




dharrah
Members
-
Joined
-
Last visited
-
Just to confirm, can you explain what exactly isn't working? Also, can you post your SWAG conf file for code-server?
-
This is fixed. I had to ultimately point my conf to http and port 9090 in SWAG: server { listen 443 ssl; server_name transport.*; include /config/nginx/ssl.conf; client_max_body_size 0; location / { include /config/nginx/proxy.conf; resolver 127.0.0.11 valid=30s; proxy_max_temp_file_size 2048m; set $upstream_app newcrushftp; set $upstream_port 9090; set $upstream_proto http; proxy_pass $upstream_proto://$upstream_app:$upstream_port; } }
-
Just deployed the CrushFTP9 app and turned off my stuckless/crushftp I had previously had the stuckless app behind SWAG and working just fine. I set my ports the same and it is on the SWAG custom network When I first started CrushFTP9 up, I bounced SWAG and everything came up fine. All my other SSL dockers work except for the CrushFTP9 - all I get is "502 Bad Gateway" Here is my conf file: server { listen 443 ssl; server_name transport.*; include /config/nginx/ssl.conf; client_max_body_size 0; location / { include /config/nginx/proxy.conf; resolver 127.0.0.11 valid=30s; proxy_max_temp_file_size 2048m; proxy_pass https://<unraidIP>:9443; } } server { listen 9021; server_name transport.*; include /config/nginx/ssl.conf; client_max_body_size 0; location / { include /config/nginx/proxy.conf; resolver 127.0.0.11 valid=30s; proxy_max_temp_file_size 2048m; proxy_pass https://<unraidIP>:9021; } } I feel like I am missing something dumb/small.....but can't seem to find it. Any ideas?
-
That worked! I created a new folder in /home and then moved the following files from /config/nginx: nginx.conf ldap.conf ssl.conf proxy.conf After bouncing SWAG, I was able to connect just fine! Thanks @aptalca
-
Both - same results either way As I look at the browser console logs, I see a few errors: WebSocket handshake - error 200 WebSocket closed with status code 1006 I still have the stock proxy-confs file in place - no changes were made. But the fact that I get the login page at my domain address seems to indicate that the SWAG portion of things is "fine".
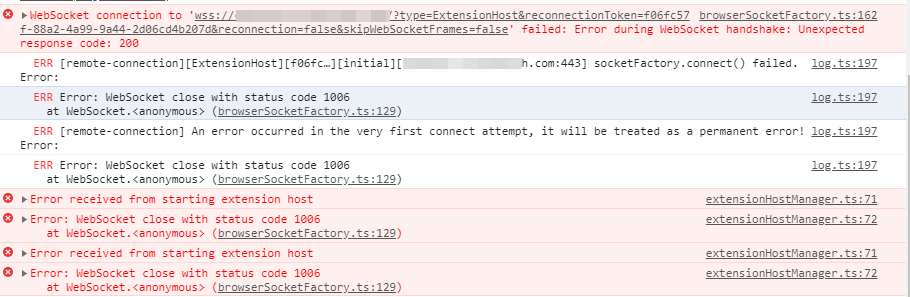
-
Yes - Chrome/Incognito is my primary browser, but I also tried IE and Firefox. Also Safari on my phone - same thing with the login page coming up first and then it goes blank after entering the password.
-
Getting blank page when navigating to code-server behind LE/SWAG I deployed the image stock - set it to my SWAG network Added a new domain and CNAME ("code-server" on namecheap DNS) Copied the 'code-server....sample' proxy-confs and just added my domain to the "server_name" line and left everything else alone (per other comments here) Updated SWAG docker with new domain and bounced SWAG and verified it comes up clean I can hit the new domain and it prompts for the web gui PW and right after authenticating, it just goes to a blank screen ??
-
Not yet, because I'm not interested in doubling my disk space requirements that would be needed when Sonarr copies the file to allow for seeding.
-
I am coming to Deluge from many, many years of using uTorrent. Main reason for the switch is my new unRaid server and wanting to move my torrents into a docker. So far, I really do like Deluge - especially the plugins. I've just moved all my movies, apps, and music from uTorrent into Deluge without a problem. All my path mappings are configured with the exception of my TV folder. With uTorrent, I was able to pre-configure my torrent filename and location prior to starting the download. For TV Shows this was very useful when dealing with various seasons of a particular show. In addition, I keep my torrents seeding nearly all the time and don't necessarily worry about removing them from the client. With Deluge, I am not seeing how to accomplish this task. I've read some posts (here and elsewhere) for similar questions as well as watched various tutorials and it seems the generic response is to run a script to copy the completed torrent file(s) and rename the copies. I do not like the idea of doubling my space simply for file management. I'm hoping that I simply overlooked a setting or plugin that will help. I'm currently using 'AutoAdd' and 'LabelPlus'. The one thing I've considered at this point is to configure my docker with individual paths that mount to each folder of my show. For example, for Twin Peaks, I have the following folder structure: <unRaid>/TV/Twin Peaks/Season <#>/S<#>E<#>.mkv If I map a path to /config/tv/twinpeaks which points to the path above (minus the 'Season'), then maybe that would work. It just seems laborious to go into the docker, add the new path map before I download each show, and then restart things. Anyone else currently tackling this? Did I overlook something simple/stupid? Thanks in advance!
-
That was it! Thanks again. It was the kick in the pants I needed
-
Thanks 1812. Group 21 only has the one device. However, I followed your link to 'HP Proliant & unRaid Information Thread' and started going through your steps just to see if anything would help. I am embarrassed to admit that I didn't go to the system log during all this testing, but right at the bottom after trying to dupe the problem I found this little gem No interrupt remapping support. Use the module param "allow_unsafe_interrupts" to enable VFIO IOMMU support on this platform So I've added the following snippet vfio_iommu_type1.allow_unsafe_interrupts=1 to my syslinux.cfg file and am rebooting. I'll post my logs if this still doesn't work.
-
I've scoured the internets and this thread has come the closest to what I'm seeing. However, I am still unable to pass any NIC through to a Win10 VM. I get the same error as noted above (couple times), but here is my specific error: internal error: qemu unexpectedly closed the monitor: 2017-09-01T21:46:07.720078Z qemu-system-x86_64: -device vfio-pci,host=09:00.0,id=hostdev0,bus=pci.0,addr=0x6: vfio: failed to set iommu for container: Operation not permitted 2017-09-01T21:46:07.720112Z qemu-system-x86_64: -device vfio-pci,host=09:00.0,id=hostdev0,bus=pci.0,addr=0x6: vfio: failed to setup container for group 21 2017-09-01T21:46:07.720118Z qemu-system-x86_64: -device vfio-pci,host=09:00.0,id=hostdev0,bus=pci.0,addr=0x6: vfio: failed to get group 21 2017-09-01T21:46:07.720134Z qemu-system-x86_64: -device vfio-pci,host=09:00.0,id=hostdev0,bus=pci.0,addr=0x6: Device initialization failed I'm running dual Xeon 5650s on a Dell P19C9 (C2100 Server) with VT-d (and VT-x) enabled. IOMMU shows 'Enabled' in the 'Info' output of Unraid (running version 6.3.5). I have enabled the PCIe ACS Override to split my IOMMU groups but I continue to get the error above. I'm currently trying to pass through the onboard dual NICs, but I do have a 4-port NIC that fails as well. Attached is my full output of 'lspci' but the relevant section is: //4-Port NIC 06:00.0 0200: 8086:10e8 (rev 01) 06:00.1 0200: 8086:10e8 (rev 01) 07:00.0 0200: 8086:10e8 (rev 01) 07:00.1 0200: 8086:10e8 (rev 01) 08:00.0 0107: 1000:0072 (rev 03) //On-Board NIC 09:00.0 0200: 8086:10c9 (rev 01) 09:00.1 0200: 8086:10c9 (rev 01) I have tried the vfio-pci.ids in my syslinux.cfg file, just trying to further isolate things (not sure if that was necessary, but I've tried to apply each recommendation from the various threads). This continues to result in same error. Full XML is attached, but relevant snippet from VM is: <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x09' slot='0x00' function='0x0'/> </source> <address type='pci' domain='0x0000' bus='0x00' slot='0x06' function='0x0'/> </hostdev> <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x09' slot='0x00' function='0x1'/> </source> <address type='pci' domain='0x0000' bus='0x00' slot='0x08' function='0x0'/> </hostdev> I'm hoping this is something dumb I'm overlooking so I'm reaching out for additional feedback. Thanks in advance! VM_XML.txt lspci.txt
