




Beta
Members
-
Joined
-
Last visited
Everything posted by Beta
-
Hi! For me the buttons for console and log does not work. WebUI-button works but not console and log, nothing happens when I click them. I am running Firefox 149 under Windows 11. I have also tried it latest Chrome and Edge, same behavior there. It just changes the URL to end with # Unraid OS version: 7.2.3 Theme: Black Page: Docker Steps to reproduce: Enable log and console buttons, head to docker tab and try to click them.

-
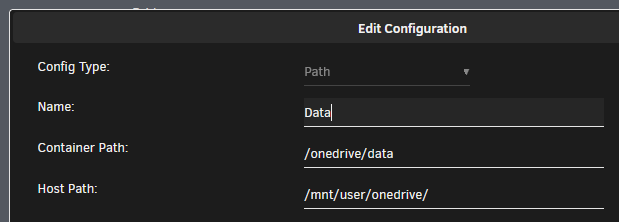
When starting the container the modified time is updated on the conf file but as far as I can see no data is modified in the config file. Confirming, adding: sync_dir = "/onedrive/data" to the config file does not trigger the modify. Modify date on the file stays the same as before starting the container.
-
I am not very versed in this, but I have a theory why this was happening. After reading the docker usage documentation on GitHub of the client it seems that in 2.5.0 that the volume of the onedrive data dir was changed to a variable: version: "3" services: onedrive: image: driveone/onedrive:edge restart: unless-stopped environment: - ONEDRIVE_UID=${PUID} - ONEDRIVE_GID=${PGID} volumes: - onedrive_conf:/onedrive/conf - ${ONEDRIVE_DATA_DIR}:/onedrive/data - ${ONEDRIVE_DATA_DIR}:/onedrive/data Whilst the docker template has defined the data dir with a container to host path configuration: My theory is that with the template the data dir is not properly defined and the docker can't find the data dir in the template paths/variables or the config file and somehow that triggers a modify of the conf file. That could be the reason why it works to add sync_dir = "/onedrive/data" to the conf file. I am not sure how we could translate - ${ONEDRIVE_DATA_DIR}:/onedrive/data to be used as a variable or path in the docker template on unraid, perhaps someone more versed can step in with some advice. I could be completely wrong with all of the above, @abraunegg can maybe chime in if this is even possible.
-
Thanks for the help Jonathan! Didn't want to risk running the array with the disk over the weekend, so went to my local electronics chain store and purchased a replacement. Was going to order a Ironwolf 8TB online with next day delivery (monday cus wekends), was €20 cheaper but ¯\_(ツ)_/¯ Running rebuild now!

-
Values increased during the extended test 187 Reported uncorrect 0x0032 097 097 000 Old age Always Never 3 197 Current pending sector 0x0012 100 100 000 Old age Always Never 16 198 Offline uncorrectable 0x0010 100 100 000 Old age Offline Never 16 And extended smart test failed Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error # 1 Extended offline Completed: read failure 10% 37833 - # 2 Short offline Completed without error 00% 37825 - # 3 Extended offline Completed without error 00% 37799 - # 4 Short offline Completed without error 00% 37786 - Ordering a replacement disk now, I have not seen any issues with any other drives yet. Most of them are rather new except for two WD Black 2 TB with 7 years power on which I have been waiting to fail.. Halting all read/write heavy tasks until it's replaced.
-
Ooops more SMART errors popped up this evening. Time to order a replacement? Running another extended test right now. 197 Current pending sector 0x0012 100 100 000 Old age Always Never 8 198 Offline uncorrectable 0x0010 100 100 000 Old age Offline Never 8
-
Awesome, I thought as much, but nice having confirmation from someone more knowledgeable! I'll acknowledge the errors and keep my eyes on it for further errors for now. Thanks for the hint on the ftp-server. I was going to disable it anyway soon, barely used anymore.
-
Hi! I'm in the midst of a read/write heavy procedure unpacking about 25 TB of rared content with unpackerr, throwing a few hundred gigs at it at a time. During last night I got a push from unraid saying Reported uncorrect on one drive increased from 0 to 1 in the middle of the current batch of unpacking. When done unraid indicated 32 errors on the drive (I assume these are corrected?) I then proceeded to run a short smart test followed by an extended smart test. During the extended smart test, reported uncorrect increased to 3. However, the test seems to say that the drive passed. See test results below: Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error # 1 Extended offline Completed without error 00% 37799 - # 2 Short offline Completed without error 00% 37786 - After the extended smart test unraid now indicates 96 errors on the drive: Reported uncorrect now sits at 3 after the extended test: 187 Reported uncorrect 0x0032 097 097 000 Old age Always Never 3 I've attached my diagnostics. (Disk 6 is the disk with the errors) Is it safe to acknowledge the error and keep using the disk but keep an eye out for increasing values and other smart errors? Or should I be looking at replacing the drive ASAP? Thanks! unraid-diagnostics-20230329-2137.zip

-
@binhex Any plans to update this docker now when ruTorrent 4.0.1 is released? Seems like a very nice update from them.
-
Please add cksfv It was in the old NerdPack and would be awesome to have it on unRAID 6.11 again
-
Hi, thanks for bringing this back to unraid 6.11! I would like to request for cksfv to be added, thanks!
-
Hi! Recently (started maybe a few weeks ago, but can't remember updating the docker) my setup stopped tracking Finished status of torrents. Finished column (from plugin seedingtime) is empty for new torrents, history tab does not track finished status and therefore Pushbullet events for finished does not work. Anyone noticed the same or know of a fix? I tried to update to latest docker revision today (ruTorrent 3.10) but the issue persists.
-
I have done some more testing, and whatever setting I choose it automatically intiate shutdown procedures at exactly 5 minutes. My UPS was not listed on the compatibility list so I guess it's as you said som driver issue, and it safely shutdown at some default value instead which is 5 minutes. Makes kinda sense. Well I'm happy at least knowing what causes it and battery time before it shuts down.
-
Thanks for the heads up! I did not know that. Yes it is using SLA batteries. I'll take this into consideration, however I do not get many power failures. Can't remember I have had any at all since I moved in 4 years ago. From the dashboard in unraid while I was monitoring it when testing the UPS, I was monitoring what NUT reported constantly. The display on the UPS itself was at 2/4 bars battery with about 6-7 minutes left. NUT seems to be reporting about the same as the UPS itself, the battery percentage dropped at an expected rate in NUT. Would it be better to try runtime left or time on battery? I timed the server to need about 1,5m to shutdown properly.
-
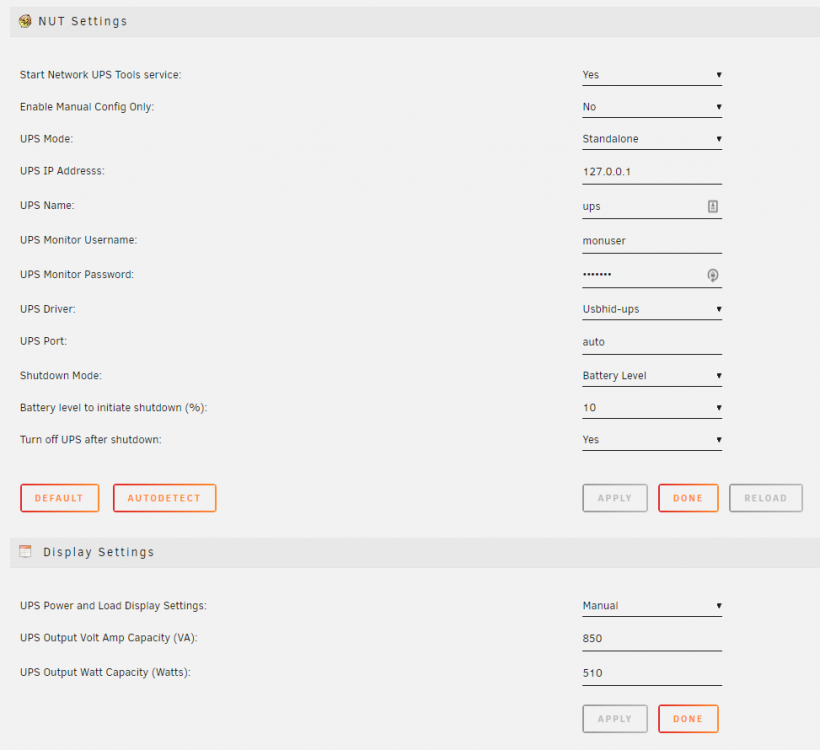
Hi! I have an Eaton Ellipse PRO 850 that I am using with this plugin on my unRAID-machine. I am having some trouble getting my shutdown settings to work 100%. I have set NUT to intiate shutdown at 10% left on battery, however it intiates shutdown way to early at around 59% from the two times I have tested now. Here is my NUT Settings: Here is the log from the shutdown procedure: Jan 8 23:14:17 unRAID upsmon[23159]: UPS [email protected] on battery Jan 8 23:19:27 unRAID upsmon[23159]: UPS [email protected] battery is low Jan 8 23:19:27 unRAID upsd[23155]: Client [email protected] set FSD on UPS [ups] Jan 8 23:19:27 unRAID upsmon[23159]: Executing automatic power-fail shutdown Jan 8 23:19:27 unRAID upsmon[23159]: Auto logout and shutdown proceeding Jan 8 23:19:32 unRAID shutdown[12858]: shutting down for system halt Jan 8 23:19:32 unRAID init: Switching to runlevel: 0 Jan 8 23:19:33 unRAID init: Trying to re-exec init Jan 8 23:19:39 unRAID emhttpd: req (5): cmdStop=apply&csrf_token=**************** Jan 8 23:19:39 unRAID kernel: mdcmd (49): nocheck Jan 8 23:19:39 unRAID emhttpd: Spinning up all drives... Jan 8 23:19:39 unRAID kernel: md: nocheck_array: check not active Jan 8 23:19:39 unRAID emhttpd: shcmd (3637): /usr/sbin/hdparm -S0 /dev/sdb Jan 8 23:19:39 unRAID kernel: mdcmd (50): spinup 0 Jan 8 23:19:39 unRAID kernel: mdcmd (51): spinup 1 Jan 8 23:19:39 unRAID kernel: mdcmd (52): spinup 2 Jan 8 23:19:39 unRAID kernel: mdcmd (53): spinup 3 Jan 8 23:19:39 unRAID kernel: mdcmd (54): spinup 4 Jan 8 23:19:39 unRAID kernel: mdcmd (55): spinup 5 Jan 8 23:19:39 unRAID kernel: mdcmd (56): spinup 6 Jan 8 23:19:39 unRAID root: Jan 8 23:19:39 unRAID root: /dev/sdb: Jan 8 23:19:39 unRAID root: setting standby to 0 (off) Jan 8 23:19:39 unRAID emhttpd: shcmd (3638): /usr/sbin/hdparm -S0 /dev/sdc Jan 8 23:19:39 unRAID root: Jan 8 23:19:39 unRAID root: /dev/sdc: Jan 8 23:19:39 unRAID root: setting standby to 0 (off) Jan 8 23:19:47 unRAID emhttpd: Stopping services... Jan 8 23:19:47 unRAID emhttpd: shcmd (3640): /etc/rc.d/rc.libvirt stop Jan 8 23:19:49 unRAID root: Domain e4ccb7aa-8d12-682a-06b3-307208dabd56 is being shutdown Jan 8 23:19:49 unRAID root: Jan 8 23:19:49 unRAID root: Domain 3e293166-fb30-b06a-1c27-1a7d1f74abce is being shutdown Jan 8 23:19:49 unRAID root: Jan 8 23:19:51 unRAID avahi-daemon[10125]: Interface vnet0.IPv6 no longer relevant for mDNS. Jan 8 23:19:51 unRAID avahi-daemon[10125]: Leaving mDNS multicast group on interface vnet0.IPv6 with address fe80::fc54:ff:fecf:fa47. Jan 8 23:19:51 unRAID kernel: br0: port 2(vnet0) entered disabled state Jan 8 23:19:51 unRAID kernel: device vnet0 left promiscuous mode Jan 8 23:19:51 unRAID kernel: br0: port 2(vnet0) entered disabled state Jan 8 23:19:51 unRAID avahi-daemon[10125]: Withdrawing address record for fe80::fc54:ff:fecf:fa47 on vnet0. Jan 8 23:20:04 unRAID avahi-daemon[10125]: Interface vnet1.IPv6 no longer relevant for mDNS. Jan 8 23:20:04 unRAID avahi-daemon[10125]: Leaving mDNS multicast group on interface vnet1.IPv6 with address fe80::fc54:ff:fe0b:b049. Jan 8 23:20:04 unRAID kernel: br0: port 3(vnet1) entered disabled state Jan 8 23:20:04 unRAID kernel: device vnet1 left promiscuous mode Jan 8 23:20:04 unRAID kernel: br0: port 3(vnet1) entered disabled state Jan 8 23:20:04 unRAID avahi-daemon[10125]: Withdrawing address record for fe80::fc54:ff:fe0b:b049 on vnet1. Jan 8 23:20:04 unRAID root: Waiting on VMs to shutdown............... Jan 8 23:20:04 unRAID root: Stopping libvirtd... Jan 8 23:20:04 unRAID dnsmasq[12878]: exiting on receipt of SIGTERM Jan 8 23:20:04 unRAID kernel: device virbr0-nic left promiscuous mode Jan 8 23:20:04 unRAID kernel: virbr0: port 1(virbr0-nic) entered disabled state Jan 8 23:20:04 unRAID avahi-daemon[10125]: Interface virbr0.IPv4 no longer relevant for mDNS. Jan 8 23:20:04 unRAID avahi-daemon[10125]: Leaving mDNS multicast group on interface virbr0.IPv4 with address 192.168.122.1. Jan 8 23:20:04 unRAID dhcpcd[1675]: virbr0: new hardware address: Jan 8 23:20:04 unRAID avahi-daemon[10125]: Withdrawing address record for 192.168.122.1 on virbr0. Jan 8 23:20:04 unRAID root: Network 7e6a3e65-1f8a-40ba-881f-e3fc72e43adf destroyed Jan 8 23:20:04 unRAID root: Jan 8 23:20:08 unRAID root: Stopping virtlogd... Jan 8 23:20:09 unRAID root: Stopping virtlockd... Jan 8 23:20:10 unRAID emhttpd: shcmd (3641): umount /etc/libvirt Jan 8 23:20:10 unRAID root: Stopping docker_load Jan 8 23:20:10 unRAID emhttpd: shcmd (3643): /etc/rc.d/rc.docker stop Jan 8 23:20:12 unRAID kernel: device br0 left promiscuous mode Jan 8 23:20:12 unRAID kernel: veth5ddce05: renamed from eth0 Jan 8 23:20:13 unRAID root: stopping dockerd ... Jan 8 23:20:14 unRAID root: waiting for docker to die ... Jan 8 23:20:15 unRAID avahi-daemon[10125]: Interface docker0.IPv4 no longer relevant for mDNS. Jan 8 23:20:15 unRAID avahi-daemon[10125]: Leaving mDNS multicast group on interface docker0.IPv4 with address 172.17.0.1. Jan 8 23:20:15 unRAID avahi-daemon[10125]: Withdrawing address record for 172.17.0.1 on docker0. Jan 8 23:20:15 unRAID emhttpd: shcmd (3644): umount /var/lib/docker Jan 8 23:20:15 unRAID cache_dirs: Stopping cache_dirs process 11711 Jan 8 23:20:17 unRAID cache_dirs: cache_dirs service rc.cachedirs: Stopped Jan 8 23:20:17 unRAID unassigned.devices: Unmounting All Devices... Jan 8 23:20:18 unRAID emhttpd: shcmd (3645): /etc/rc.d/rc.samba stop Jan 8 23:20:18 unRAID emhttpd: shcmd (3646): rm -f /etc/avahi/services/smb.service Jan 8 23:20:18 unRAID avahi-daemon[10125]: Files changed, reloading. Jan 8 23:20:18 unRAID avahi-daemon[10125]: Service group file /services/smb.service vanished, removing services. Jan 8 23:20:18 unRAID emhttpd: Stopping mover... Jan 8 23:20:18 unRAID emhttpd: shcmd (3649): /usr/local/sbin/mover stop Jan 8 23:20:18 unRAID root: mover: not running Jan 8 23:20:18 unRAID emhttpd: Sync filesystems... Jan 8 23:20:18 unRAID emhttpd: shcmd (3650): sync Jan 8 23:20:18 unRAID emhttpd: Stopping ProFTPd... Jan 8 23:20:19 unRAID proftpd[2608]: 127.0.0.1 - ProFTPD killed (signal 15) Jan 8 23:20:19 unRAID proftpd[2608]: 127.0.0.1 - ProFTPD 1.3.6 standalone mode SHUTDOWN Jan 8 23:20:20 unRAID emhttpd: ... Stop OK Jan 8 23:20:21 unRAID emhttpd: shcmd (3651): umount /mnt/user0 Jan 8 23:20:21 unRAID emhttpd: shcmd (3652): rmdir /mnt/user0 Jan 8 23:20:21 unRAID emhttpd: shcmd (3653): umount /mnt/user Jan 8 23:20:21 unRAID emhttpd: shcmd (3654): rmdir /mnt/user Jan 8 23:20:21 unRAID emhttpd: shcmd (3655): rm -f /boot/config/plugins/dynamix/mover.cron Jan 8 23:20:21 unRAID emhttpd: shcmd (3656): /usr/local/sbin/update_cron Jan 8 23:20:21 unRAID emhttpd: Unmounting disks... Jan 8 23:20:21 unRAID emhttpd: shcmd (3657): umount /mnt/disk1 Jan 8 23:20:21 unRAID kernel: XFS (md1): Unmounting Filesystem Jan 8 23:20:28 unRAID emhttpd: shcmd (3658): rmdir /mnt/disk1 Jan 8 23:20:28 unRAID emhttpd: shcmd (3659): umount /mnt/disk2 Jan 8 23:20:28 unRAID kernel: XFS (md2): Unmounting Filesystem Jan 8 23:20:28 unRAID emhttpd: shcmd (3660): rmdir /mnt/disk2 Jan 8 23:20:28 unRAID emhttpd: shcmd (3661): umount /mnt/disk3 Jan 8 23:20:28 unRAID kernel: XFS (md3): Unmounting Filesystem Jan 8 23:20:28 unRAID emhttpd: shcmd (3662): rmdir /mnt/disk3 Jan 8 23:20:28 unRAID emhttpd: shcmd (3663): umount /mnt/disk4 Jan 8 23:20:29 unRAID kernel: XFS (md4): Unmounting Filesystem Jan 8 23:20:29 unRAID emhttpd: shcmd (3664): rmdir /mnt/disk4 Jan 8 23:20:29 unRAID emhttpd: shcmd (3665): umount /mnt/disk5 Jan 8 23:20:29 unRAID kernel: XFS (md5): Unmounting Filesystem Jan 8 23:20:29 unRAID emhttpd: shcmd (3666): rmdir /mnt/disk5 Jan 8 23:20:29 unRAID emhttpd: shcmd (3667): umount /mnt/disk6 Jan 8 23:20:29 unRAID kernel: XFS (md6): Unmounting Filesystem Jan 8 23:20:29 unRAID emhttpd: shcmd (3668): rmdir /mnt/disk6 Jan 8 23:20:29 unRAID emhttpd: shcmd (3669): umount /mnt/cache Jan 8 23:20:29 unRAID emhttpd: shcmd (3670): rmdir /mnt/cache Jan 8 23:20:29 unRAID root: Stopping diskload Jan 8 23:20:29 unRAID kernel: mdcmd (57): stop Jan 8 23:20:29 unRAID kernel: md1: stopping Jan 8 23:20:29 unRAID kernel: md2: stopping Jan 8 23:20:29 unRAID kernel: md3: stopping Jan 8 23:20:29 unRAID kernel: md4: stopping Jan 8 23:20:30 unRAID kernel: md5: stopping Jan 8 23:20:30 unRAID kernel: md6: stopping Jan 8 23:20:30 unRAID emhttpd: Starting services... Jan 8 23:20:30 unRAID emhttpd: shcmd (3672): /etc/rc.d/rc.samba start Jan 8 23:20:30 unRAID root: Starting Samba: /usr/sbin/nmbd -D Jan 8 23:20:30 unRAID root: /usr/sbin/smbd -D Jan 8 23:20:30 unRAID root: /usr/sbin/winbindd -D Jan 8 23:20:30 unRAID emhttpd: shcmd (3673): cp /tmp/emhttp/smb.service /etc/avahi/services/smb.service Jan 8 23:20:30 unRAID avahi-daemon[10125]: Files changed, reloading. Jan 8 23:20:30 unRAID avahi-daemon[10125]: Loading service file /services/smb.service. Can anyone help me figure out what is wrong? Thanks!
-
Hi! After upgrading from unRAID 6.5.0 to 6.5.2 today I get the following errors every 4-5 seconds in my log: May 16 11:32:01 unRAID root: error: /plugins/preclear.disk/Preclear.php: wrong csrf_token May 16 11:32:05 unRAID root: error: /plugins/preclear.disk/Preclear.php: wrong csrf_token May 16 11:32:07 unRAID root: error: /plugins/preclear.disk/Preclear.php: wrong csrf_token May 16 11:32:13 unRAID root: error: /plugins/preclear.disk/Preclear.php: wrong csrf_token May 16 11:32:16 unRAID root: error: /plugins/preclear.disk/Preclear.php: wrong csrf_token May 16 11:32:19 unRAID root: error: /plugins/preclear.disk/Preclear.php: wrong csrf_token May 16 11:32:25 unRAID root: error: /plugins/preclear.disk/Preclear.php: wrong csrf_token May 16 11:32:27 unRAID root: error: /plugins/preclear.disk/Preclear.php: wrong csrf_token May 16 11:32:31 unRAID root: error: /plugins/preclear.disk/Preclear.php: wrong csrf_token May 16 11:32:37 unRAID root: error: /plugins/preclear.disk/Preclear.php: wrong csrf_token May 16 11:32:38 unRAID root: error: /plugins/preclear.disk/Preclear.php: wrong csrf_token May 16 11:32:43 unRAID root: error: /plugins/preclear.disk/Preclear.php: wrong csrf_token May 16 11:32:49 unRAID root: error: /plugins/preclear.disk/Preclear.php: wrong csrf_token May 16 11:32:49 unRAID root: error: /plugins/preclear.disk/Preclear.php: wrong csrf_token May 16 11:32:55 unRAID root: error: /plugins/preclear.disk/Preclear.php: wrong csrf_token May 16 11:33:00 unRAID root: error: /plugins/preclear.disk/Preclear.php: wrong csrf_token May 16 11:33:01 unRAID root: error: /plugins/preclear.disk/Preclear.php: wrong csrf_token May 16 11:33:07 unRAID root: error: /plugins/preclear.disk/Preclear.php: wrong csrf_token May 16 11:33:11 unRAID root: error: /plugins/preclear.disk/Preclear.php: wrong csrf_token May 16 11:33:13 unRAID root: error: /plugins/preclear.disk/Preclear.php: wrong csrf_token What may be the cause of this? Does the plugin need an update to work with 6.5.2?






