Rhynri
Members
-
Joined
-
Last visited
Everything posted by Rhynri
-
My apologies, AXi1600.
-
I'm not seeing any /dev/ttyUSB devices nor a loaded driver. I can see the device itself on a USB hub (using the usb plugin) but it doesn't seem to be communicating with the system in the correct manner to get a ttyUSB assignment so I can use it in the plugin.
-
Any progress on this? I have an AX1600i and would love this for it. Thanks for all your work!
-
I’m glad my troubleshooting translated into some useful outcomes for others! We still regularly game on our system, it’s been stable and fast for us. I wish you both best of luck with your systems as well!
-
I sold the original and have a Sage wifi II now. As far as I recall there are several IOMMU settings in different sections. Just look for anything IOMMU and virtualization related. If you had a SAGE II I can give you my mobo settings.
-
To Follow Up - the VIDEO_DXGKRNL_FATAL_ERROR was actually because of AquaComputer's Aquasuite - turns out that they have some video and audio services that try to access low-level resources in the system and cause the Graphics subsystem to crash - once these are disabled the problem goes away. I still have the BAR issues and a nasty hard-lock crash detailed here.
-
Thanks for the reply! To clarify - if I do that with SR-IOV off, one of the GPUs (and probably some other devices, I haven't looked that close) does not show up in Unraid. If I do it with it on, the BAR errors are still present. For sake of completeness, I've attached new diagnostics with `pci=realloc=off` in the bootstring tower-diagnostics-20230104-1205.zip
-
Hello! I've been experiencing some wonkiness with my Unraid server, including hard locks that take out the VMs [displays go black], the HTTP interface, and SSH. In the logs I'm seeing many lines of: Jan 4 10:49:11 Tower kernel: pci 0000:00:03.1: BAR 15: no space for [mem size 0x00600000 64bit pref] Jan 4 10:49:11 Tower kernel: pci 0000:00:03.1: BAR 15: failed to assign [mem size 0x00600000 64bit pref] Jan 4 10:49:11 Tower kernel: pci 0000:00:03.1: BAR 13: no space for [io size 0x2000] Jan 4 10:49:11 Tower kernel: pci 0000:00:03.1: BAR 13: failed to assign [io size 0x2000] Jan 4 10:49:11 Tower kernel: clipped [mem size 0x00000000 64bit pref] to [mem size 0xfffffffffffc0000 64bit pref] for e820 entry [mem 0x000a0000-0x000fffff] Jan 4 10:49:11 Tower kernel: clipped [mem size 0x00020000 64bit pref] to [mem size 0xfffffffffffe0000 64bit pref] for e820 entry [mem 0x000a0000-0x000fffff] Jan 4 10:49:11 Tower kernel: pci 0000:00:03.1: BAR 15: no space for [mem size 0x00200000 64bit pref] Jan 4 10:49:11 Tower kernel: pci 0000:00:03.1: BAR 15: failed to assign [mem size 0x00200000 64bit pref] Jan 4 10:49:11 Tower kernel: pci 0000:00:03.1: BAR 13: no space for [io size 0x2000] Jan 4 10:49:11 Tower kernel: pci 0000:00:03.1: BAR 13: failed to assign [io size 0x2000] It's almost like Unraid is booting in 32bit mode or something and running out of memory space - although I wouldn't think this is possible. In a previous post here, I detailed some attempts at workarounds I made to get the system to boot, but no combination of pci=realloc=off, SR-IOV, and my motherboard's PCIe settings can seem to resolve this. Either I get a partial boot (pci=realloc=off for example, I lose a GPU) or none of the drives/gpus are visible. Memory test came out perfectly clean - no errors in SMT or normal mode. Most of the attached hardware was in my previous 1950X Threadripper build, which was solid as a rock. I'm appreciate any help. I have a syslog server up on a raspberry pi to try and catch one of the crashes directly if possible, but I am thinking that all these PCIe issues can't be helping. tower-diagnostics-20230104-1113.zip
-
So after much testing and experimentation it appears that the actual install of Windows is broken - Win11 install is a straight beast on the new hardware and solid as a rock. It could also be that running it off of the M.2 to PCIe slot adapter is broken, I'm not sure which. I'm not sure which. As an experiment, I'm going to rip the drive to a QEMU disk image and boot from that. I'll keep recording my journey here for posterity in case it helps someone else.
-
So there is another level of complexity here. Turns out SR-IOV support is the one actually solving this. Without it on, the symptoms return. If you have BME DMA Mitigation on then when you pass through the cards, they won't return to the system (and can't be reset). However now I error out of windows hard when trying to game. First it games fine (I'm hitting my monitor refresh in Deep Rock Galactic) but then I get a VIDEO_DXGKRNL_FATAL_ERROR - after some tinkering I now get one when shutting down and the video card will not return to the system when this happens, but I can still boot. Going to load up a blank Windows 11 install and see if it has the same issues.
-
Having experimented in the BIOS, I was able to boot with full functionality and without the `pci=realloc=off` by going into my PCI Subsystem settings and changing the following settings: 1) Above 4G Decoding - ENABLED 2) Re-Size BAR Support - AUTO 3) SR-IOV Support - ENABLED 4) BME DMA Mitigation - DISABLED [Edit - See below for explanation] 5) Hot-Plug Support - DISABLED It's also worth noting I'm not booting in EFI - I prefer the way the onboard ASPEED VGA outputs a functional console in legacy boot.
-
Thanks for the follow up, I had to sleep a bit, but it looks like @JorgeB kindly marked your solution. I had a look again today and it also restored the USB devices. After looking at this kernel pci patch thread I'll experiment with 4G bios settings to see if I can run without this setting.
-
Yes! That worked! What exactly does that do, and how would one go about figuring out they need it in the absence of wonderful people like you? (i.e. - Is there a list of boot options and their functions?)
-
No worries, just trying to be very clear what I attempted for posterity.
-
I tried disabling IOMMU first (it's a separate setting - or rather a half dozen - on my board) and then SVM. No change. For the record, booting into Windows (I had a disposable install on one of the NVMe's that going to be in the cache) with current settings shows all devices as expected. So this is an Unraid only issue - the hardware itself seems to be working fine.
-
Hello - and thanks for taking a peek! I'm running into an issue even though I can see my 6 SATA Drives and 3 NVME drives on the BIOS Post screen, they only two of the NVME Drives show up in the OS itself. I'm also noticing that none of the USB devices attached to the system aside from the boot drive are visible, including USB drives plugged in after boot. An NVMe drives plugged into a PCIe slot via PCIe -> M.2 Adapters did appear. What's even weirder is that the third "missing" NVMe controller does seem to show up, but it doesn't appear as a drive. The motherboard is a Pro WS WRX80E-SAGE SE WIFI with an AMD Threadripper Pro 5965WX with 128GB of system RAM installed and no PCIe slot devices installed at the moment (for testing). I've tried making a new Unraid USB - they boot fine but do not resolve the issue. I see a lot of pci 0000:22:06.0: BAR 14: failed to assign -type messages in the SysLog so I'm going to fiddle with the ram a bit and see if I have a bad stick or something since it's my understanding that bad ram can cause this. Worth a shot. Diags [Edit: from Safe Mode] attached. tower-diagnostics-20221228-2321.zip
-
You have no idea how helpful this was to me. You are a lifesaver. I have what I now know is a bad board - I was 60% sure and this post made me 100% sure. It wouldn't boot with any GPUs in (at all) and was doing some really weird stuff otherwise. I've previously tested the GPUs in other systems, and the RAM came from a functioning Unraid server. The BMC won't respond either. I took all the GPUs out, and it'd boot into Unraid, but no SATA devices showed up and one of the NVMe drives mounted on the board didn't show up either. But somehow the SATA controllers did? Your post confirms that my motherboard is just hosed and not somehow incompatible with Unraid, as you have the exact board and processor I have on the same BIOS revision. Thank you, from the bottom of my heart! 🥰
-
Do you still need to have the extra root hub verbage in the xml?
-
Unraid has been an absolute lifesaver when it comes to managing my home tech infrastructure. I’ve consolidated so much into one system it’s not even funny. And the support you guys give to your users is unreal.
-
@binhex - Found a solution for that scanning issue that I had to manually lock Plex back to 1.14 for. (It was a while back.) Edit: The problem showed up in the logs only as Jun 03, 2019 14:55:55.967 [0x151e50971740] WARN - Scanning the location /media/[Library Name] did not complete Jun 03, 2019 14:55:55.967 [0x151e50971740] DEBUG - Since it was an incomplete scan, we are not going to whack missing media. One of my scanners (Hama) was silently failing on certain files. I had to put a bunch of debugs into the .py files to sort it, but once I realized that the latest version from the GitHub solved it. So if you encounter someone with scanning issues, have them refresh all their scanners/plugins. I'll try to keep an eye out myself.
-
If you’ve manually specified a version other than latest.
-
Ouch. Yeah, I'm very happy with your docker image and knowing we can roll back easily is just icing on the cake.
-
Firstly, thank you for your response. Second, I appreciate the education; I wasn't aware plex pass was a form of beta, but that makes sense now that you've said it. I'll see what I can do through official channels, but thank you again for your time and providing this great container in the first place.
-
The latest Plex container would not scan for, nor detect changes to, my library items. Manual scans would immediately terminate, and manual scanning was not required prior to the latest un-tagged versions. Rolling back to 1.14.1.5488-1-01 immediately rectified the problem and found the library items I've added since updating to the 'latest' version. I'm available for debugging purposes if you are interested @binhex. Judging by responses on the official Plex forums this may be an issue in the official release, but most of the threads I'm finding are referencing the Mac OSX version. Edit: Your container has been excellent one for many moons for me though. Just wanted to give my praise as well.
-
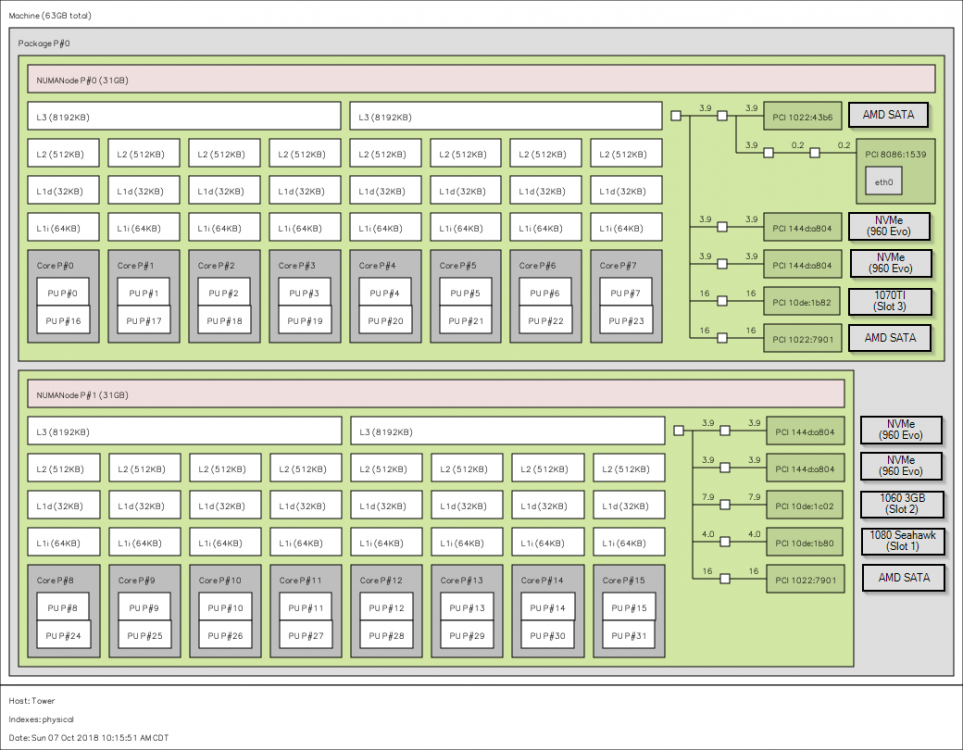
Awesome video. I'd like to note that in "independent research" I got hwloc/lstopo included with the GUI boot in Unraid 6.6.1. So that's another option requiring about the same number of reboots as the script method. I.e. - Reboot into GUI, take snapshot, reboot back to CLI. Of course if you run GUI all the time, this is just a bonus for you. Also, here is a labeled version of the Asus x399 ZE board in NUMA mode. Enjoy, and thanks @SpaceInvaderOne! (Note: this is with all M.2 slots and the U.2 4x/PCIE 4x split enabled with installed media. Slot numbers are counting by full-length slots in order of physical closeness to CPU socket... so top down for most installs)