




dnLL
Members
-
Joined
-
Last visited
-
Just did a new test with a different release and it worked... I'm so confused. Edit: yeah, seems like I was testing with a bugged release lol, everything else is working. Oh well. Thanks for your help!
-
Ah, yes, those are artifacts from my old LSIO config I guess. So, I changed it to absolute paths in /data rather that relative paths which were in /config. However, that doesn't help. It's like sonarr doesn't receive the notification from sabnzbd or doesn't know where are the files located?
-
like because of the trailing slash? because the paths are identical otherwise edit: the trailing slash didn't fix it
-
My files are not moved, they get stuck in "Waiting to import". I've been having issues with LSIO dockers for a while and decided to migrate to binhex for sabnzbd and sonarr. When adding a file through sonarr, it correctly gets downloaded by sabnzbd. However, nothing happens after. No errors in the logs. I doesn't get renamed and it isn't moved like it should. Both dockers use the same paths. I'd like to know how to properly debug this. Here is an example: root@server01:~# ls -l /mnt/user/servarr/usenet/tvshows/*/* -rw-rw-rw- 1 nobody users 4947879278 Jun 29 02:57 /mnt/user/servarr/usenet/tvshows/House.of.the.Dragon.S03E02.Queens.Landing.REPACK.1080p.AMZN.WEB-DL.DDP5.1.Atmos.H.264-FLUX/House.of.the.Dragon.S03E02.Queens.Landing.REPACK.1080p.AMZN.WEB-DL.DDP5.1.Atmos.H.264-FLUX.mkv Logs from sonarr: 2026-06-29 02:57:11,928 DEBG 'sonarr' stdout output: [Info] Sabnzbd: Adding report [House.of.the.Dragon.S03E02.Queens.Landing.REPACK.1080p.AMZN.WEB-DL.DDP5.1.Atmos.H.264-FLUX] to the queue. 2026-06-29 02:57:11,994 DEBG 'sonarr' stdout output: [Info] DownloadService: Report sent to SABnzbd. Indexer NZBgeek. House.of.the.Dragon.S03E02.Queens.Landing.REPACK.1080p.AMZN.WEB-DL.DDP5.1.Atmos.H.264-FLUX Logs from sabnzbd: [...] 2026-06-29 02:57:11,928 DEBG 'sonarr' stdout output: [Info] Sabnzbd: Adding report [House.of.the.Dragon.S03E02.Queens.Landing.REPACK.1080p.AMZN.WEB-DL.DDP5.1.Atmos.H.264-FLUX] to the queue. 2026-06-29 02:57:11,994 DEBG 'sonarr' stdout output: [Info] DownloadService: Report sent to SABnzbd. Indexer NZBgeek. House.of.the.Dragon.S03E02.Queens.Landing.REPACK.1080p.AMZN.WEB-DL.DDP5.1.Atmos.H.264-FLUX 2026-06-29 02:57:11,928 DEBG 'sonarr' stdout output: [Info] Sabnzbd: Adding report [House.of.the.Dragon.S03E02.Queens.Landing.REPACK.1080p.AMZN.WEB-DL.DDP5.1.Atmos.H.264-FLUX] to the queue. 2026-06-29 02:57:11,994 DEBG 'sonarr' stdout output: [Info] DownloadService: Report sent to SABnzbd. Indexer NZBgeek. House.of.the.Dragon.S03E02.Queens.Landing.REPACK.1080p.AMZN.WEB-DL.DDP5.1.Atmos.H.264-FLUX [...] 2026-06-29 02:57:12,552 DEBG 'start-script' stdout output: 2026-06-29 02:57:12,551::INFO::[assembler:297] Decoding finished /config/Downloads/incomplete/House.of.the.Dragon.S03E02.Queens.Landing.REPACK.1080p.AMZN.WEB-DL.DDP5.1.Atmos.H.264-FLUX/House.of.the.Dragon.S03E02.Queens.Landing.REPACK.1080p.AMZN.WEB-DL.DDP5.1.Atmos.H.264-FLUX.vol-01.par2 2026-06-29 02:57:12,553 DEBG 'start-script' stdout output: 2026-06-29 02:57:12,553::INFO::[object:1371] Checking all filenames for House.of.the.Dragon.S03E02.Queens.Landing.REPACK.1080p.AMZN.WEB-DL.DDP5.1.Atmos.H.264-FLUX 2026-06-29 02:57:12,553 DEBG 'start-script' stdout output: 2026-06-29 02:57:12,553::INFO::[object:1374] Re-sorting House.of.the.Dragon.S03E02.Queens.Landing.REPACK.1080p.AMZN.WEB-DL.DDP5.1.Atmos.H.264-FLUX after getting filename information 2026-06-29 02:57:12,552 DEBG 'start-script' stdout output: 2026-06-29 02:57:12,551::INFO::[assembler:297] Decoding finished /config/Downloads/incomplete/House.of.the.Dragon.S03E02.Queens.Landing.REPACK.1080p.AMZN.WEB-DL.DDP5.1.Atmos.H.264-FLUX/House.of.the.Dragon.S03E02.Queens.Landing.REPACK.1080p.AMZN.WEB-DL.DDP5.1.Atmos.H.264-FLUX.vol-01.par2 2026-06-29 02:57:12,553 DEBG 'start-script' stdout output: 2026-06-29 02:57:12,553::INFO::[object:1371] Checking all filenames for House.of.the.Dragon.S03E02.Queens.Landing.REPACK.1080p.AMZN.WEB-DL.DDP5.1.Atmos.H.264-FLUX 2026-06-29 02:57:12,553 DEBG 'start-script' stdout output: 2026-06-29 02:57:12,553::INFO::[object:1374] Re-sorting House.of.the.Dragon.S03E02.Queens.Landing.REPACK.1080p.AMZN.WEB-DL.DDP5.1.Atmos.H.264-FLUX after getting filename informationAs for the config:

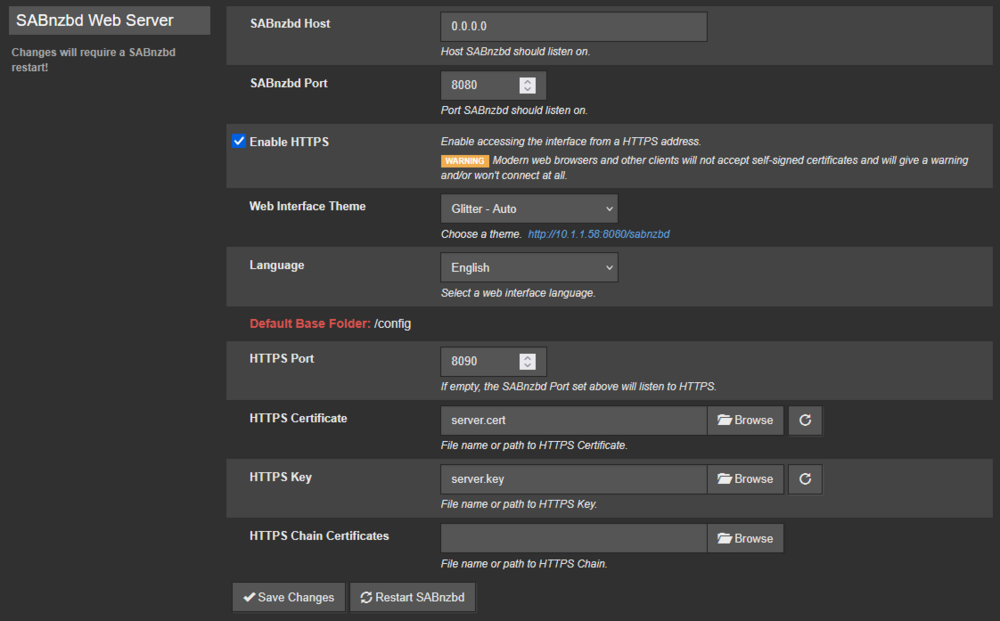
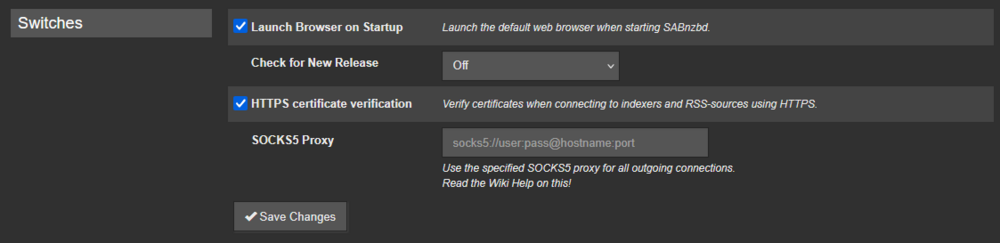
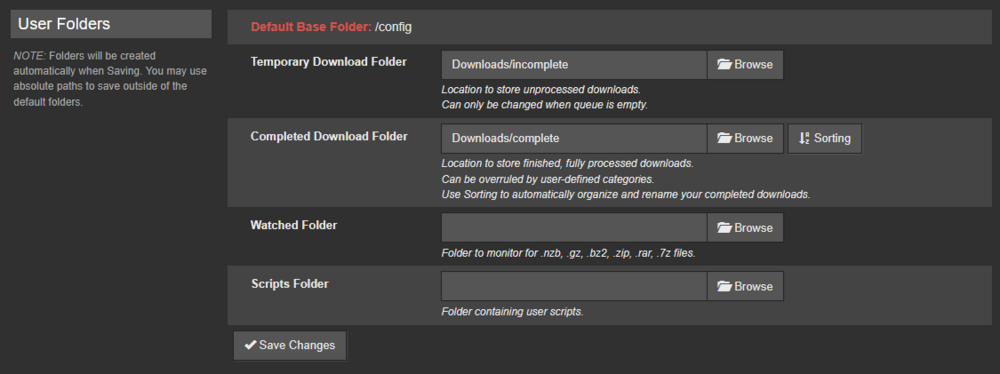
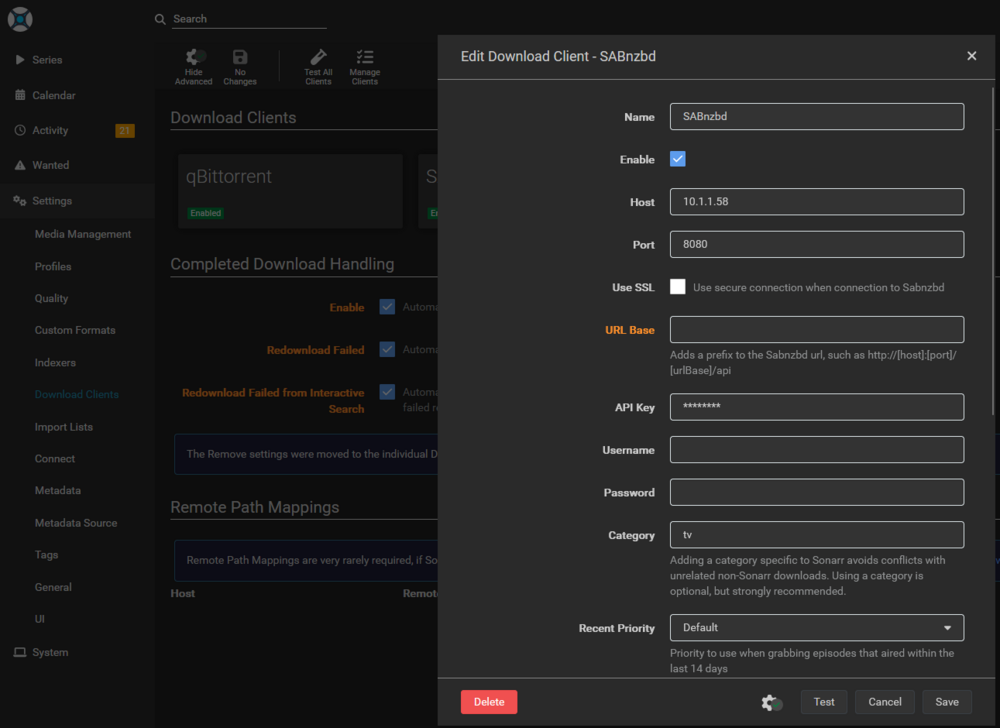

-
Is it supposed to show up in the Community Apps? I can't find it. I also noticed on my other server that I use the following packages: bc-1.07.1-x86_64-5.txz exiftool-12.76-noarch-1_SBo_UES.txz ipmitool-1.8.18-x86_64-1_SBo.txz So I'm probably screwed either way? ipmitools can definitely be found with another plugin, not sure about bc and exiftool however.
-
I haven't followed exactly what works and what does not, I updated to Unraid 7.0.1 and NerdTools still seem to be working fine for me? I use the following packages: python3-3.9.18-x86_64-1_slack15.0.txz python-setuptools-65.1.1-x86_64-1.txz python-pip-21.3.1-x86_64-2.txz mlocate-0.26-x86_64-4.txz The Python stuff is needed to properly monitor Unraid dockers with Checkmk. `mlocate` is just for convenience.
-
I see some people complaining about connectivity issues with recent versions of this docker. I don't know what is the issue and don't really have time to diagnotize it right now, I rarely update my dockers but I went from 4.6.5-1-04 to 5.0.2-1-01 and it stopped working. The docker won't get a local IP address assigned no matter what network I try (the port mappings in the docker webpage is just empty, no IP no nothing). The docker still connects to the VPN just fine with the new version according to the logs, but I can't access it locally... Going back to 4.6.5-1-04 completely solves the issue. Example of when it works with the older version: On latest:


-
It's honestly appreciated as I came to this thread because of the broken update and I'm glad to learn more about what's going on and knowing there are security mechanisms in place. I also hope there is a built-in API in the future where a plugin isn't required to make a powerful app such as ControlR.
-
Got it working. Whether it's worth the hassle or not depends on what you are trying to do... monitoring the nginx status webpage from Unraid isn't particularly useful outside of academic purposes. If you look at /etc/rc.d/rc.nginx, it overwrites /etc/nginx/conf.d/locations.conf and /etc/nginx/conf.d/servers.conf on every reload. locations.conf is where you want to add the status page, so you need to edit build_locations(). I suggest adding the entry after nchan_stub_status to make it look like that: location /nchan_stub_status { nchan_stub_status; } location /nginx_status { stub_status; } Now, this might get overwritten after an update or a reboot (haven't really tested yet), so you might want to add a user script that runs on first start of your array to edit rc.nginx and reload it.
-
Old thread but also an issue for me right now. `/etc/nginx/conf.d/servers.conf` and `/etc/nginx/conf.d/locations.conf` are dynamically rewritten each time nginx is loaded (as programmed in `/etc/rc.d/rc.nginx`). Other files in `conf.d` are ignored. Editing `nginx.conf` directly on every boot could create problems later on with future updates. Not sure what's the best approach to this. Also curious why the nginx_status was disabled, as there are traces here in the forums and elsewhere in Unraid that this might have been enabled in the past. Performance issue?
-
I did some digging thanks to the File Activity plugin combined with iostat. root@server01:~# iostat -mxd nvme0n1 -d nvme1n1 Linux 6.1.74-Unraid (server01) 03/17/2024 _x86_64_ (16 CPU) Device r/s rMB/s rrqm/s %rrqm r_await rareq-sz w/s wMB/s wrqm/s %wrqm w_await wareq-sz d/s dMB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util nvme0n1 1.30 0.10 0.00 0.00 0.64 76.38 94.35 2.97 0.00 0.00 0.72 32.26 25.29 2.76 0.00 0.00 2.61 111.85 4.48 2.10 0.14 8.74 nvme1n1 1.32 0.10 0.00 0.00 0.63 76.47 98.80 2.97 0.00 0.00 0.51 30.81 25.29 2.76 0.00 0.00 2.44 111.85 4.48 2.09 0.12 8.56 So, writing around 3 MB/s consistently while looking with iostat. With the File Activity plugin, I noticed the following: ** /mnt/user/domains ** Mar 17 22:49:25 MODIFY => /mnt/cache/domains/vm-linux/vdisk1.img Mar 17 22:49:26 MODIFY => /mnt/cache/domains/vm-automation/haos_ova-8.2.qcow2 ... Mar 17 22:49:26 MODIFY => /mnt/cache/domains/vm-automation/haos_ova-8.2.qcow2 Mar 17 22:49:27 MODIFY => /mnt/cache/domains/vm-windows/vdisk1.img ... Mar 17 22:49:27 MODIFY => /mnt/cache/domains/vm-windows/vdisk1.img Mar 17 22:49:28 MODIFY => /mnt/cache/domains/vm-automation/haos_ova-8.2.qcow2 ... Mar 17 22:49:28 MODIFY => /mnt/cache/domains/vm-automation/haos_ova-8.2.qcow2 Mar 17 22:49:28 MODIFY => /mnt/cache/domains/vm-dev/vdisk1.img ... Mar 17 22:49:28 MODIFY => /mnt/cache/domains/vm-dev/vdisk1.img ** Cache and Pools ** Mar 17 22:44:13 MODIFY => /mnt/cache/domains/vm-automation/haos_ova-8.2.qcow2 ... Mar 17 22:44:29 MODIFY => /mnt/cache/domains/vm-automation/haos_ova-8.2.qcow2 For instance, lots of writes coming from my Home Assistant VM running HAOS. That would be because the data from HA is hosted locally on the VM rather than on a NFS share. That also explains while I'm getting a lot of writes without necessary reading it. I might want to work on that and on similar issues with my other VMs. Thought I would post my findings just to help others with similar issues using the right tools to potentially find the problem. Obviously with the File Activity plugin, I don't get the actual quantity of data that is being written but it gives me a good idea.
-
I have a RAID1 of cache NVME SSD drives. I originally set it up in BTRFS but recently changed for ZFS. I'm trying to understand why is my writes usage so much higher than reads. Currently both SSDs are sitting down at around 250 TiB write and 8 TiB read per the smart report with 395 days of uptime. On my cache are the VMs, the dockers and temporary cache storage for other shares. When I first installed my SSDs, I was plagued by an issue with dockers where I would get super high write usage (multiple TiB per day). This was eventually resolved. Now, it's more or less following the same curve with about 20 TiB of writes per month. That's about the size of my whole array (24 TB), which is obviously ridiculous. My questions are the following. 1- When the mover is invoked, should there be a 1:1 ratio between the previous writes and the files being moved turning into reads? 2- When loading VM disk files from the cache, I assume it reads the whole file? Does every read/write within the VM get transferred to the VM disk file (in this case my cache)? 3- Anything particular pertaining to dockers that I should be aware of concerning high writes usage? I'm using the folder option for docker storage. Sent from my Pixel 7 Pro using Tapatalk
-
Thanks for pointing this out. Obviously when grepping the entire config, I'm not saying "delete every mention of X" but more "hey this might send you in the right direction". Might not necessarily be the dockers, could be a forgotten user script or whatever plugin, hence the wider grep. Sent from my Pixel 7 Pro using Tapatalk
-
This happened to me as well but only when the network gets disconnected after boot. Reconnecting the network doesn't fix the issue, however rebooting with the network correctly plugged in will prevent the errors from showing in the logs. I've been having issues recently on 6.12.7 and 6.12.8 with Unraid crashing when the network gets disconnected (ie. router rebooting), so I was doing some tests (but wasn't able to reproduce sadly). Not sure any of these kernel errors are related to the crash issues but that's my only lead for now. It's probably important to note that I'm using IEEE 802.3ad dynamic link bonding over 2 interfaces (LACP) and it only happens when connection to both interfaces is lost simultaneously.
-
Thank you!! I'm aware this is a 7-year-old thread but, I just wanted to report that this was my exact issue, I had an unused path in a docker trying to access my deleted share and it would just `mkdir` it when not existing, bringing back a share every damn reboot. To help find the issue (replace `share` by your share name): root@Tower:~# grep -R "/share" /boot/config You might have to exclude some results by adding an additional `| grep -v something` at the end, for example if you use the dynamix file integrity plugin you might get some false positives here.








