




yyc321
Members
-
Joined
-
Last visited
-
It's in a supermicro SC847 chassis, however I did change the standard fans for the green fans, so maybe there just isn't enough airflow for this card. I'll try attaching a fan or two directly to the card, or switch to a lower performance card.
-
I think you may be on to something. The card is a passive cooling card with a big heatsink, like many LSI cards. Just touched the card, and the heatsink is insanely hot. Would you happen to know if the LSI cards monitor temp? Is there a way to see that temp in the terminal?
-
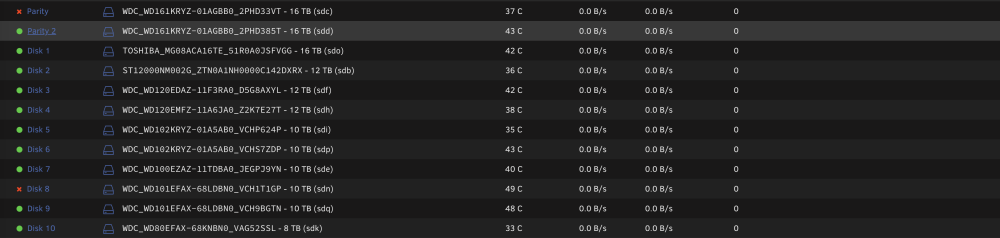
Not sure what's going on with my server. I suddenly have a bunch of errors, and both parity drives are disabled. Any help would be appreciated. r2-diagnostics-20240223-1726.zip
-
Have you tried a different browser?
-
Great, thanks!
-
The data on that drive is desired but not critical. I don't have the space on my backup server to backup all 90+TB. Thanks for your help, I think I'll try rebuilding parity, and then fix the issue with the array drive. In this case would the procedure be to remove the parity 1 assignment, and then reassign it?
-
I do have another unraid server running. Would it be best to copy the emulated contents from drive 8 over to the other server, and then start the rebuild on both the array and parity? If so, would the procedure be to create a new config, retaining all drive assignments including parity?
-
That's correct, I started the array in maintenance mode for the image. If I create a new config to start rebuilding the array disk, will this work considering one of the parity drives is also currently disabled? Does the system know to use parity 2 for the rebuild, or will I need to remove parity 1 until disk 8 is finished being rebuilt? Isn't the server going to try to rebuild both the array drive as well as the parity?
-
Filesystem check has solved problems for me in the past, so I tried it. I realize this is definitely not the right approach to troubleshooting a server, but I was looking for a quick fix. I also saw some posts regarding the "bad primary superblock - bad magic number !!!" suggesting the filesystem check as the solution. At the time, I didn't know that "xfs_repair -nv /dev/sdn" was the wrong command - I guess I mistakenly pulled it from the unraid docs.
-
This might help... Totally forgot that I have persistent logs turned on. The server started creating significantly more log entries starting on the 16th, so I only copied those entries to the txt file (75,000 entries in 5 days). syslog.zip
-
r2-diagnostics-20240121-0953.zip Thanks JorgeB. Extended SMART tests are at 70% and 90% respectively for parity 1 and array drive 8. I'll upload the results when it's finished.
-
ver 6.12.6 GUI was unresponsive so I rebooted via CLI - unfortunately I forgot to grab the logs prior to reboot. Post reboot logs attached. I tried repairing the filesystem on disk 8 via the "Disk 8 Settings" page. < Was this a bad move? Both drives show as healthy on the dashboard and drive attributes page. Short smart test ran on both drives. CLI: xfs_repair -nv /dev/sdn Shows: bad primary superblock - bad magic number !!! I was tempted to just create a new configuration, and see if the system could overwrite the data on disk 8, but with a parity drive disabled too, I'm worried that this might cause more problems than it fixes. Thanks in advance for any assistance. r2-diagnostics-20240120-1635.zip
-
I just had (almost) the same issue a few days ago - around the same time as your initial post. No USB failure in my case, just the server crash taking down the entire network (UDMP). Which version of Unraid are you running? --EDIT-- >> I see you're on 6.12.6 in the attached images. I updated to 6.12.6 shortly before - I'm wondering if the update has something to do with the crash.
-
I had the same issue posted in this thread. The update there from JorgeB shows that it's related to libtorrent 2.x. In my case, the unraid gui becomes unresponsive.
-
With the binhex deluge vpn docker disabled, everything seems to be stable. I’m also noticing that the docker and vm pages are loading much more quickly than before. Not sure if this is related to the torrent docker issue. Thanks JorgeB

