




PsyCl0ne
Members
-
Joined
-
Last visited
Everything posted by PsyCl0ne
-
Thank you JorgeB, always coming in clutch, really appreciate you. :)
-
bump
-
In Fix Common Problems its reporting the following: Machine Check Events detected on your server >> Your server has detected hardware errors. The output of mcelog has been loggeg. Post your diagnostics and ask for assistance on the Unraid forums More Information Would appreciate a pair of eyes on my diag logs. Thank you in advance! tower-diagnostics-20260519-1858.zip

-
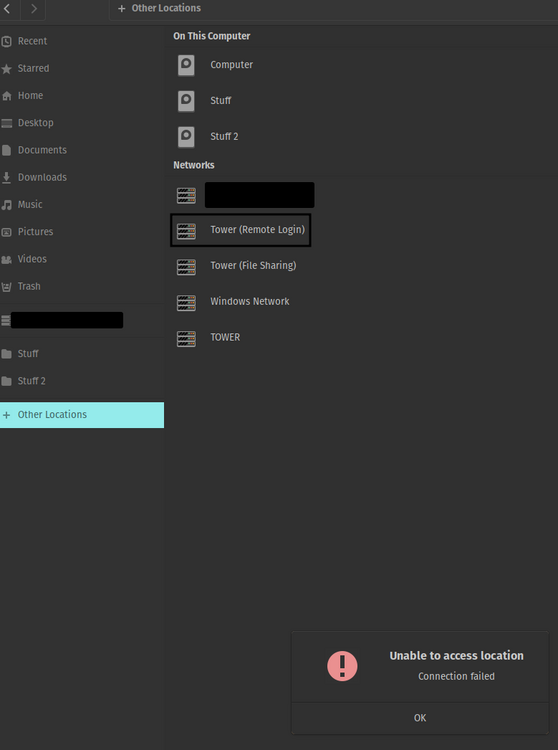
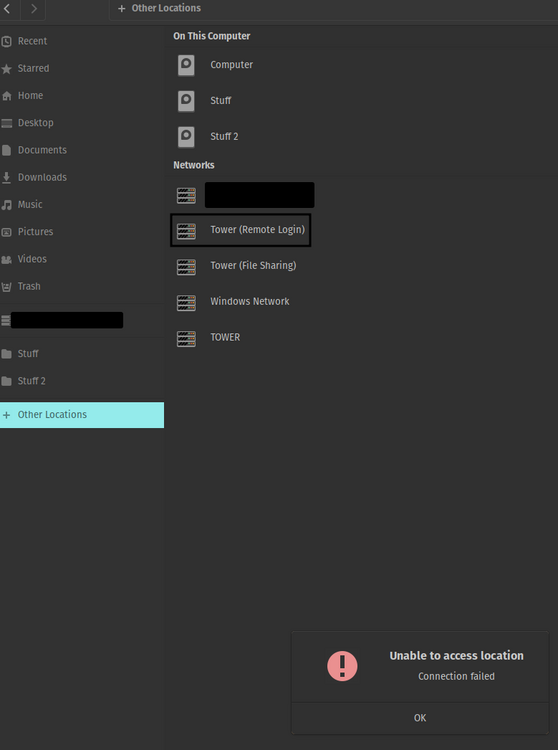
Yes, the one labelled Tower (File Sharing), which brings me into "/storage/(I am unsure if its user or user0)/data" directory. Opening up this directory in terminal shows the following: ***username***@pop-os:/run/user/1000/gvfs/smb-share:server=tower.local,share=data$
-
If I remember correctly it wasnt even directly to /mnt/user it was to just /. Exactly this except in my file explorer... Ive gone through all the plugins I have and don't see anything that would enable this remote login from my popOS desktop. I don't have any scripts running that would enable that either. Is there anyway that I could work backwards to sort this out?

-
I dont think so lol. Im not sure what could have enabled root share as I'm certain I've had this root share available since I first started with unraid.

-
Hi everyone, I recently upgraded to Unraid 7.2.2 recently and just realized that I am unable to connect to my root share through popOS's file explorer. Normally I would be able to click on the share (see screenshot) and it would prompt for credentials, and then it would let me do what I needed without issue. Currently I dont even get a prompt before the error message comes up. I have searched through the forums a bit, and have attempted the following: -Rebooting both desktop and server -Disabling SSH access to the server and re-enabling it followed by rebooting the server -Making sure my desktop is upto date In the tower logs when I try to connect I see the following output: Dec 9 13:35:47 Tower sshd-session[1740399]: Connection from 192.168.1.73 port 36188 on 192.168.1.115 port 22 rdomain "" Dec 9 13:35:48 Tower sshd-session[1740399]: User ***USERNAME*** from 192.168.1.73 not allowed because not listed in AllowUsers Dec 9 13:35:48 Tower sshd-session[1740399]: fatal: PAM user mismatch Dec 9 13:35:48 Tower sshd[1418008]: srclimit_penalise: ipv4: new 192.168.1.73/32 deferred penalty of 1 seconds for penalty: connections without attempting authentication Dec 9 13:36:24 Tower sshd-session[1740980]: Connection from 192.168.1.73 port 51354 on 192.168.1.115 port 22 rdomain "" Dec 9 13:36:24 Tower sshd-session[1740980]: User ***USERNAME*** from 192.168.1.73 not allowed because not listed in AllowUsers Dec 9 13:36:24 Tower sshd-session[1740980]: fatal: PAM user mismatch Dec 9 13:36:24 Tower sshd[1418008]: srclimit_penalise: ipv4: new 192.168.1.73/32 deferred penalty of 1 seconds for penalty: connections without attempting authentication With the error logs I notice that the username that is outputted is the same as the username I user for my desktop, I also have a users account with the same name on unraid. I've never had an issue with this prior once again because I used to get prompted for credentials, but this could be where the issue lies.... I am also unable to find anywhere on my desktop where I could have saved credentials for file explorer that might be causing issues. But honestly, I have only searched through the GUI for settings. In my screenshot there is another share from the server Tower (File Sharing) which is the windows share but that only brings me into my data share onto my server and works without issue. OS: Pop 22.04 jammy Kernel: x86_64 Linux 6.17.4-76061704-generic Uptime: 14h 22m Shell: bash 5.1.16 tower-diagnostics-20251209-1340.zip
-
Okay Ill get working on the steps I did last time. If you or anyone else have some advice, at this point I've had 3 drives act up, what should I be planning on doing next? Swapping out the Seagates with WD/Toshiba drives? Or maybe even upgrading the LSI card I have to something newer?
-
Disk 6 is the one I started the post for. Disk 5 is the new one that became disabled sometime after I posted this thread. EDIT: Added the new diagnostics zip to this post. tower-diagnostics-20240805-0148.zip
-
JorgeB, always coming in clutch, thank you. I just noticed Ive got another drive that has disabled since my initial post. Can you please verify its the same thing there as well? New diagnostics zip attached. tower-diagnostics-20240805-0148.zip
-
Hey team, I just had a drive randomly disable. It is passing SMART tests. I have experienced something similar earlier Previous similar issue post. Can I please get confirmation that its the same issue or if its something else? Thank you in advance! tower-diagnostics-20240804-1826.zip
-
Just over a week ago, I ran into the same problem that people are experiencing here with only one of my 10x 18TB drives. Followed the guide, although I only had to disable "EPC" as "Low Current Spinup" was already disabled. LSI SAS2008 Model Number: ST18000NM002J-2TV133 Firmware Revision: PAL7 World Wide Name: 5000C500E4AF671D Date Of Manufacture: Week 16, 2022 Drive Capacity (TB/TiB): 18.00/16.37 Native Drive Capacity (TB/TiB): 18.00/16.37 I've had to shut down/reboot the server a couple of times in the week, but everything seems to be running without issue. Standby has been enabled on the drive also.
-
JorgeB, thank you for your help. Apologies for the delay in updating the post, I wanted to make sure that my system was stable or not. I'll update the thread you posted with details of my drive, but as of right now after multiple reboots, as well as re-enabling sleep on the drive I have not seen any errors come back up. A side note, I only had to disable EPC on the drive as "Low Current Spinup" was already disabled on the drive. For reference, if someone is searching for the same model drive as I have: Model Number: ST18000NM002J-2TV133 Serial Number: ZR##### Firmware Revision: PAL7 World Wide Name: 5000C500E4AF671D Date Of Manufacture: Week 16, 2022 Drive Capacity (TB/TiB): 18.00/16.37 Native Drive Capacity (TB/TiB): 18.00/16.37
-
Thank you JorgeB, always appreciate you. Just some clarification as I am a bit confused. Current uptime is for the server 22 days 11 minutes. And I saw the drive being disabled maybe a couple of hours before I made the post yesterday. Prior to that, there were no warnings or errors. I still have not rebooted the server and the logs were freshly pulled. Extended SMART test for the drive is currently at 60%, but I can pull the diagnostics logs once again after completion. Second thing is I have a 12 bay chassis with a back plain, no SATA cables directly to drives. The chassis hasn't been moved or shifted since it's been powered on. Should I swap two of the drives to test, or is this maybe a one-off situation? Any other tips you could advise on for me to physically look at?
-
Hey team, Got a drive I have is showing as disabled, but it's passing a quick smart. Currently running a full test, but it's going to be a while until I see results. Can I please get a confirmation from tower diag output? tower-diagnostics-20240609-0111.zip
-
Alright I got it sorted. I dont have proof of exactly what the issue was but by doing the following I was able to get everything working. 1) As per Fix Common Problems, I went into each share, deleted the last number for "Minimum free space" put that number back and applied the change. 2) The drives that I am removing from my system since they are listed under "Unassigned Devices" I had to mount all of them and I deleted the only file that I could see which was "data" after once again checking that there were no files in them. To do this I used File Manager in the unraid GUI. 3) I unmounted the drives and stopped the array. 4) Navigating into Settings > Global Share Settings I was now able to see all the drives I am keeping listed in the drop-down menu for "Included disk(s)". I enabled them all and applied. Then I hit the Done button. 5) Started the array back up and I got one more notification from Fix Common Problems for the ISOS share. I repeated step 1 to correct that issue. 6) Confirmed that all the missing directories were now visible under /mnt/user/. 7) Stopped the array once again, went back into the Global Share Settings, deselected all the drives from the inclusion list so that it showed all. Applied the change and then hit the Done button. 8)) Started the array once more and going into every share settings I can finally see all of my array drives in the Inclusion and Exclusion drop-down menus. 9) Quick skim through my data directory, it appears to now have what I would normally have expected prior to this mess.
-
Ah kk perfect. Apologies I started to doubt my response. But I'm glad we're getting some traction on this.
-
Unraid: 6.12.10, setup to be able to complete atomic moves. A couple of nights ago I went through the shrink array guide to remove multiple drives. My array setup at the time was a total of 17 drives. #1-8 were 4TB, #9-11 were 18TB, #12-13 were 4TB, and #14-17 were 18TB. I also have 2 parity drives. The goal was to remove all but 1 of the 4TB drives. Data from each of the to be removed drives were migrated over to a 18TB drive using unbalance, and I confirmed that there was no data left on the drives by browsing to the drive to see if there was anything left over. After completing the steps in "New Config" tool, and moving over to the main tab of unraid, I removed the drives I didnt want and rearranged the drives I wanted to keep starting from Disk 1. Parity rebuild has completed. PROBLEM: Navigating to /mnt/user/data/(Any folder) I see a tiny portion of directories that I would be expecting to see. Navigating to specific disks (/mnt/disk#/data/...) all the directories and all the files that I would expect to see are there. Permissions seem to be correct all the way down from /mnt/disk#/data to whichever directory I navigate to (drwxrwxrwx+ 2 nobody users). Fix Common Problems has a bunch of errors, but I am not sure what to do with them, as the shares appear to be showing correctly instead of what I changed when starting the shrink array guide steps. Although one thing that I do see is that when selecting the inclusion drop down list, there are no drives listed to select. Screenshots of Fix Common Problems and each of the share settings are attached. Last screenshot is of the global share settings. What is it that I have missed, making this process not complete properly? tower-diagnostics-20240412-1441.zip
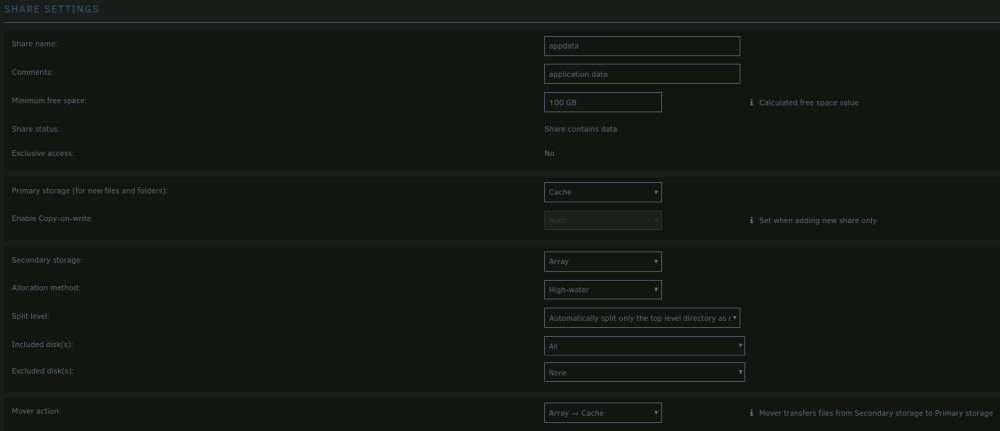
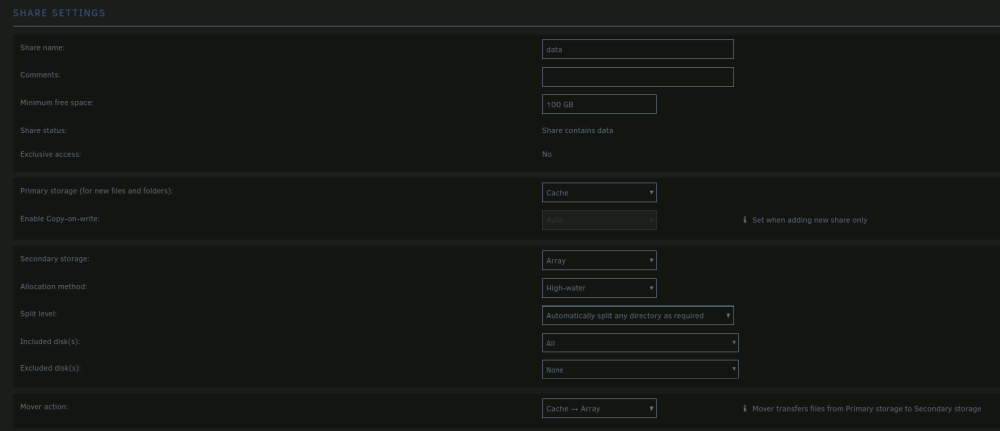
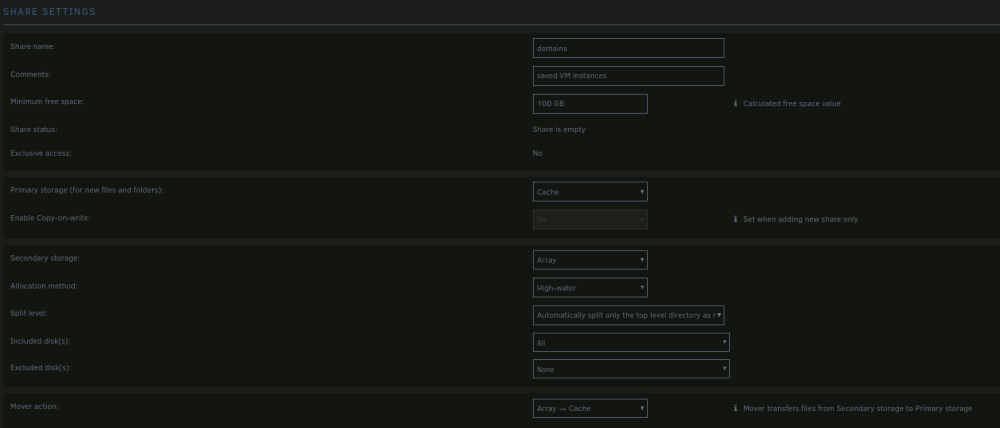
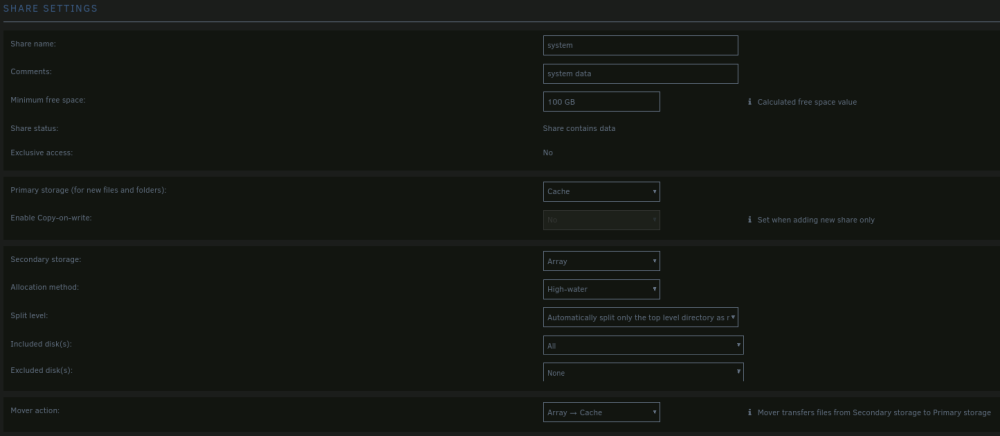
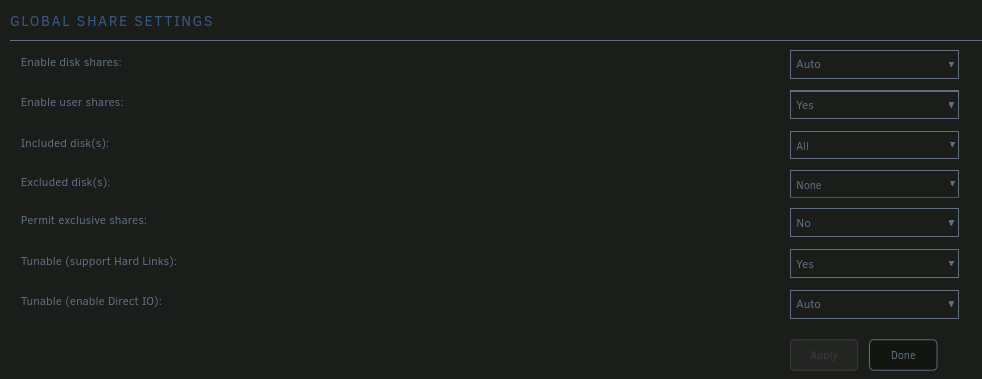
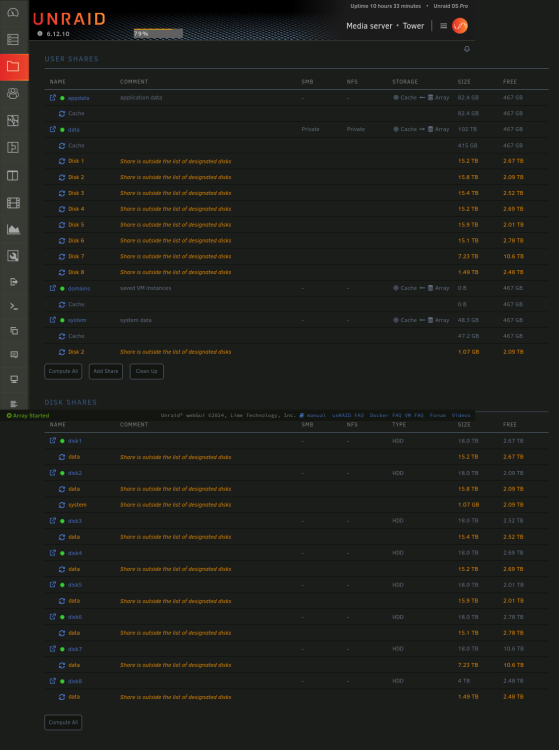

-
@JorgeB Thank you, honestly you're a godsend. Thank you for your help once again.
-
JorgeB, apologies your help has been appreciated but while I understand what you have advised I am not sure of the steps to take. I know that normally with a failed drive if I take it out and then put in a new drive, I can rebuild the array. How would it work in this situation? Do I force the system to start a rebuild or do I take the drive out and start the rebuild? Would the array rebuild onto the 4 TB drives that are still in shape? Attached are screenshots of how my "Main" tab is looking for the drives and array options. A side note when I clicked on the little icon next to the drive it pulled up Logs? and I have the following showing in it for the drive that is disabled Nov 1 05:30:04 Tower emhttpd: spinning down /dev/sdo Nov 1 06:00:01 Tower emhttpd: read SMART /dev/sdo Nov 1 07:30:04 Tower emhttpd: spinning down /dev/sdo Nov 1 08:00:01 Tower emhttpd: read SMART /dev/sdo Nov 1 08:30:23 Tower emhttpd: spinning down /dev/sdo Nov 1 09:00:01 Tower emhttpd: read SMART /dev/sdo Nov 1 10:30:03 Tower emhttpd: spinning down /dev/sdo Nov 1 11:00:16 Tower kernel: sd 8:0:1:0: [sdo] tag#2775 CDB: opcode=0x85 85 06 20 00 00 00 00 00 00 00 00 00 00 40 e5 00 Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2798 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=19s Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2798 Sense Key : 0x2 [current] Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2798 ASC=0x4 ASCQ=0x0 Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2798 CDB: opcode=0x88 88 00 00 00 00 06 33 f5 63 d0 00 00 04 00 00 00 Nov 1 11:00:20 Tower kernel: I/O error, dev sdo, sector 26641523664 op 0x0:(READ) flags 0x0 phys_seg 128 prio class 0 Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2799 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=19s Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2799 Sense Key : 0x2 [current] Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2799 ASC=0x4 ASCQ=0x0 Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2799 CDB: opcode=0x88 88 00 00 00 00 06 33 f5 5b d0 00 00 04 00 00 00 Nov 1 11:00:20 Tower kernel: I/O error, dev sdo, sector 26641521616 op 0x0:(READ) flags 0x0 phys_seg 128 prio class 0 Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2800 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=19s Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2800 Sense Key : 0x2 [current] Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2800 ASC=0x4 ASCQ=0x0 Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2800 CDB: opcode=0x88 88 00 00 00 00 06 33 f5 5f d0 00 00 04 00 00 00 Nov 1 11:00:20 Tower kernel: I/O error, dev sdo, sector 26641522640 op 0x0:(READ) flags 0x0 phys_seg 128 prio class 0 Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2801 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=19s Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2801 Sense Key : 0x2 [current] Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2801 ASC=0x4 ASCQ=0x0 Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2801 CDB: opcode=0x88 88 00 00 00 00 06 33 f5 4f d0 00 00 04 00 00 00 Nov 1 11:00:20 Tower kernel: I/O error, dev sdo, sector 26641518544 op 0x0:(READ) flags 0x0 phys_seg 128 prio class 0 Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2802 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=19s Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2802 Sense Key : 0x2 [current] Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2802 ASC=0x4 ASCQ=0x0 Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2802 CDB: opcode=0x88 88 00 00 00 00 06 33 f5 53 d0 00 00 04 00 00 00 Nov 1 11:00:20 Tower kernel: I/O error, dev sdo, sector 26641519568 op 0x0:(READ) flags 0x0 phys_seg 128 prio class 0 Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2803 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=19s Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2803 Sense Key : 0x2 [current] Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2803 ASC=0x4 ASCQ=0x0 Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2803 CDB: opcode=0x88 88 00 00 00 00 06 33 f5 57 d0 00 00 04 00 00 00 Nov 1 11:00:20 Tower kernel: I/O error, dev sdo, sector 26641520592 op 0x0:(READ) flags 0x0 phys_seg 128 prio class 0 Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2804 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=0s Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2804 Sense Key : 0x2 [current] Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2804 ASC=0x4 ASCQ=0x0 Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2804 CDB: opcode=0x88 88 00 00 00 00 06 33 f5 67 d0 00 00 04 00 00 00 Nov 1 11:00:20 Tower kernel: I/O error, dev sdo, sector 26641524688 op 0x0:(READ) flags 0x4000 phys_seg 128 prio class 0 Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2815 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=0s Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2815 Sense Key : 0x2 [current] Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2815 ASC=0x4 ASCQ=0x0 Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2815 CDB: opcode=0x88 88 00 00 00 00 06 33 f5 6b d0 00 00 04 00 00 00 Nov 1 11:00:20 Tower kernel: I/O error, dev sdo, sector 26641525712 op 0x0:(READ) flags 0x0 phys_seg 128 prio class 0 Nov 1 11:00:20 Tower emhttpd: read SMART /dev/sdo Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2761 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=0s Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2761 Sense Key : 0x2 [current] Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2761 ASC=0x4 ASCQ=0x0 Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2761 CDB: opcode=0x8a 8a 00 00 00 00 06 33 f5 63 d0 00 00 04 00 00 00 Nov 1 11:00:20 Tower kernel: I/O error, dev sdo, sector 26641523664 op 0x1:(WRITE) flags 0x4000 phys_seg 128 prio class 0 Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2765 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=0s Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2765 Sense Key : 0x2 [current] Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2765 ASC=0x4 ASCQ=0x0 Nov 1 11:00:20 Tower kernel: sd 8:0:1:0: [sdo] tag#2765 CDB: opcode=0x8a 8a 00 00 00 00 06 33 f5 67 d0 00 00 04 00 00 00 Nov 1 11:00:20 Tower kernel: I/O error, dev sdo, sector 26641524688 op 0x1:(WRITE) flags 0x4000 phys_seg 128 prio class 0 Nov 1 11:30:23 Tower emhttpd: spinning down /dev/sdo Nov 2 10:24:06 Tower emhttpd: read SMART /dev/sdo Nov 2 10:27:07 Tower emhttpd: shcmd (6623718): echo 128 > /sys/block/sdo/queue/nr_requests
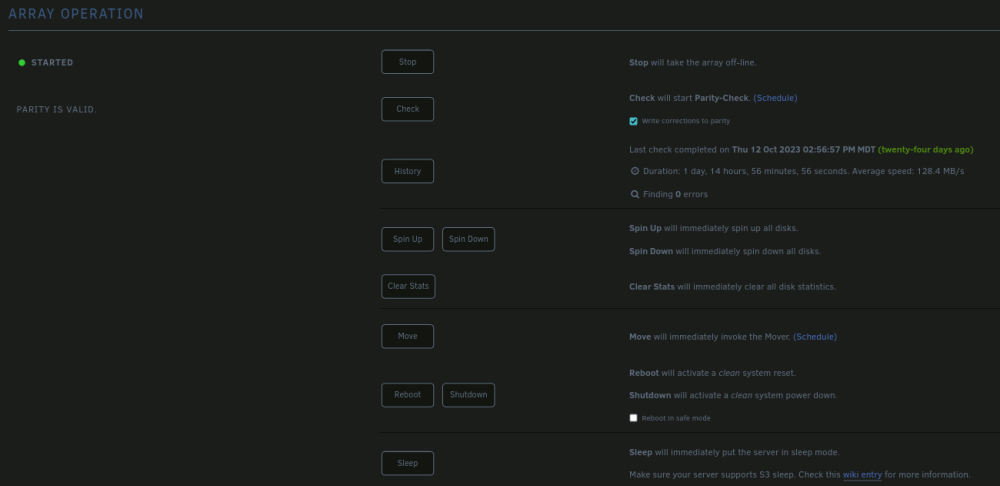
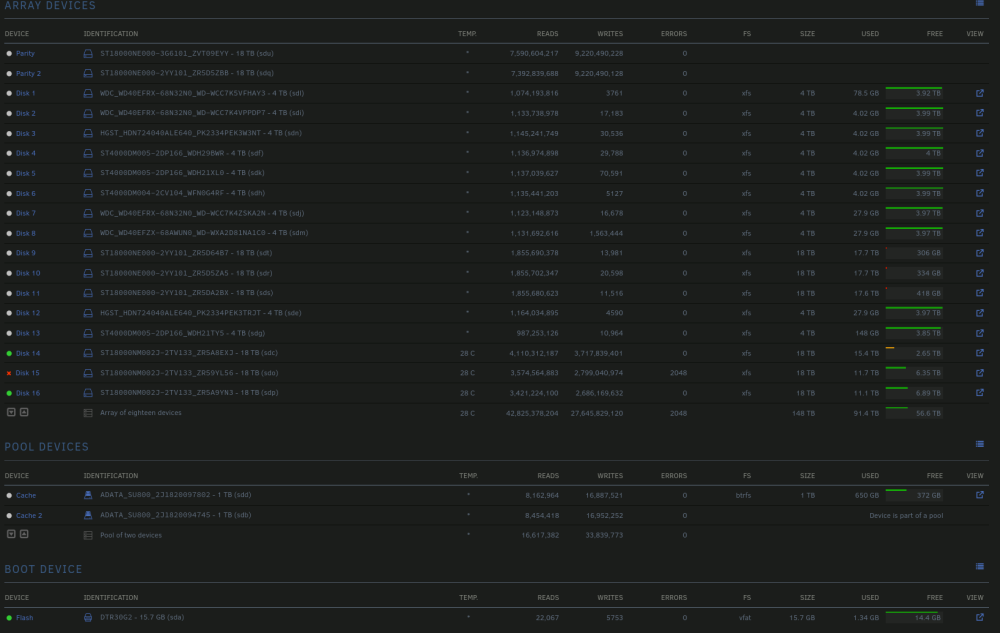
-
Hey thank you for looking into the logs. What is the next best step? Reboot the server? Still swap the drive out? Am I able to still pull the data from this drive?
-
Hey everyone, just got 3 18TB HDDs, Completed preclear, without issue. While migrating from my smaller 4TB drives onto the new drives using unbalance one of the drives disabled itself. I have completed a long SMART test that came back clean so I am not sure what is going on. Attached are logs from the diagnostics page as well as the SMART log from the drive itself. Second question to go along with this, if the drive has actually shit the bed, can I use unbalance again to move the data off the drive back onto the 4TB drives or what is the best way to go about this? I have a new 18TB drive on its way but it will be another ~4 days at least. tower-smart-20231103-1459.zip tower-diagnostics-20231103-1456.zip
-
Alright so quick update, I have swapped the CPUs in their respective sockets after cleaning them up. Cleared the IPMI logs and have just got Unraid back up and running. Lets see what comes up in the logs next, but from the basic googling I have done it seems more likely that the PSU is starting to fail rather than the CPUs. On that topic, does anyone know where I could get a replacement Segate ss-400h2u? From what I am seeing in CAD its like $400-$500 "new". Or does anyone know if a Segate ss-600h2u would be swapable? I know that desktop PSUs are not to be trusted due to the cabling variations, regardless of brand or model. Does the same stand for server PSUs?
-
Apologies for the delayed response. I noticed that while in the IPMI I was unable to see any sensor information at all. Everything was showing and unknown/unavailable. What I have done since is actually reflash the BIOS and Firmware for my mobo, and now I am seeing proper errors and data from the sensors. I have attached all that I can from the system information screen and a new diagnostics output from unraid. From what I can see, IPMI log seems to be filling up with a bunch of CPU lines, but I am not 100% just yet on what it means. I wanted to get the info posted here before trying to figure out what it's trying to explain. Thank you for the reply, I'm not sure if I would have much faith in my equipment as I am still learning quite a bit and looks like there is still a ton more to learn. So maybe take my post with a grain of salt, could currently just be happenstance. IPMI Event Log.xlsx IPMI Sensor Readings + Threshholds.xlsx tower-diagnostics-20230312-1635.zip
-
Apologies, I don't follow. Its a dual socket motherboard, and both sockets have a X5670 CPU in them. Are you telling me to swap the CPUs in each socket? This server has been running for at least a couple of years in this config, if that is of any help.

















