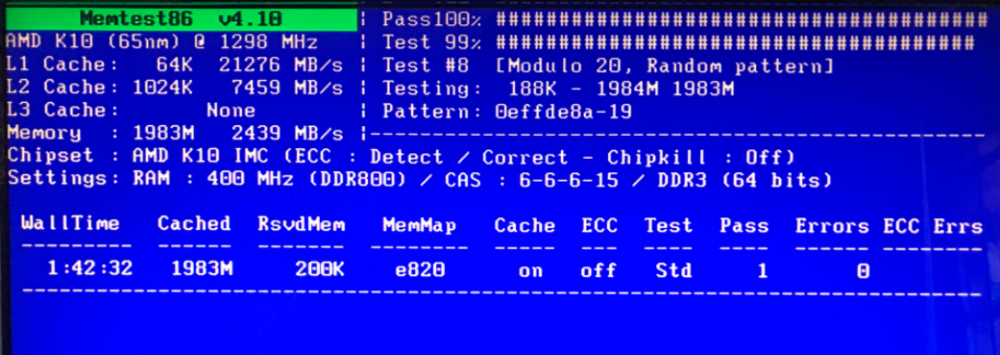
Memtest looks ok so far,.. 2nd is now done still with no errors. There's only 2GB in this system. Will leave it going for a few more hours.
-
No I hadn't. I'll do that shortly. Is there a way to run memtest while server is running,.. as I run it headless ? EDIT: memtest running now,.. 50% done, no errors yet.
-
Hi all, I've been running unRAID for about 10 years now,.. mostly on auto-pilot, with only issues I've had a a few failed drives. I run a monthly parity check,.. and up until the last few weeks have never had any sync errors with the check at all. The last few parity checks have been showing up corrected errors. Today 1st Nov,.. it did its normal monthly check and again found and corrected sync errors (217). Nov 1 00:00:01 storage kernel: mdcmd (42): check CORRECT Nov 1 00:00:01 storage kernel: Nov 1 00:00:01 storage kernel: md: recovery thread woken up ... Nov 1 00:00:01 storage kernel: md: recovery thread checking parity... Nov 1 00:00:01 storage kernel: md: using 1536k window, over a total of 3907018532 blocks. Nov 1 00:05:16 storage kernel: md: correcting parity, sector=65721672 Nov 1 00:09:27 storage kernel: md: correcting parity, sector=122070112 Nov 1 00:09:28 storage kernel: md: correcting parity, sector=122183264 Nov 1 00:09:28 storage kernel: md: correcting parity, sector=122187616 Nov 1 00:09:28 storage kernel: md: correcting parity, sector=122196320 Nov 1 00:09:28 storage kernel: md: correcting parity, sector=122213728 Nov 1 00:09:28 storage kernel: md: correcting parity, sector=122218080 Nov 1 00:09:28 storage kernel: md: correcting parity, sector=122252896 Nov 1 00:09:29 storage kernel: md: correcting parity, sector=122435680 Nov 1 00:09:29 storage kernel: md: correcting parity, sector=122440032 Nov 1 00:09:29 storage kernel: md: correcting parity, sector=122514016 Nov 1 00:09:29 storage kernel: md: correcting parity, sector=122540128 Nov 1 00:09:30 storage kernel: md: correcting parity, sector=122548832 Nov 1 00:09:30 storage kernel: md: correcting parity, sector=122557536 Nov 1 00:09:30 storage kernel: md: correcting parity, sector=122561888 Nov 1 00:09:30 storage kernel: md: correcting parity, sector=122566240 Nov 1 00:09:30 storage kernel: md: correcting parity, sector=122592352 Nov 1 00:09:30 storage kernel: md: correcting parity, sector=122596704 Nov 1 00:20:28 storage kernel: md: correcting parity, sector=270032168 After it had finished,.. I manually kicked off the check again after a few hours,.. and again it found errors again, (its almost done and is at 218). Nov 1 14:15:11 storage kernel: md: recovery thread woken up ... Nov 1 14:15:11 storage kernel: md: recovery thread checking parity... Nov 1 14:15:11 storage kernel: md: using 1536k window, over a total of 3907018532 blocks. Nov 1 14:20:20 storage kernel: md: correcting parity, sector=65721672 Nov 1 14:24:08 storage kernel: md: correcting parity, sector=117798280 Nov 1 14:24:13 storage kernel: md: correcting parity, sector=118812296 Nov 1 14:24:15 storage kernel: md: correcting parity, sector=119217032 Nov 1 14:24:15 storage kernel: md: correcting parity, sector=119260552 Nov 1 14:24:16 storage kernel: md: correcting parity, sector=119452040 Nov 1 14:24:27 storage kernel: md: correcting parity, sector=122070112 Nov 1 14:24:28 storage kernel: md: correcting parity, sector=122183264 Nov 1 14:24:28 storage kernel: md: correcting parity, sector=122187616 Nov 1 14:24:28 storage kernel: md: correcting parity, sector=122196320 Nov 1 14:24:28 storage kernel: md: correcting parity, sector=122213728 Nov 1 14:24:28 storage kernel: md: correcting parity, sector=122218080 Nov 1 14:24:28 storage kernel: md: correcting parity, sector=122252896 Nov 1 14:24:29 storage kernel: md: correcting parity, sector=122435680 Nov 1 14:24:29 storage kernel: md: correcting parity, sector=122440032 Nov 1 14:24:29 storage kernel: md: correcting parity, sector=122514016 Nov 1 14:24:29 storage kernel: md: correcting parity, sector=122540128 Nov 1 14:24:29 storage kernel: md: correcting parity, sector=122548832 Nov 1 14:24:29 storage kernel: md: correcting parity, sector=122557536 Have I got a disk that is on its way out ? I see no other errors in the log,.. previously, when I was having disk errors, there'd be something in there. I'm running 5.0.5 with the following layout: 4TB parity 2 x 2TB 2 x 4TB I've looked at smartctl details and the only thing that looks out of place is in the attached file (WDC_WD40EFRX-68N32N0_3704261.txt), but the events in there seem like they're old, but I'm no expert here. The other 4 drives show similar to the file 'WDC_WD40EFRX-68N32N0_WD-WCC7K5NPLNN1.txt' Can the sectors associated with the errors be matched back to a disk ? Hoping someone can shed some light on what's going on and help me identify if I do have a disk that needs to be replaced. Thanks in advance, Jim..... WDC_WD40EFRX-68N32N0_3704261.txt WDC_WD40EFRX-68N32N0_WD-WCC7K5NPLNN1.txt
-
Disk failing, want to swap parity drive around.
jimbo123 replied to jimbo123's topic in General Support (V5 and Older)
Yes, new disk is larger,.. and yes I want it as parity as it then gives me the ability to upgrade the others as I need to for additional storage. I re-read steps 12 and 13 and its now more clearer to me. Thanks JB. Just needed some reassurance -
Disk failing, want to swap parity drive around.
jimbo123 replied to jimbo123's topic in General Support (V5 and Older)
Drive arrived during the week,.. new drive is now going through a preclear,.. expect it should finish overnight and I can then start the configuring when I get home from work tomorrow. So the situation I'm in is: Went through steps 1 to 8 Array is running minus the the drive I pulled. New drive is preclearing in its slot. I assume that when the preclear finishes, that I: 8b. stop the array 9. unassign the parity disk (can I do this without losing any data ? as the old disk is not replaced yet and I'll now also be a parity drive out ?) 10. assign the new drive as the parity 11. assign old parity drive into the array 12, 13 , 14 as per guide. Step 9 is what I'm unsure of ? Or should I add: 8c. assign the new drive into the array (taking the slot of the failing drive I removed) - let it rebuild and sort itself out and then continue with step 9 and onwards ? Jim..... -
Hi all, I currently have an unRAID v5.0.5 system that's been running on virtually auto-pilot for several years. It runs a monthly parity check and has always indicated no issue. The logs below occurred during this months parity check and it still showed up with 0 parity errors. Setup is: Hardware: HP ProLiant MicroServer N36L Data: 4 x 2TB WD20EARS Parity: 2TB WD20EARS Have recently noticed the following: Nov 1 05:14:42 storage kernel: ata1.00: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x0 (Errors) Nov 1 05:14:42 storage kernel: ata1.00: irq_stat 0x40000001 (Drive related) Nov 1 05:14:42 storage kernel: ata1.00: failed command: READ DMA EXT (Minor Issues) Nov 1 05:14:42 storage kernel: ata1.00: cmd 25/00:00:68:62:72/00:04:b7:00:00/e0 tag 0 dma 524288 in (Drive related) Nov 1 05:14:42 storage kernel: res 51/40:9f:c8:64:72/00:01:b7:00:00/e0 Emask 0x9 (media error) (Errors) Nov 1 05:14:42 storage kernel: ata1.00: status: { DRDY ERR } (Drive related) Nov 1 05:14:42 storage kernel: ata1.00: error: { UNC } (Errors) Nov 1 05:14:42 storage kernel: ata1.00: configured for UDMA/133 (Drive related) Nov 1 05:14:42 storage kernel: sd 1:0:0:0: [sdb] Unhandled sense code (Drive related) Nov 1 05:14:42 storage kernel: sd 1:0:0:0: [sdb] (Drive related) Nov 1 05:14:42 storage kernel: Result: hostbyte=0x00 driverbyte=0x08 (System) Nov 1 05:14:42 storage kernel: sd 1:0:0:0: [sdb] (Drive related) Nov 1 05:14:42 storage kernel: Sense Key : 0x3 [current] [descriptor] Nov 1 05:14:42 storage kernel: Descriptor sense data with sense descriptors (in hex): Nov 1 05:14:42 storage kernel: 72 03 11 04 00 00 00 0c 00 0a 80 00 00 00 00 00 Nov 1 05:14:42 storage kernel: b7 72 64 c8 Nov 1 05:14:42 storage kernel: sd 1:0:0:0: [sdb] (Drive related) Nov 1 05:14:42 storage kernel: ASC=0x11 ASCQ=0x4 Nov 1 05:14:42 storage kernel: sd 1:0:0:0: [sdb] CDB: (Drive related) Nov 1 05:14:42 storage kernel: cdb[0]=0x28: 28 00 b7 72 62 68 00 04 00 00 Nov 1 05:14:42 storage kernel: end_request: I/O error, dev sdb, sector 3077727432 (Errors) Nov 1 05:14:42 storage kernel: ata1: EH complete (Drive related) Nov 1 05:14:42 storage kernel: md: disk1 read error, sector=3077727368 (Errors) Nov 1 05:14:42 storage kernel: md: disk1 read error, sector=3077727376 (Errors) Nov 1 05:14:42 storage kernel: md: disk1 read error, sector=3077727384 (Errors) Nov 1 05:14:42 storage kernel: md: disk1 read error, sector=3077727392 (Errors) Nov 1 05:14:42 storage kernel: md: disk1 read error, sector=3077727400 (Errors) Nov 1 05:14:42 storage kernel: md: disk1 read error, sector=3077727408 (Errors) Nov 1 05:14:42 storage kernel: md: disk1 read error, sector=3077727416 (Errors) Disk 1 has about 1TB of data on it. All up the array is about 50% utilised. I figure the disk above is on its way out, so a WD40EFRX 4TB RED drive is on its way. What I'd like to do is: make the new 4TB the parity disk have the existing parity assume the role of the failing disk 1 Have found this link,.. the block titled "The procedure" seems relevent to me. https://wiki.lime-technology.com/The_parity_swap_procedure Every guide I've read always recommends preclearing, but have also read that its not necessary if its a parity drive ? I'm figuring the following is what i need to do: Given I have no spare SATA spots in my system, I follow steps 1 to 8. New drive will then be unassigned. Run the pre-clear script against the new drive ? If its needed ? Continue on from step 9 So my queries: is preclear needed if its role will be that of a parity drive ? am I following the right guide/steps for what I want to do ? am I missing anything ? Any guidance would be appreciated. Thanks in advance, Jim..... smart.txt
-
about half-way thru,.. great read
-
more old school stuff: - to list all mapped shares net use <CR> - chances are you're already connected to your share net use \\tower\share_name /delete and then retry the previous stuff
-
old school,.. at a command prompt: net use * \\tower\share_name /user:jimbo - assuming user jimbo is the user you've created.
-
Think you just share it readonly and then put your user in with an exception,.. on my 4.7 pro version to get the user thing happening you need the pro version,.. Assume the same for 5.x
-
Installed this the other day,.. be nice if/when temp support is there. Taken from: http://bjango.com/help/istat/istatserverlinux/



