




yyc321
Members
-
Joined
-
Last visited
Everything posted by yyc321
-
It's in a supermicro SC847 chassis, however I did change the standard fans for the green fans, so maybe there just isn't enough airflow for this card. I'll try attaching a fan or two directly to the card, or switch to a lower performance card.
-
I think you may be on to something. The card is a passive cooling card with a big heatsink, like many LSI cards. Just touched the card, and the heatsink is insanely hot. Would you happen to know if the LSI cards monitor temp? Is there a way to see that temp in the terminal?
-
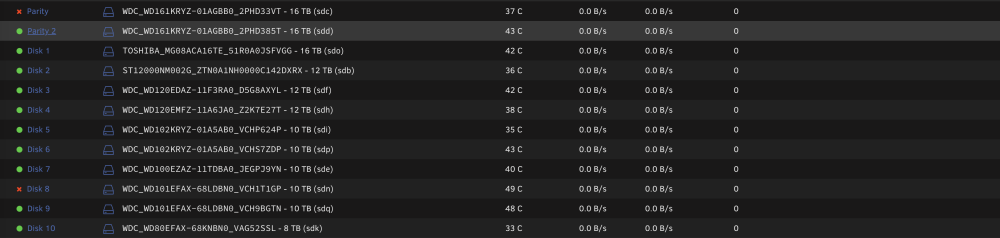
Not sure what's going on with my server. I suddenly have a bunch of errors, and both parity drives are disabled. Any help would be appreciated. r2-diagnostics-20240223-1726.zip
-
Have you tried a different browser?
-
Great, thanks!
-
The data on that drive is desired but not critical. I don't have the space on my backup server to backup all 90+TB. Thanks for your help, I think I'll try rebuilding parity, and then fix the issue with the array drive. In this case would the procedure be to remove the parity 1 assignment, and then reassign it?
-
I do have another unraid server running. Would it be best to copy the emulated contents from drive 8 over to the other server, and then start the rebuild on both the array and parity? If so, would the procedure be to create a new config, retaining all drive assignments including parity?
-
That's correct, I started the array in maintenance mode for the image. If I create a new config to start rebuilding the array disk, will this work considering one of the parity drives is also currently disabled? Does the system know to use parity 2 for the rebuild, or will I need to remove parity 1 until disk 8 is finished being rebuilt? Isn't the server going to try to rebuild both the array drive as well as the parity?
-
Filesystem check has solved problems for me in the past, so I tried it. I realize this is definitely not the right approach to troubleshooting a server, but I was looking for a quick fix. I also saw some posts regarding the "bad primary superblock - bad magic number !!!" suggesting the filesystem check as the solution. At the time, I didn't know that "xfs_repair -nv /dev/sdn" was the wrong command - I guess I mistakenly pulled it from the unraid docs.
-
This might help... Totally forgot that I have persistent logs turned on. The server started creating significantly more log entries starting on the 16th, so I only copied those entries to the txt file (75,000 entries in 5 days). syslog.zip
-
r2-diagnostics-20240121-0953.zip Thanks JorgeB. Extended SMART tests are at 70% and 90% respectively for parity 1 and array drive 8. I'll upload the results when it's finished.
-
ver 6.12.6 GUI was unresponsive so I rebooted via CLI - unfortunately I forgot to grab the logs prior to reboot. Post reboot logs attached. I tried repairing the filesystem on disk 8 via the "Disk 8 Settings" page. < Was this a bad move? Both drives show as healthy on the dashboard and drive attributes page. Short smart test ran on both drives. CLI: xfs_repair -nv /dev/sdn Shows: bad primary superblock - bad magic number !!! I was tempted to just create a new configuration, and see if the system could overwrite the data on disk 8, but with a parity drive disabled too, I'm worried that this might cause more problems than it fixes. Thanks in advance for any assistance. r2-diagnostics-20240120-1635.zip
-
I just had (almost) the same issue a few days ago - around the same time as your initial post. No USB failure in my case, just the server crash taking down the entire network (UDMP). Which version of Unraid are you running? --EDIT-- >> I see you're on 6.12.6 in the attached images. I updated to 6.12.6 shortly before - I'm wondering if the update has something to do with the crash.
-
I had the same issue posted in this thread. The update there from JorgeB shows that it's related to libtorrent 2.x. In my case, the unraid gui becomes unresponsive.
-
With the binhex deluge vpn docker disabled, everything seems to be stable. I’m also noticing that the docker and vm pages are loading much more quickly than before. Not sure if this is related to the torrent docker issue. Thanks JorgeB
-
It looks like that post points to problems with torrent dockers. I disabled the binhex deluge vpn docker after your post, and everything is still functioning normally as of this morning. I'll keep monitoring the server, and post any updates.
-
As the subject states, I am occasionally having issues with the UI becoming unresponsive. This generally happens every 3 or 4 days, and is fixed with a reboot. When this happens, I still have terminal access, VMs and containers still function normally. During the most recent event, I was able to capture the system log via ssh. Most of the log items look normal - just emhttpd spin up / down entries etc. However, I did spot the following error. Apr 10 05:59:44 R2 kernel: BUG: kernel NULL pointer dereference, address: 0000000000000116 Apr 10 05:59:44 R2 kernel: #PF: supervisor read access in kernel mode Apr 10 05:59:44 R2 kernel: #PF: error_code(0x0000) - not-present page Apr 10 05:59:44 R2 kernel: PGD 0 P4D 0 Apr 10 05:59:44 R2 kernel: Oops: 0000 [#1] PREEMPT SMP NOPTI Apr 10 05:59:44 R2 kernel: CPU: 1 PID: 3094 Comm: deluged Not tainted 5.19.17-Unraid #2 Apr 10 05:59:44 R2 kernel: Hardware name: Gigabyte Technology Co., Ltd. Z390 AORUS ULTRA/Z390 AORUS ULTRA-CF, BIOS F10h 01/19/2021 Apr 10 05:59:44 R2 kernel: RIP: 0010:folio_try_get_rcu+0x0/0x21 Apr 10 05:59:44 R2 kernel: Code: e8 9d fd 67 00 48 8b 84 24 80 00 00 00 65 48 2b 04 25 28 00 00 00 74 05 e8 c1 35 69 00 48 81 c4 88 00 00 00 5b c3 cc cc cc cc <8b> 57 34 85 d2 74 10 8d 4a 01 89 d0 f0 0f b1 4f 34 74 04 89 c2 eb Apr 10 05:59:44 R2 kernel: RSP: 0000:ffffc90006a47cc0 EFLAGS: 00010246 Apr 10 05:59:44 R2 kernel: RAX: 00000000000000e2 RBX: 00000000000000e2 RCX: 00000000000000e2 Apr 10 05:59:44 R2 kernel: RDX: 0000000000000001 RSI: ffff8888d8a376c0 RDI: 00000000000000e2 Apr 10 05:59:44 R2 kernel: RBP: 0000000000000000 R08: 000000000000003c R09: ffffc90006a47cd0 Apr 10 05:59:44 R2 kernel: R10: ffffc90006a47cd0 R11: ffffc90006a47d48 R12: 0000000000000000 Apr 10 05:59:44 R2 kernel: R13: ffff888c29c0d138 R14: 0000000000b395bf R15: ffff888c29c0d140 Apr 10 05:59:44 R2 kernel: FS: 00001543a82576c0(0000) GS:ffff88907e240000(0000) knlGS:0000000000000000 Apr 10 05:59:44 R2 kernel: CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 Apr 10 05:59:44 R2 kernel: CR2: 0000000000000116 CR3: 0000000221b28001 CR4: 00000000003726e0 Apr 10 05:59:44 R2 kernel: Call Trace: Apr 10 05:59:44 R2 kernel: <TASK> Apr 10 05:59:44 R2 kernel: __filemap_get_folio+0x98/0x1ff Apr 10 05:59:44 R2 kernel: filemap_fault+0x6e/0x524 Apr 10 05:59:44 R2 kernel: __do_fault+0x2d/0x6e Apr 10 05:59:44 R2 kernel: __handle_mm_fault+0x9a5/0xc7d Apr 10 05:59:44 R2 kernel: handle_mm_fault+0x113/0x1d7 Apr 10 05:59:44 R2 kernel: do_user_addr_fault+0x36a/0x514 Apr 10 05:59:44 R2 kernel: exc_page_fault+0xfc/0x11e Apr 10 05:59:44 R2 kernel: asm_exc_page_fault+0x22/0x30 Apr 10 05:59:44 R2 kernel: RIP: 0033:0x1543ad16c60d Apr 10 05:59:44 R2 kernel: Code: 00 00 00 00 00 66 66 2e 0f 1f 84 00 00 00 00 00 66 66 2e 0f 1f 84 00 00 00 00 00 66 90 f3 0f 1e fa 48 89 f8 48 83 fa 20 72 23 <c5> fe 6f 06 48 83 fa 40 0f 87 a5 00 00 00 c5 fe 6f 4c 16 e0 c5 fe Apr 10 05:59:44 R2 kernel: RSP: 002b:00001543a8256888 EFLAGS: 00010202 Apr 10 05:59:44 R2 kernel: RAX: 000015432803b480 RBX: 00001543280008e8 RCX: 00001543a8256ac0 Apr 10 05:59:44 R2 kernel: RDX: 0000000000004000 RSI: 00001532987bffe1 RDI: 000015432803b480 Apr 10 05:59:44 R2 kernel: RBP: 0000000000000000 R08: 0000000000000001 R09: 0000000000000000 Apr 10 05:59:44 R2 kernel: R10: 0000000000000008 R11: 0000000000000246 R12: 0000000000000000 Apr 10 05:59:44 R2 kernel: R13: 0000154170002180 R14: 0000000000000001 R15: 00001543a425a900 Apr 10 05:59:44 R2 kernel: </TASK> Apr 10 05:59:44 R2 kernel: Modules linked in: nfsv3 nfs xt_mark xt_CHECKSUM ipt_REJECT nf_reject_ipv4 ip6table_mangle ip6table_nat iptable_mangle xt_nat xt_tcpudp vhost_net tun vhost vhost_iotlb tap veth xt_conntrack xt_MASQUERADE nf_conntrack_netlink nfnetlink xfrm_user xfrm_algo xt_addrtype iptable_nat nf_nat nf_conntrack nf_defrag_ipv6 nf_defrag_ipv4 br_netfilter xfs nfsd auth_rpcgss oid_registry lockd grace sunrpc md_mod ip6table_filter ip6_tables iptable_filter ip_tables x_tables bridge stp llc mlx4_en mlx4_core e1000e i915 iosf_mbi drm_buddy i2c_algo_bit ttm drm_display_helper drm_kms_helper drm btusb btrtl btbcm x86_pkg_temp_thermal intel_powerclamp coretemp kvm_intel kvm crct10dif_pclmul crc32_pclmul crc32c_intel ghash_clmulni_intel aesni_intel crypto_simd gigabyte_wmi cryptd wmi_bmof intel_wmi_thunderbolt mxm_wmi btintel rapl bluetooth mpt3sas intel_cstate intel_gtt i2c_i801 nvme agpgart i2c_smbus ahci syscopyarea raid_class ecdh_generic input_leds sysfillrect sysimgblt intel_uncore i2c_core Apr 10 05:59:44 R2 kernel: nvme_core led_class ecc scsi_transport_sas libahci intel_pch_thermal fb_sys_fops thermal fan video wmi backlight acpi_pad button unix [last unloaded: mlx4_core] Apr 10 05:59:44 R2 kernel: CR2: 0000000000000116 Apr 10 05:59:44 R2 kernel: ---[ end trace 0000000000000000 ]--- Apr 10 05:59:44 R2 kernel: RIP: 0010:folio_try_get_rcu+0x0/0x21 Apr 10 05:59:44 R2 kernel: Code: e8 9d fd 67 00 48 8b 84 24 80 00 00 00 65 48 2b 04 25 28 00 00 00 74 05 e8 c1 35 69 00 48 81 c4 88 00 00 00 5b c3 cc cc cc cc <8b> 57 34 85 d2 74 10 8d 4a 01 89 d0 f0 0f b1 4f 34 74 04 89 c2 eb Apr 10 05:59:44 R2 kernel: RSP: 0000:ffffc90006a47cc0 EFLAGS: 00010246 Apr 10 05:59:44 R2 kernel: RAX: 00000000000000e2 RBX: 00000000000000e2 RCX: 00000000000000e2 Apr 10 05:59:44 R2 kernel: RDX: 0000000000000001 RSI: ffff8888d8a376c0 RDI: 00000000000000e2 Apr 10 05:59:44 R2 kernel: RBP: 0000000000000000 R08: 000000000000003c R09: ffffc90006a47cd0 Apr 10 05:59:44 R2 kernel: R10: ffffc90006a47cd0 R11: ffffc90006a47d48 R12: 0000000000000000 Apr 10 05:59:44 R2 kernel: R13: ffff888c29c0d138 R14: 0000000000b395bf R15: ffff888c29c0d140 Apr 10 05:59:44 R2 kernel: FS: 00001543a82576c0(0000) GS:ffff88907e240000(0000) knlGS:0000000000000000 Apr 10 05:59:44 R2 kernel: CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 Apr 10 05:59:44 R2 kernel: CR2: 0000000000000116 CR3: 0000000221b28001 CR4: 00000000003726e0
-
It's a supermicro chassis, with a supermicro backplane powering all of the drives. I'll get the syslog server setup.
-
So, the drive dropped offline again. The UI was unresponsive, so I rebooted from the CLI. I've attached the diagnostics, however they were taken after the reboot - not sure if this clears the info that you would need to diagnose the problem? Is there a way to create anonymized diagnostics from the terminal? tower-diagnostics-20230106-1924.zip
-
After several reboots to deal with the VM and Docker issues, the drive has reappeared in the list. Not sure if this was a drive issue, something with the HBA, or an OS issue. I've re-added the drive to the array, and am completing a rebuild now. If it drops offline again, I'll post an update.
-
You guys are great! Thank you so much. Disabling docker and VMs and cleaning up the array did the trick. I actually had a sub-folder in one of the shares that was accumulating all sorts of junk data, so it was really easy to free up about 8TB of data with a couple of clicks. Not sure why the shares and cache didn't have a minimum free space. I must of changed them to 0 at some point, but I have no idea why I would have done that. Still trying to track down the source of the missing drive. I've been wondering for a while if my HBA (9305-24i) is overheating. I had that happen in a different chassis, and it started dropping drives. I'll check the cooling, and the cables. Thanks again!
-
After years of unraid running with only minor hiccups, my server is suddenly having a bunch of issues. The server was unresponsive, so I did a sudo reboot from the CLI. One drive is showing as missing, the docker service has failed to start, and it now shows no VMs installed. Diagnostics attached. Thanks in advance. tower-diagnostics-20230102-2311.zip
-
Thanks!!
-
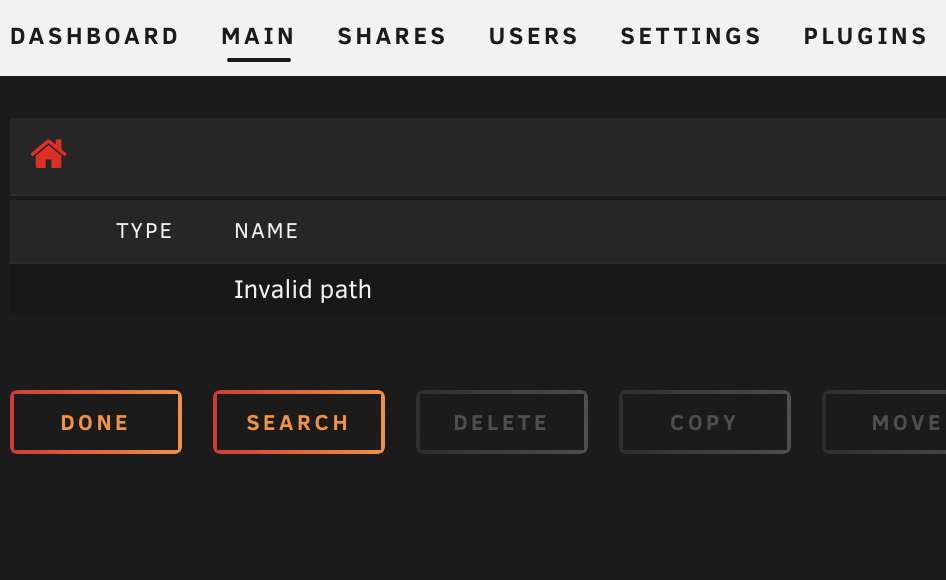
I have a pool device consisting of a single spinner. The drive shows up on the main page. Clicking the device name pulls up the drive properties etc. However, the drive doesn't show up in midnight commander. Clicking the view link on the main page results in "invalid path". In the logs, you'll notice that the server pulled a drive for UDMA CRC errors - the cable has been replaced. Just waiting to deal with this path issue before I fix the emulated drive. tower-diagnostics-20221004-1737.zip
-



