




sinbrkatetete
Members
-
Joined
-
Last visited
Everything posted by sinbrkatetete
-
if it's not too hard, it would be great if you could provide a way to set PUID/PGID; if it's already possible, would you be so kind as to share how. thanks in advance
-
Does it still work for you? I was running it on secondary NIC also, for quite a while on port 80. (worked somehow without the BIND_ADDRESS "key"). A week or so (maybe more, I'm bad with time), after an update it reverted to 8080 and won't budge whatever I do. Is there a specific format I need to use for [IP]:[PORT] in the BIND_ADDRESS? THanks in advance. EDIT: I'm obviously not as good of a reader as I've immagined myself to be... In any case, if anyone wonders the new "keys" are GRANIAN_HOST and GRANIAN_PORT. Sorry for taking up space.
-
hey, in the same boat it seems, albeit a year and a half later. did you manage to find a way to get it working? mind sharing how? tia
-
OK, so I went back and checked everything from the start. Saw that user share assignment was disabled on cache, enabled it and all the shares (re)appeared. So if anyone gets in the same mess as I did - that was the solution for me. Thanks to anyone who spent even a second looking at my troubles.
-
I'm sorry, I'll include it in the original post. To tell you the truth, I though I was helping by listing only what I thought was relevant from the diagnostics package. About the "missing share names", they're not missing, they have been clumsily "redacted" in my attempt to be as private as possible. To hell with it, it'll all be seen in the diagnostics anyway. Thanks for your time. If you find it in yourself to take another look, now I've posted the diagnostics, I'd be very garetful. Thanks in advance.
-
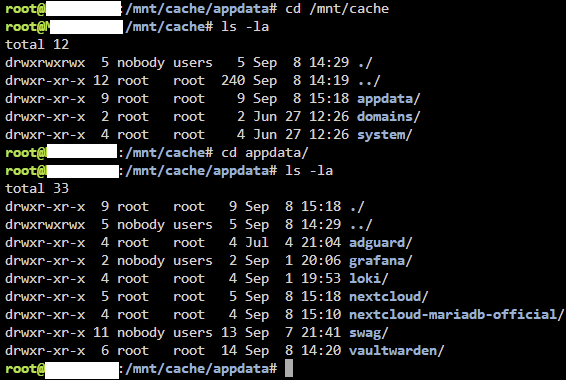
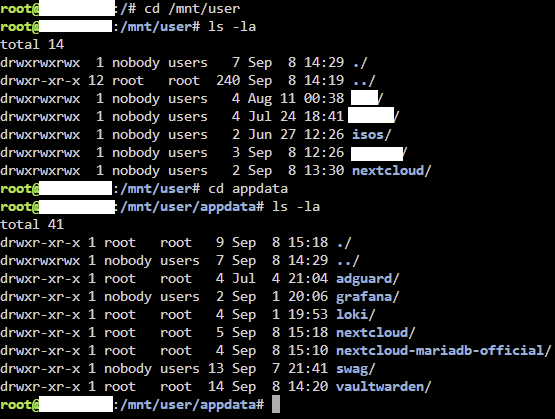
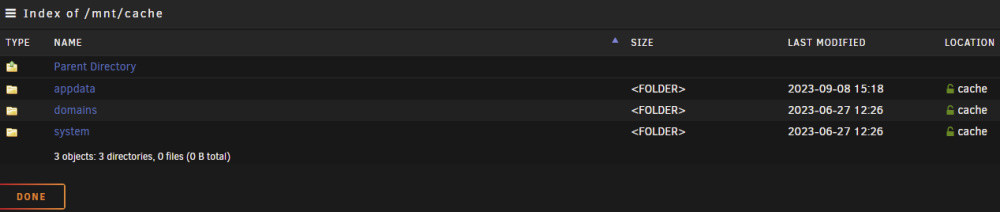
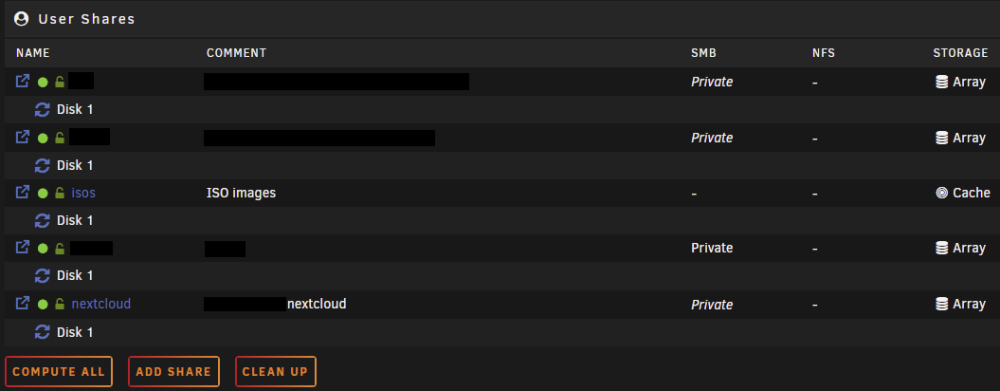
Hello, thanks in advance to anyone reading this with an inclination to help out; also, sorry for the long post. So, slowly setting up UNRAID 6.12.4 (first installed @ 6.12.3 version, upgraded recently) on a retlatively modern machine to replace my ageing i3-4330 CPU with 8 GB of RAM that served me and my family for years. The disks on the new one are setup as one zfs-enrypted drive in an array with an identical drive as parity, one cache disk formated as zfs. At first, while setting up the server, I kind of missed the fact that "appdata", "domains" and "system" share were missing from the GUI and then thought it was because I disabled VM and docker to be able to play with network settings and get them configured according to my need and my existing network environment and that they (the forementioned shares) would appear once I enabled the VM and docker service. I was wrong. Here's the config (appdata.cfg), as I've found it in the "diagnostics package" of the "appdata" share (the "domains" and "system" configs are identical except for the filename): # Share exists on cache # Generated settings: shareComment="..." shareUseCache="prefer" shareCachePool="cache" shareCOW="auto" shareSplitLevel="1" shareExport="-" and the share(s) itself/themselves are indeed located on the cache drive according to the GUI browser , but accesible both through /mnt/cache/appdata (or /domains or /system) and /mnt/user/appdata (or /domains or /system) in the terminal; probably because they're set to cache "preferred" instead of "only" as I'd prefer or? through cache: through user: The only "default" share present in the GUI is the "isos" share, for which the "isos.cfg" # Share exists on disk1 # Generated settings: shareComment="..." shareInclude="" shareExclude="" shareUseCache="only" shareCachePool="cache" shareCOW="auto" shareAllocator="highwater" shareSplitLevel="" shareFloor="" shareExport="-" shareFruit="no" shareCaseSensitive="auto" shareSecurity="public" shareReadList="" shareWriteList="" shareVolsizelimit="" shareExportNFS="-" shareExportNFSFsid="0" shareSecurityNFS="public" shareHostListNFS="" differs from what's (pre?)set in the GUI: The funny thing is, when I go and try and change the primary storage, I dont't seem to be able to (re)select cache. Through the cli, the "isos" directory/folder/however it's called is accessible only via /mnt/user/isos. Please help.
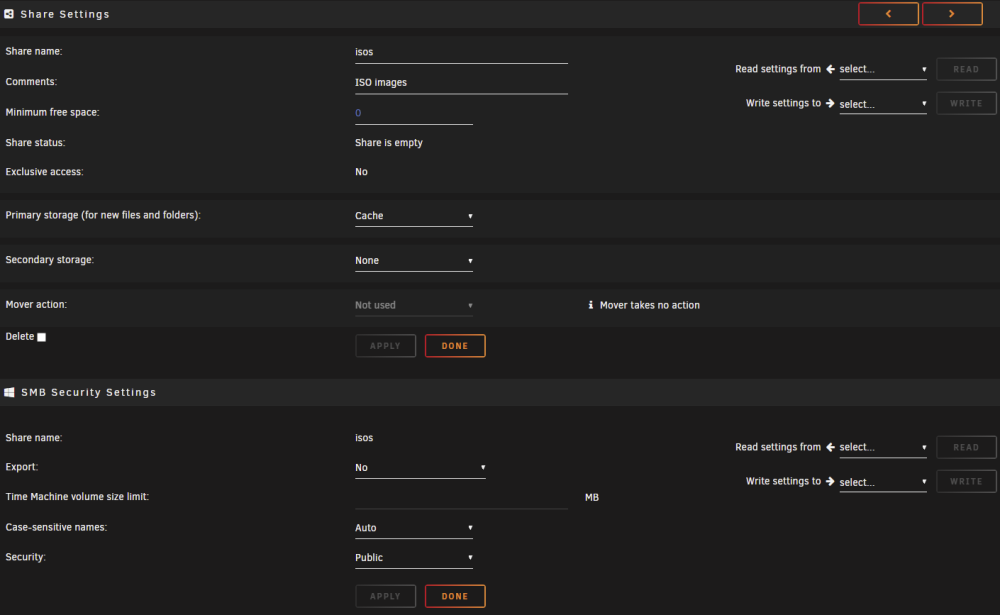
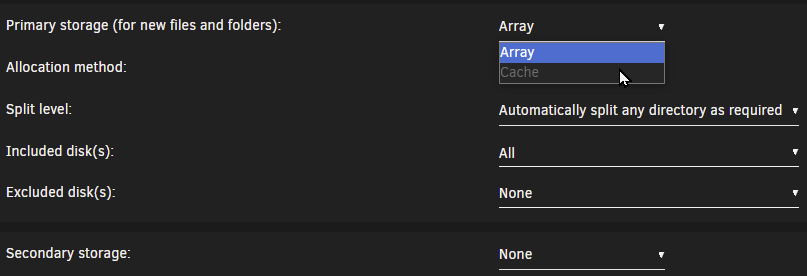
-
Re torprivoxy (alpine) docker. I've seen obfs4 bridge configuration (support) was added through environment variable(s). Could you (anyone) please help me set it up? namely, I don't know how to name the variable(s), can there be more at the same time, how to set for instance three obfs4 bridges, or snowflake if that was added also. Thanks for help in advance
-
As far as I understand this letsencrypt/nginx concoction, it has three primary purposes. The first one is to deal with issuing/refreshing the certificates provided by letsencrypt, the second one is encrypting/decrypting/authenticating the network traffic and the third one is reverse-proxying. In my mind, it's primary purpose is to provide a secure transport mean for your data - preventing eavesdropping / modifying the data transported by encryption and authentification. The great part about nginx reverse http(s) proxying is that you can have just one port opened to the world and forwarded to wherever nginx is running and reverse-proxy the traffic to countless internal addresses. It seems, however, nginx can't proxy non http(s) traffic the same way it does with http(s). One of the details that reinforced my conviction was the (commented out) part of the nginx.conf concerning mail. So, as far as http(s) traffic is concerned, everything can be dealt with with a config in the "sites-whatever" folder, utilizing either the "subdomain" or the "subpages" setup (as we're both doing with our other dockers) - forwarding it either decrypted or encrypted to the internal address responding to the requested one. And just one port opened and forwarded to letsencrypt's docker is enough for any amount of internal addresses. Unfortunately, the non http(s) traffic (possibly because other types don't format their requests/data the same way or don't support/need/use some of the things http(s) does) has to be dealt with this "streams" thingy. And it seems it has to have a port forwarded to the letsencrypt/nginx docker for every internal address being served/proxied to. As far as I understand, and please someone correct me if I'm wrong, you're not losing the critical part of the setup - the authentication/encryption by forwarding another port to the letsencrypt docker, as you would if you forwarded ports directly to individual dockers (provided, of course, you didn't setup individual "secure connections" on each and every one of them), your traffic is still being encrypted/decrypted/authenticated/proxied by letsencrypt/nginx, it's just that you need another "point of entry" to the letsencrypt/nginx docker because nginx doesn't know where to direct the mqtt traffic if it comes in with the "normal" http(s) (because mqtt, it seems, can't say www). You need to "distinguish" it somehow so you can direct nginx what to do with, where to forward it, and you do it by giving it to nginx on a separate port. You're not bypassing anything. I don't think having just 80 and 443 ports forwarded to letsencrypt docker makes you any more secure/resistant than you'd be if you forwarded another port to the same place. It's not the open ports that are/can be a problem, it's where they're forwarded to. So, as far as I know, this setup is providing me with the same level of (in)security I had with only ports 80 and 443 forwarded to letsencrypt/nginx with just a small level of inconvenience because I need another port forward rule (and port opened) for every non http(s) traffic I wish to proxy, better said - for every client I wish to forward non-http(s) traffic to. So, TL;DR: as long as you forward port 8883 to the letsencrypt/nginx docker, and from there proxy unencrypted to 1883 port of your mqtt docker (which is what my config does, I hope), you're not bypassing anything, you won't be any less secure than you are now. It's simply that you need to distinguish the non http(s) traffic to nginx somehow and, since it's not speaking the same language, you distinguish it by giving it another port to enter through.
-
Sorry for taking so long to respond... EDIT (reread your conf): FIRST SKIP TO THE END OF MY POST, then read everything else if it still interests you. I'm not sure what could go wrong if you forwarded the port 8883 correctly to your letsencrypt docker and set the MQTT docker to expect/accept connections on port 1883. Are your credentials OK? BTW, I repeat, I'm a total noob in thiese "fields" but could the problem be in a "tab too much" - why are your ssl_certificate_key and ssl_dharam indented further than ssl_certificate? Here's my nginx.conf: user abc; worker_processes 4; pid /run/nginx.pid; include /etc/nginx/modules/*.conf; events { worker_connections 768; # multi_accept on; } http { ## # Basic Settings ## sendfile on; tcp_nopush on; tcp_nodelay on; keepalive_timeout 65; types_hash_max_size 2048; # server_tokens off; # server_names_hash_bucket_size 64; # server_name_in_redirect off; client_max_body_size 0; include /etc/nginx/mime.types; default_type application/octet-stream; ## # Logging Settings ## access_log /config/log/nginx/access.log; error_log /config/log/nginx/error.log; ## # Gzip Settings ## gzip on; gzip_disable "msie6"; # gzip_vary on; # gzip_proxied any; # gzip_comp_level 6; # gzip_buffers 16 8k; # gzip_http_version 1.1; # gzip_types text/plain text/css application/json application/x-javascript text/xml application/xml application/xml+rss text/javascript; ## # nginx-naxsi config ## # Uncomment it if you installed nginx-naxsi ## #include /etc/nginx/naxsi_core.rules; ## # nginx-passenger config ## # Uncomment it if you installed nginx-passenger ## #passenger_root /usr; #passenger_ruby /usr/bin/ruby; ## # Virtual Host Configs ## include /etc/nginx/conf.d/*.conf; include /config/nginx/site-confs/*; ssl_protocols TLSv1 TLSv1.1 TLSv1.2; ssl_ciphers "EECDH+AESGCM:EDH+AESGCM:AES256+EECDH:AES256+EDH"; ssl_prefer_server_ciphers on; ssl_session_cache shared:SSL:10m; add_header Strict-Transport-Security "max-age=15768000; includeSubDomains; preload;"; add_header X-Frame-Options SAMEORIGIN; add_header X-Content-Type-Options nosniff; add_header X-XSS-Protection "1; mode=block"; add_header X-Robots-Tag none; ssl_stapling on; # Requires nginx >= 1.3.7 ssl_stapling_verify on; # Requires nginx => 1.3.7 ## # Added from Reddit prescription ## map $http_upgrade $connection_upgrade { default upgrade; '' close; } } stream { upstream mosquitto { server 192.168.4.2:1883; } server { listen 8883 ssl; proxy_pass mosquitto; ssl_certificate /config/keys/letsencrypt/fullchain.pem; ssl_certificate_key /config/keys/letsencrypt/privkey.pem; ssl_dhparam /config/nginx/dhparams.pem; } } #mail { # # See sample authentication script at: # # http://wiki.nginx.org/ImapAuthenticateWithApachePhpScript # # # auth_http localhost/auth.php; # # pop3_capabilities "TOP" "USER"; # # imap_capabilities "IMAP4rev1" "UIDPLUS"; # # server { # listen localhost:110; # protocol pop3; # proxy on; # } # # server { # listen localhost:143; # protocol imap; # proxy on; # } #} daemon off; As you can see from the conf, my MQTT server is at 192.168.4.2, listening on port 1883; the letsencrypt/nginx is expecting connections at port 8883. Here are my settings for the MQTT server hassio addon: { "plain": true, "ssl": false, "anonymous": false, "logins": [ { "username": "blabla", "password": "blablapassword" }, { "username": "clacla", "password": "claclapassword" }, { "username": "dladla", "password": "dladlapassword" }, { "username": "elaela", "password": "elaelapassword" }, { "username": "flafla", "password": "flaflapassword" }, { "username": "glagla", "password": "glaglapassword" } ], "customize": { "active": false, "folder": "mosquitto" }, "certfile": "fullchain.pem", "keyfile": "privkey.pem" } -> READ THIS FIRST! Now, that I came to this part of your post about your MQTT client conf: What port(s) have you forwarded to your letsencrypt/nginx container from the "outside"?? If you've followed the same principles as I did, you should have forwarded port 8883 on your router to your letsencrypt/nginx container which would mean you should set it as the port your MQTT client is connecting to - Port: 8883, not 1883. I'm not "at home" with owntracks, but you could check if there's something like "Secure MQTT" besides "Private MQTT" because of the next problem with your Owntracks config... I believe the next part of the problem is the "No" by the TLS... Did you try using TLS 1.2? Since,, from your MQTT client perspective, you are in fact connecting through a "secure connection" I don't think this is the right option here. Is there an option in Owntracks to set SSL/TLS connection? Lastly, about the (sub)domains. I have four subdomains "registered" @ duckdns.org, let's call them - sub1.duckdns.org etc. I've set up my duckdns container to keep the IPs updated and the letsencrypt/nginx docker to obtain certificates for those four subdomains and forward connections like - entering "https://www.sub1.duckdns.org" will get you to my Hassio UI login, entering "https://www.sub2.duckdns.org" will get you to my Nextcloud UI also that's the subdomain I enter into the Nextcloud clients to connect. sub3 is there for the mqtt connection, sub4 is still unused, it's reserved for video surveilance or something like that. Anyway, everything works as expected, entering the address of the subdomain gets me exactly where I'm supposed to get but the MQTT connection works no matter which of the four registered subdomains I enter into the client config; sub1.duckdns.org:8883 works as well as the sub2.duckdns.org:8883, sub3... you get the point. I hope I've helped at least a bit. If I were you, I'd concentrate on the "TLS:'No'" setting and the indentation in nginx.conf, but mostly on the former. Good luck
-
Hey @keepitshut I'm seeing the same problem with an ubuntu desktop 17.10 VM. I've managed to create and destroy more than a couple of ubuntu VMs with the same install iso and small variations in settings (disk / ram size) during last week or two, but today I'm trying to create one, all the same settings that worked before and keep getting the same error as you... 2018-03-11 15:45:19.209+0000: starting up libvirt version: 3.8.0, qemu version: 2.10.2, hostname: BLABLABLA LC_ALL=C PATH=/bin:/sbin:/usr/bin:/usr/sbin HOME=/ QEMU_AUDIO_DRV=none /usr/local/sbin/qemu -name guest=Blabla,debug-threads=on -S -object secret,id=masterKey0,format=raw,file=/var/lib/libvirt/qemu/domain-9-Blabla/master-key.aes -machine pc-q35-2.10,accel=kvm,usb=off,dump-guest-core=off,mem-merge=off -cpu host -drive file=/usr/share/qemu/ovmf-x64/OVMF_CODE-pure-efi.fd,if=pflash,format=raw,unit=0,readonly=on -drive file=/etc/libvirt/qemu/nvram/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx_VARS-pure-efi.fd,if=pflash,format=raw,unit=1 -m 2560 -realtime mlock=off -smp 1,sockets=1,cores=1,threads=1 -uuid xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx -no-user-config -nodefaults -chardev socket,id=charmonitor,path=/var/lib/libvirt/qemu/domain-9-Blabla/monitor.sock,server,nowait -mon chardev=charmonitor,id=monitor,mode=control -rtc base=utc,driftfix=slew -global kvm-pit.lost_tick_policy=delay -no-hpet -no-shutdown -boot strict=on -device pcie-root-port,port=0x10,chassis=1,id=pci.1,bus=pcie.0,multifunction=-0,id=sata0-0-0,bootindex=2 -netdev tap,fd=27,id=hostnet0,vhost=on,vhostfd=30 -device virtio-net-pci,netdev=hostnet0,id=net0,mac=xx:xx:xx:xx:xx:xx,bus=pci.1,addr=0x0 -chardev pty,id=charserial0 -device isa-serial,chardev=charserial0,id=serial0 -chardev socket,id=charchannel0,path=/var/lib/libvirt/qemu/channel/target/domain-9-Blabla/org.qemu.guest_agent.0,server,nowait -device virtserialport,bus=virtio-serial0.0,nr=1,chardev=charchannel0,id=channel0,name=org.qemu.guest_agent.0 -device usb-tablet,id=input0,bus=usb.0,port=1 -vnc 0.0.0.0:0,websocket=5700 -k hr -device qxl-vga,id=video0,ram_size=67108864,vram_size=67108864,vram64_size_mb=0,vgamem_mb=16,max_outputs=1,bus=pcie.0,addr=0x1 -device virtio-balloon-pci,id=balloon0,bus=pci.4,addr=0x0 -msg timestamp=on 2018-03-11 15:45:19.209+0000: Domain id=9 is tainted: high-privileges 2018-03-11 15:45:19.209+0000: Domain id=9 is tainted: host-cpu 2018-03-11T15:45:19.260508Z qemu-system-x86_64: -chardev pty,id=charserial0: char device redirected to /dev/pts/1 (label charserial0) Did you manage to find out anything useful about our shared problem? Please share. EDIT: A restart was all it took. Seems I've gone all fussy way too early. EDIT2: Seems I celebrated too early. After a VM restart I can login and then - blank screen. Error in log: ((null):25009): SpiceWorker-Warning **: red_worker.c:163:rendering_incorrect: rendering incorrect from now on: get_drawable EDIT3: Looks like changing the clients resolution causes the rendering incorrect thingy.
-
So... I've "made it" work. Simply copying the conf from this post and adjusting the upstream server, the ssl_certificate, ssl_certificate_key and ssl_dhparam to my locations did the trick. I simply copy-pasted the conf to the nginx.conf file, right after the http config, before the commented out mail config. The thing is, I don' t know how to "bind" it to one of the subdomains I have certs for. As it is now, my mqtt clients connect by using any of the three subdomains the duckdns.org docker is "following" @ port 8883. I don't know if it's possible to "bind" it somehow to a subdomain, I don't have too much time on my hands atm, so I'll probably investigate further sometime in the future. For now, I'm happy all my clients can connect to it. I hope it's secure, since I don't know how to test.
-
I'm trying to get mqtt to work through one of the duckdns subdomains I have certified through letsencrypt, proxied through nginx. My nextcloud is accessible through its own subdomain, hassio ui through its own, I just can't get mqtt to work. What's different from your case is the fact I'm using a duckdns docker and a letsencrypt docker on unraid and trying to get through to a mqtt server / addon on hassio, running on a separate pi. Also, I don't know about you, but I'd like the decryption to happen on the letsencrypt docker and the local connection to the mqtt server to be unencrypted. Before I forget, a word of caution, I'm a total noob, some/most/all of the things I write might be total bs, I don't know almost anything on the subject, also - it's seven hours past my bedtim; (re)investigate everything for yourself. Back to the point. First of all, it seems "sites-whatever" isn't meant for non-https proxying with nginx. And mqtt isn't http(s). As far as I could gather from a couple of posts I've dug up on the subject is you have to use something called "stream(s)" to accomplish proxying mqtt (tcp) to your server and the "config" for that has to be in the same folder nginx.conf is (the parent folder of "sites-whatever"). Here is a link or two I found on the subject... I plan on fiddling with it saturday afternoon, if I manage to get it working, I'll let you know. The links: https://community.home-assistant.io/t/mqtt-through-nginx-and-owntracks/4943/35 , http://akeil.de/posts/mqtt-bridge-with-mosquitto-and-nginx.html, https://www.nginx.com/blog/nginx-and-iot-adding-protocol-awareness-for-mqtt/ , https://www.nginx.com/blog/nginx-plus-iot-load-balancing-mqtt/ , https://serversforhackers.com/c/tcp-load-balancing-with-nginx-ssl-pass-thru there's also this one if you're planing to use websockets https://community.home-assistant.io/t/mqtt-through-nginx-and-owntracks/4943/8
-
hi! do I have any chance of setting it up so it connects through a socks5 proxy? thanks in advance
-
Howdy all! A question concerning CUPS... A total unraid & docker noob here... Has anyone had any success getting the CUPS docker working with a printer using the parallel port (LPT?)?. I've managed to get the usb printer going but I have an old Canon BJC5500 printer (A2) that I need and can't find a way to use. CUPS doesn't list neither of the three parallel ports I have on the machine, nor does it find the printer attached. Would a more sensible route be to setup a WinXP VM and somehow pass-through the parallel port (card) to it? Can it be done? Since I can't find anything on getting the parallel port working on unraid (docker)... it seems that may be the route worth investigating. Thanks in advance EDIT: Found out my old box doesn't support VT-d... So it's either this or RPi print server of some kind. Any chance anybody could/would want to help with this docker?





