




dingd0ng
Members
-
Joined
-
Last visited
-
Same thing has happened to me. Am running Unraid 6.11.5, and pretty sure I am running latest version of the plugin as the server is only a few days old and I just updated most of the plugins. Startet a transfer from one array drive to another array drive, minimized the transfer window to do something else, and now all I see is the top menu with "dashboard", "main", "shares" etc. Have tried both safari and chrome, same result. Any suggestions?
-
Hi I have been having trouble getting the DelugeVPN docker to function properly for the last two days. All of a sudden I couldn't connect to the webserver anymore, and after checking the logs I see this; 2021-10-11 00:25:20,842 DEBG 'watchdog-script' stderr output: Unhandled error in Deferred: 2021-10-11 00:25:20,843 DEBG 'watchdog-script' stderr output: Traceback (most recent call last): File "/usr/lib/python3.9/site-packages/twisted/internet/base.py", line 1423, in run self.mainLoop() File "/usr/lib/python3.9/site-packages/twisted/internet/base.py", line 1433, in mainLoop reactorBaseSelf.runUntilCurrent() File "/usr/lib/python3.9/site-packages/twisted/internet/base.py", line 999, in runUntilCurrent call.func(*call.args, **call.kw) File "/usr/lib/python3.9/site-packages/twisted/internet/task.py", line 232, in __call__ d = defer.maybeDeferred(self.f, *self.a, **self.kw) --- <exception caught here> --- File "/usr/lib/python3.9/site-packages/twisted/internet/defer.py", line 167, in maybeDeferred result = f(*args, **kw) File "/usr/lib/python3.9/site-packages/deluge/core/alertmanager.py", line 70, in update self.handle_alerts() File "/usr/lib/python3.9/site-packages/deluge/core/alertmanager.py", line 138, in handle_alerts **{ File "/usr/lib/python3.9/site-packages/deluge/core/alertmanager.py", line 139, in <dictcomp> attr: getattr(alert, attr) builtins.UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe5 in position 34: invalid continuation byte I had some trouble a few months ago with DelugeVPN which was solved by reinstalling the docker, so I tried doing the same again. It seemed to work fine for a few hours, I re-added a lot of torrents, and after DelugeVPN had rechecked most of the files I again got an error saying "The connection to the web server has been lost". After this I haven't been able to access the web server for more than a moment. After checking logs another time I again tried reinstalling the docker, but now I can barely open the web UI before it locks down with "the connection to the web server has been lost". In addition and possibly unrelated - earlier today I also had trouble accessing the docker because it seemed Private Internet Access was having problems. When I disabled the VPN part of the docker it started, but I still couldn't access the Web UI due to the error message above. A few hours later PIA seemed to have fixed their problems, but still no Web UI access. Does anyone have any idea what the problem could be? I have attached the log file from before I reinstalled and a log file from the latest reinstall. Unraid version: 6.9.1 CPU: Intel i3 8350K Motherboard: Asus Rog Strix Z370-F Gaming. BIOS from 01.12.2017 Controller card: LSI SAS-9211-8i Disks: Eight Seagate ranging from 8 to 16 TB, mainly Ironwolf-disks. PSU: EVGA Supernova G3 750W supervisord (new install).log supervisord (old install).log
-
I have now run Seagate SeaTools on the disk, and none of the tests even seem able to run. Below is the log from SeaTools for the disk. All other disks in the server ran all tests without error. I still can't access any SMART-info from the disk in Unraid, but the disk shows up in Unassigned Devices. Does anyone have any idea what could cause such a catastrophic failure of the drive during an ordinary move-operation?
-
OK, this is weird, but I connected two smaller disks to the server via an external hard disk bay and ran SMART tests on them to see if that worked, and after doing this the failed parity drive now show up as an option in the drop down menu for Parity. I can now also access the parity drive under Unassigned devices with more information than earlier. I still can't run a SMART check on the disk and I still cant see the attributes and capabilities of the disk, but I can download a SMART report. I have attached this to this post. What are my possible options going forward? Since I can now pick this drive as a parity drive I assume I could re-select it and start the array, which I think will trigger a parity rebuild. This seems risky seeing as this is the same disk making weird noises earlier tonight. And those noises were weird. I could maybe try Tools - New Config and reassign the disks to their old configuration, and choose Parity is valid (think it is called this). I think this would get the array online the fastest. But again, I don't trust this disk yet. I could try removing the parity drive completely from the server, connecting it to the same external hard disk bay and see if I can run a proper SMART check on it from there. If that works I think I should get an updated overview of damaged sectors etc on the disk and could make a more informed decision about reusing the disk or not. I could start the array without a parity drive assigned. This is obviously risky with regards to further data loss, but I would get access to my files and dockers? Is this even possible? Would I have to do the New Config-step to do this? What do the pros suggest? First priority is obviously to find out if the drive is OK, then what made the errors appear in the first place, and then to get the array online as fast as possible. ST16000NM001G-2KK103_ZL235Z8D-20210926-0158.txt
-
Unfortunately I don't have any other disks of that size available, and a smaller disk won't work as parity drive since some of the array disks also are 16 TB. Could I disconnect the failed disk and reconnect it to an external drive bay and run a SMART check from Unassigned devices? Or is SMART checks not available from UD?
-
Controller difference, as in which controller card or SATA-connection they are connected to in the server? No, all disks are connected to the same LSI controller card using two SAS-to-4-SATA-cables. Previously some disks have been connected directly to the motherboard SATA-ports, but not the parity drive I am currently having problems with. I am also having trouble getting a fresh SMART-report from the disk. When clicking on the disk under Unassigned devices there is almost no data, see attached screenshot. Is this normal when a disk is connected to Unassigned devices? Shouldn't I be able to run a SMART self test?

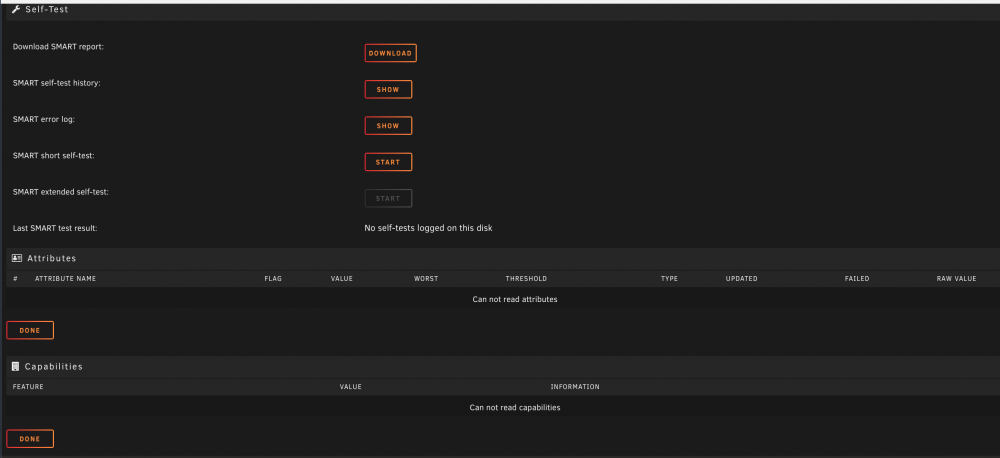
-
Hi Tonight my parity drive started making some horrible noises during a move operation, so I basically panicked and unplugged the disk since it sounded like something inside was skipping around. A few hours earlier I also got some SMART errors, the one I remember was about Offline Uncorrectable going from 0 to 8. Just when the noises came and I unplugged it I also got a red warning in the Unraid GUI which I think was about the parity drive being unconnected (as a precaution by Unraid?). I have seen similar things earlier with other disks, and in these cases I have reconnected them and rebuilt parity. After reconnecting the parity disk and stopping the array the disk didn't show up in the GUI, so I restarted the array to get the disk to show up again (and to swap SATA data cable as a precaution), but when the GUI restarted my parity disk couldn't be selected in the 'parity'-slot, the only option in the drop down menu was 'unassigned' meaning no disks could be chosen. The disk did show up further down under 'unassigned devices' with the option to format the disk or run a preclear session on it. Unfortunately, since I had now restarted the server the attached syslog probably doesn't contain all the errors from before the restart. I have also attached a screenshot of the server config from before the restart. The parity drive in question is ST16000NM001G-2KK103_ZL235Z8D (sde). Previously when disks have been disconnected from the array due to errors I think I have followed the instructions in this thread (link), but I think this is the first time it is the parity drive itself who's disconnected, and now it already shows as 'unassigned'. How should I proceed? I can't choose the parity drive as the new parity drive since the only option in the drop down menu is 'unassigned'. There are no disks to choose from, since the 'current' parity drive now is shown under 'unassigned devices'. Unraid version: 6.9.1 CPU: Intel i3 8350K Motherboard: Asus Rog Strix Z370-F Gaming. BIOS from 01.12.2017 Controller card: LSI SAS-9211-8i Disks: Eight Seagate ranging from 8 to 16 TB, mainly Ironwolf-disks. PSU: EVGA Supernova G3 750W To complicate things further I should mention that I have been having problems with disks for a long time now. I assumed most was due to old disks, but was also suspecting something in the server damaging the disks. And in the case of my parity drive failing the disk is only about 6 months old, and I precleared it before using it to stresstest it. I assume either the disks have become defect due to mechanical failure, either a fault in the disk all along or due to old age and out of my control, or something in my server is making the disks fail. I don't think Unraid or any other software can do this (?), so I am left with the cables connected to the disks, the LSI controller card, the motherboard, the PSU or overheating as the possible culprits. I have now swapped all SATA data cables. I was mostly using two SAS to 4 SATA-plug cables from the controller card and have swapped both these. I was also connecting some disks directly to the motherboard using ordinary SATA-cables, and I got a lot of SMART errors on some of these disks, but these disks were a few years old and have now been removed from the array, and for the last few weeks all disks have been connected to the controller card. I was therefore expecting these errors to be done with after taking these SATA-cables out of the server and not using the motherboard SATA-ports any more. Is it even possible for a SATA data cable to produce these errors? I get that a loose or damaged cable can lead to data loss and certain SMART errors, and I believe some of the SMART errors I have seen have been due to bad cables, but I can't image a bad data cable producing the noises and vibrations I have noticed lately. I have checked all SATA power cables from the PSU to the disks. I can't see anything wrong with them, but don't have any expertise in this. Is it even possible for a PSU or a PSU cable to damage a hard drive? The errors I have been getting seem to be mechanical, since I have heard some decidedly non-normal sounds from the damaged disks lately. I haven't noticed anything weird with the LSI controller card, but don't know how to check this further. I have as mentioned replaced the SAS to SATA-cables connected to the controller. I haven't noticed anything weird with the motherboard either, but again I don't know how this could be further investigated. After the few disks who were connected to the motherboards SATA-ports were removed earlier, I also don't see how this can be the culprit, other than maybe a faulty motherboard might lead to errors on a connected controller card which in turn is connected to the disks in question. But that seems far fetched. Overheating: Not a problem, the disks are almost never above 40 degrees, and fans are blowing air directly over them. tower-diagnostics-20210925-2248.zip
-
Is there any way to check how much space each docker is taking up in the completed backup? After excluding Plex from the backup my backups went from 50 GB down to 5 GB, but now they have ballooned to over 30 GB, and I can't figure out why. I haven't installed any new dockers, so I can't see the reason for the increase.
-
I tried this, but none of my libraries are there when I shut down the ordinary binhex-plex-docker and start the binhex-plexpass-docker. I only get an empty dashboard saying "the dashboard is empty. Add libraries with your media to make the most of Plex Media Server". I copied everything from "appdata/binhex-plex/plex media server" to "appdata/binhex-plexpass/plex media server". Anyone who knows what I'm doing wrong?
-
I downloaded and installed the ordinary binhex-plex docker since I didn't know there was a separate one for plexpass. Is there an easy way to upgrade from binhex-plex to binhex-plexpass that lets me keep all my settings and database?


