




sorano
Members
-
Joined
-
Last visited
Everything posted by sorano
-
I really appreciate you taking your time trying to help. Right now I'm just going to accept that this piece of trash Asus motherboard is fucking broken with SR-IOV and plan better for my next build. No matter what I do sriov_numvfs will not show up in sysfs for the device, so the echo'ing has no effect.
-
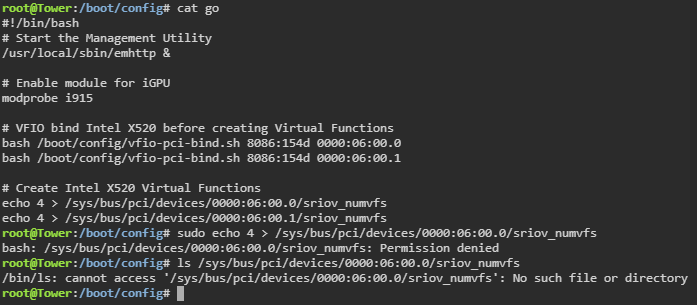
Well, in the last post you told me I need to vfio bind the NIC before configuring VFs right? So after that I added the two first lines: # VFIO bind Intel X520 before creating Virtual Functions bash /boot/config/vfio-pci-bind.sh 8086:154d 0000:06:00.0 bash /boot/config/vfio-pci-bind.sh 8086:154d 0000:06:00.1 Then the next two lines are creating the actual VFs # Create Intel X520 Virtual Functions echo 4 > /sys/bus/pci/devices/0000:06:00.0/sriov_numvfs echo 4 > /sys/bus/pci/devices/0000:06:00.1/sriov_numvfs (This is the part that does not work since sriov_numvfs is not visible under /sys/bus/pci/devices/0000:06:00.0/ so the echo does nothing)
-
Damn, I really hoped that would have been it but it's still not working. Same as before. I cannot even create VFs even though X520 is VFIO bound: sriov_numfs still does not exist for the card:


-
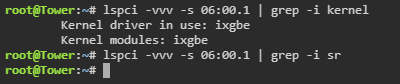
After spending way to many hours trying to get Mellanox Virtual Function running under Windows I finally gave up and bought an Intel X520 DA-2 New card, new problems. It's like the kernel is ignoring the SR-IOV functions of the card for some reason. I checked in BIOS but could not find anything related to activating SR-IOV for the card either. Since sriov_numvfs does not exist for the device I cannot get any VF's.


-
I have a ConnectX-3 Pro. But I'm having issues with SR-IOV to a Windows VM as in this thread: I was discussing my issue with the moderators in VFIO discord and one of them said I should try with newer Mellanox drivers.
-
@ich777 If you have the time and possibility I would like to request the Mellanox 4.9-2.2.4.0 LTS driver: https://www.mellanox.com/products/infiniband-drivers/linux/mlnx_ofed/#tabs-2 Release notes/Installation: https://docs.mellanox.com/display/MLNXENv492240/Release+Notes Linux Driver Compatibility Matrix: https://www.mellanox.com/support/mlnx-ofed-matrix Currently, UnRAID 6.9.1 ships with kernel: mlx4_core: Mellanox ConnectX core driver v4.0-0 modinfo mlx4_en filename: /lib/modules/5.10.21-Unraid/kernel/drivers/net/ethernet/mellanox/mlx4/mlx4_en.ko.xz version: 4.0-0 license: Dual BSD/GPL description: Mellanox ConnectX HCA Ethernet driver author: Liran Liss, Yevgeny Petrilin srcversion: EE160E8DB5FA601160D41B2 depends: mlx4_core retpoline: Y intree: Y name: mlx4_en vermagic: 5.10.21-Unraid SMP mod_unload parm: udp_rss:Enable RSS for incoming UDP traffic or disabled (0) (uint) parm: pfctx:Priority based Flow Control policy on TX[7:0]. Per priority bit mask (uint) parm: pfcrx:Priority based Flow Control policy on RX[7:0]. Per priority bit mask (uint) parm: inline_thold:Threshold for using inline data (range: 17-104, default: 104) (uint)
-
It's Windows 10 20H2. But yeah, seems to be related to that driver mess just like you wrote. While troubleshooting I added the VF to an Ubuntu VM that just boots off Ubuntu 20.10 live iso and the VF worked straight away. Guess I'm gonna be finding and testing alot of drivers, if you have any recommendation it would be greatly appreciated. The card is updated with latest official firmware; 2.42.5000.
-
Seeing this I decided to put my Mellanox ConnectX3-Pro into my UnRAID server. I created 4 VFs following @ConnectivIT's guide using Option 1 (didnt set any static MAC yet). Then I added 1 of the VFs to my Win10 gaming workstation. However, Windows device manager doesn't want to start the device. There is a Mellanox ConnectX-3 VPI (MT041900) Virtual Network Adapter visible, but it is stopped with code 43. I tried installing 5.50.53000 WinOF driver from Nvidia site, but still no go. Any suggestion for a solution would be greatly appreciated!
-
Yeah I'm also seeing ALOT higher CPU usage on my gaming VM since the update. Upgraded from 6.8.3 to 6.9.1. Was fine at the start, after a while I started to notice that mouse movement would freeze and stutter, checked load on the VM's isolated cores in unraid webui, 99-100% on all of them. Since then I've been trying loads of edits to get it better, updated xml to use Q35-5.1 since that is supposed to be alot better with VFIO. Still havent come up with anything really good though. 😒





