




AeonLucid
Members
-
Joined
-
Last visited
Everything posted by AeonLucid
-
Issue is still occuring on 6.11.0-rc3.
-
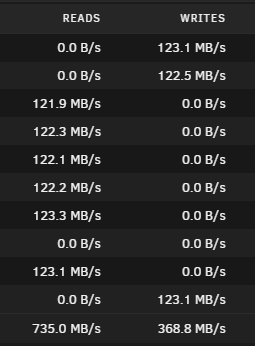
Progress I have made some progress on my issue. What helped was understanding what iowait means and how it occurs. It happens when something requires io of a disk while that disk is under full load by another process, causing it to wait. This gave me the idea to split my cache pool into two. One cache pool (a) is used for appdata / system / domains (vms) Other cache pool (b) is used for all shares that will eventually get moved to the array, such as plex media / downloads Doing this has fixed my issue of plex (or other containers) becoming unresponsive when media is downloaded, because it is a totally separate disk. Remaining issue While this has solved some issue's, I still have issues with the mover. When files are moved from the cache pool (b) to my array, reading anything from the array of the disk that data is being moved to just does not work until the mover is finished. I tried to fix this by changing the mover CPU & IO priority with my own plugin (CA Mover Tuning fork). This seemed to have helped a little bit, but after the mover finishes I notice high usage across my entire array (updating parity?) which still causes lock ups (cpu iowait) until that is finished, and this puts load on all disks. I have already tried both available md_write_method, reconstruct write (aka turbowrite) finishes the mover faster but the parity process after still causes issues.

-
Just found this plugin and it looks great, has anyone tried it on 6.10.0-rc2? Will it work? Also, am I seeing it right that this is not "tuning" the original mover but a replacement of it?
-
I'm having some trouble with Unraid and I'm hoping that someone can assist me, it is related to high cpu_iowait on the cache pool. I have a share that is used by sabnzbd / sonarr / radarr / plex, containing all my media files. This share has "cache pool" set to "Yes", so the mover will later put them on the array. The appdata and system shares are both on the same "cache pool" (as the media), set to "Prefer". My array consists of all 8TB WD RED and my cache pool is a Samsung 860 2TB evo. Both are xfs encrypted. I noticed this issue first when I had 2x 2TB SSD with btrfs encrypted but in other threads of others with a similar issue people suggested to try xfs, which did not fix it. At this time, I am still on xfs encrypted for both my array and the cache pool. Sabnzbd has a volume /mnt/user/plex/usenet to /storage/usenet. - /storage/usenet/incomplete - /storage/usenet/completed Sonarr has a volume /mnt/user/plex/ to /storage. - /storage/media/TVShows/Someshow So this will move downloaded media from /storage/usenet/completed to /storage/media/TVShows/Someshow, and translated /mnt/user/plex/usenet/completed to /mnt/user/plex/usenet/completed. When I download a season with sonarr, I notice after a download completes in sabnzbd and gets imported, the `cpu_iowait` goes up to 30% or higher and docker containers start to freeze. Also, when the mover runs, moving all the episodes from the cache to array, it freezes everything and plex direct play stops working as well. High cpu_iowait in both case. This is not the only case in which the cpu_iowait goes up. For example when I write a 13GB file to the same share using samba, the same thing happens. If you are playing a movie on plex that is located on the array, playback stops and starts buffering. Every container becomes really unresponsive.
-
I have a very weird issue with this container and the binhex-delugevpn container. I have always downloaded at full speed using nordvpn config files, but since a few days ago I have noticed that the speed randomly stays at exactly 1MB/s. It's not that big of a deal, but when this happens, my entire network has a ping of 1000ms. I have never had that issue when downloading at full speed. When I download a large file (10GB) to my cache disk using SSH, the speed is my max and the ping stays normal. Anyone know what could be causing this?


