
Xaero
-
Posts
413 -
Joined
-
Last visited
-
Days Won
3
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by Xaero
-
You don't have to run it if the container is restarted, only if it is updated, force updated, or removed and reinstalled. That said, there isn't really a good way to fire events based on container update/restart at the moment (at least not built into unraid, or any plugins) If you are using the CA Auto Updater, and have it scheduled to update the container, you can also use CA User Scripts and schedule the script to run on the same schedule as the CA Auto Updater, just five minutes later, and it will run after the container has been updated that way. We could ask Limetech, the CA User Sripts or the CA Auto Updater dev's if they can add an event for container update. That said, I just have the script set to run every day after my containers are scheduled to update and it works fine.
-
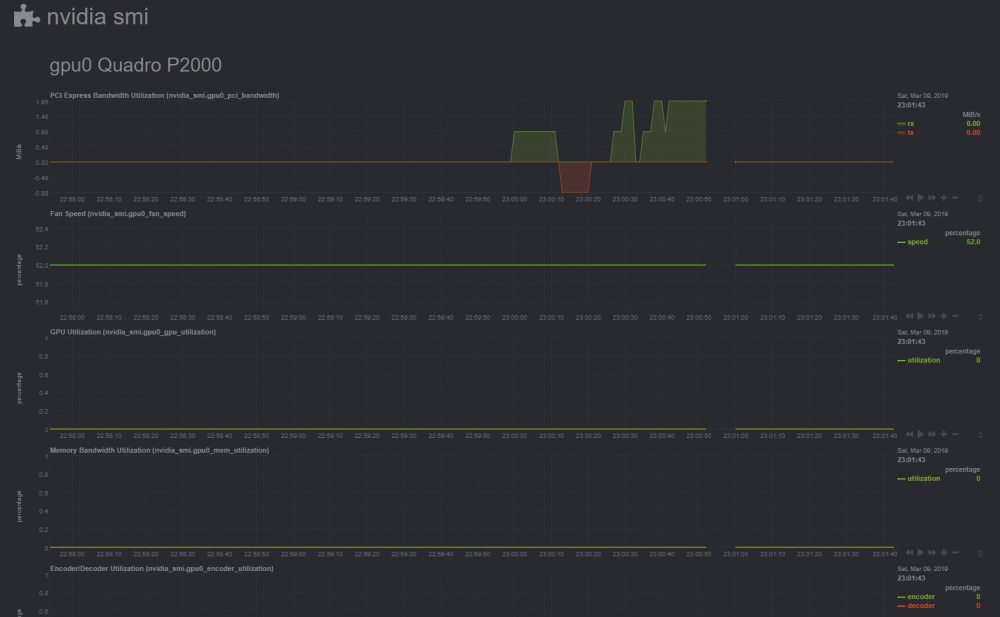
After running the script posted. You can see the nvidia smi entry highlighted in purple. And yes, this is with titpetric/netdata from Community Apps. Do you have the container set to save it's configuration to an appdata folder, perhaps? If so I think on startup it copies or symlinks the one in the appdata folder over the top of the one that script writes to. It also overwrites the file every time the container updates.
-
I highly doubt it; but it's possible. If you were encoding on platters, sure. But on an SSD you really shouldn't be bottlenecking. I think even 8k footage would encode to an SSD okay, depending on the workload it was under.
-
LSI Controller FW updates IR/IT modes
Xaero replied to madburg's topic in Storage Devices and Controllers
So, I've just realized that there are serious performance implications to running any older LSI cards in IR mode with disks passed through as JBOD. The firmware has an odd "bug" where it doesn't properly report the drive status. This confuses the kernel during any read/write operations and causes certain disk commands to kind of "hang" for a bit. Symptoms: rtorrent timing out even though it's on the NVME cache drive plex intermittently having poor transcoding performance, even with nvenc and nvdec abysmal parity check performance (note that part of this is due to my SAS Expander only negotiating 3gb/s per link) To verify your controller is old enough to have this problem (my IBM M1015/LSI 9211-8i is) Start watching the disk status with hdparm: watch -tn 0.1 hdparm -C /dev/sdw /dev/sdw: drive state is: standby Click the "Spin Up" button on that drive's page on the WebUI. If the drive state doesn't change, and the button is still there, your controller isn't reporting the drive status properly. From my understanding (have not been able to test yet) flashing the controller to IT mode *should* rectify this problem. I am upgrading my card to a 9750-24I4E with no expander to free up a PCI-E slot and get rid of the 3gb/s bottleneck. I'll be flashing that card to IT mode when I install it, but will try to flash my existing card to IT mode as well. I'm sure someone else has run into this, but I figured I should share anyways. I know that flashing to IT mode is "the usual" but also know that a lot of LSI users don't since the IR mode does JBOD disks as well. -
Also know that the encode process is heavily impacted by read and write performance. I'm not sure how nvdec handles it's buffer queueing, but if the buffer isn't filled with enough data, you will notice the video will stop playing. This is READ limited performance, and would be heavily impacted by a parity check, especially for high bitrate media. The nvenc side of the house is limited by how much data is being fed into it by the decoder, and the write speed of the destination media. If you are transcoding to tmpfs (ram) this will almost never be your bottleneck as the encoded media is typically much smaller and lower bitrate than the source media.
-
I'd also suggest using the copy on the gist I linked: https://gist.github.com/Xaero252/9f81593e4a5e6825c045686d685e2428 It checks for a couple of things that could happen now. Like if you start a VM with the card passed through with the old version, all transcodes would stop working until the VM was stopped. Now it will simply fall back on CPU decoding. It also ignores files that use the mpeg4 AVI container, as they have problems with the ffmpeg build used by plex thus far. And yeah, force update, or changing any property of the docker will use a fresh copy of the docker, making this very easy to rollback from.
-
You can easily use a disk shelf and an external HBA to add disks outside the current server in a physically separate enclosure.
-
There's a sidebar entry titled nvidia smi. Click on that. Note that the command is "nvidia-smi" but the configuration option is "nvidia_smi: yes" If you have entered everything correctly, and restarted the docker per the instructions it should show. Alternatively, you could add my script from a couple posts ago to userscripts and run it.
-
The Quadro 4000 does not, to my knowledge have nvenc or nvdec pipelines. Also, it's fermi based architecture so support was phased out with ~391.74. The driver installed with this plugin is 418.43, which is long after fermi was deprecated. I don't think this plugin should work with your card, to answer your question.
-
Perhaps look into the DKMS version of the nvidia driver. It's been pretty rock solid through kernel versions for me. Thanks for the update!
-
Probably still best to ask if they can add support to their docker, since it should just "not work" if nvidia-smi isn't available. But, if they are opposed, have a user script you can run on a schedule: #!/bin/bash con="$(docker ps --format "{{.Names}}" | grep -i netdata)" exists=$(docker exec -i "$con" grep -iqe "nvidia_smi: yes" /etc/netdata/python.d.conf >/dev/null 2>&1; echo $?) if [ "$exists" -eq 1 ]; then docker exec -i "$con" /bin/sh -c 'echo "nvidia_smi: yes" >> /etc/netdata/python.d.conf' docker restart "$con" >/dev/null 2>&1 echo '<font color="green"><b>Done.</b></font>' else echo '<font color="red"><b>Already Applied!</b></font>' fi
-
Got this working in netdata! So, don't worry about grabbing a special version, the version from Community Apps is fine. Steps to reproduce: Grab the docker from Community Apps. During the initial container install switch to advanced view, and add --runtime=nvidia to the end of the list. Add a new variable "NVIDIA_VISIBLE_DEVICES" with the value set to "all" Click done, and let the docker install. Open a console for the docker. echo "nvidia_smi: yes" >> /etc/netdata/python.d.conf Restart the docker. Enjoy.
-
So I just tried using the netdata docker, pointing it to this one for the repo: d34dc3n73r/netdata-glibc And while the docker does start, netdata works, and I can use nvidia-smi there doesn't seem to be any included netdata-nv plugin. I tried manually installing it, but haven't had any luck. I'll keep you posted on whether or not I figure it out.
-
Open a console for the docker and see what the output of which nvidia-smi is. That will tell you where the nvidia-smi binary is located.
-
You'll need to change the docker to use: --runtime=nvidia For each application that needs access to the card. The docker runtime is what has nvidia-smi in the case of your containers. In the case of unraid-nvidia it is also located in /usr/bin/nvidia-smi - but the dockers don't run on the base unraid system, they run inside the docker runtime. The stock docker runtime doesn't have nvidia-smi, the nvidia runtime does have nvidia-smi. Edit your docker like you did Plex and change it to use --runtime=nvidia and it should work.
-
That is something that would need support added for the netdata docker. There's a plugin here: https://github.com/coraxx/netdata_nv_plugin That would allow you to monitor various GPU statistics via netdata. Note that it doesn't monitor the nvdec and nvenc pipelines, so you wouldn't be able to see the transcoding usage - just the memory usage. Edit: Updated my script on gist; https://git.io/fhhe3
-
Currently using a P2000 myself. The decode patch has basically no drawbacks other than being unsupported. Eventually the nvdec support will be a standard plex feature, and the patch will become obsolete at that point. There is one possible downfall for the patch currently, which I need to figure out a "proper" way to approach: If for some reason your docker starts, and the nvidia card/driver is not working, your transcoder will cease to function entirely rendering playback impossible outside of native DirectPlay. This is a pretty impossible circumstance if you've configured everything and the nvenc side of the house works fine - but is certainly of concern because hardware failures occur, and changing to mainline unraid from the unraid-nvidia branch would also break Plex with the current script.
-
#!/bin/bash # This should always return the name of the docker container running plex - assuming a single plex docker on the system. con="$(docker ps --format "{{.Names}}" | grep -i plex)" echo -n "<b>Applying hardware decode patch... </b>" # Check to see if Plex Transcoder2 Exists first. exists=$(docker exec -i "$con" stat "/usr/lib/plexmediaserver/Plex Transcoder2" >/dev/null 2>&1; echo $?) if [ "$exists" -eq 1 ]; then # If it doesn't, we run the clause below # Move the Plex Transcoder to a different location so we can replace it with our wrapper docker exec -i "$con" mv "/usr/lib/plexmediaserver/Plex Transcoder" "/usr/lib/plexmediaserver/Plex Transcoder2" # For Legibility and future updates - if needed, use a heredoc to create the wrapper: docker exec -i "$con" /bin/sh -c 'xargs -0 printf > "/usr/lib/plexmediaserver/Plex Transcoder";' <<-'EOF' #!/bin/bash marap=$(cut -c 10-14 <<<"$@") if [ "$marap" == "mpeg4" ]; then exec /usr/lib/plexmediaserver/Plex\ Transcoder2 "$@" else exec /usr/lib/plexmediaserver/Plex\ Transcoder2 -hwaccel nvdec "$@" fi EOF # chmod the new wrapper to be executable: docker exec -i "$con" chmod +x "/usr/lib/plexmediaserver/Plex Transcoder" echo '<font color="green"><b>Done!</b></font>' # Green means go! else # If we ended up here, the patch didn't even try to run, presumably because the patch was already applied. echo '<font color="red"><b>Patch already applied!</b></font>' # Red means stop! fi Did some re-tooling of the script to make things a bit more sane, again. The wrapper script is now in a heredoc which allows it to be edited inline normally, rather than having a bunch of awkward escapes and such. Seems to work from my limited testing just now. Also includes the conditional posted above, fwiw. EDIT: If someone way more versed in FFMPEG limitations knows what a good list of exclusions from the nvdec parameter would be - we can certainly work that into the script fairly easy. Just store the formats in a string and test the return of grep against that variable, instead of testing specifically for each format. EDIT2: I just noticed that the resulting wrapper inside the docker loses the formatting in the heredoc. I'll try and fix that eventually. This has no impact on the script actually doing it's job or not. EDIT3: Script above has now been fixed. If copy and paste from here doesn't work from some reason, here's a gist: https://git.io/fhhe3 I'll be updating at that gist from now on, as well. Makes things easier.
-
[Support] Linuxserver.io - Plex Media Server
Xaero replied to linuxserver.io's topic in Docker Containers
The raid controller has a total of 8 channels on two 4 channel ports. The port expander has a total of 32 channels across a total of 8 ports. By connecting BOTH of the raid controller's ports to two of the ports on the expander for backhaul, you get a total of 8 channels of bandwidth between the controller and the expander, leaving 6 ports and 24 channels for disks. Effectively, you *should* be able to saturate 24Gb/s or 1Gb/s of bandwidth on all 24 disks simultaneously with this setup. This bandwidth is split between read and write operations since the backhaul connections have to do bidirectional data transfer. Sadly, that works out to some pretty dismal performance for parity checks: Duration: 1 day, 8 hours, 36 minutes, 8 seconds. Average speed: 68.2 MB/sec 68.2MB/s * 8 (byte -> bit) = 545.6Mb/s * 2 (read and write) = 1091.2Mb/s which is just over 1Gb/s of bandwidth. I imagine this is thanks to some optimization in the backhaul links, but it's not substantial enough to make any real world difference. I'll eventually upgrade to one of the single slot SAS-12 cards that won't require a port expander. With that solution, the limit would then be on the PCI-E lanes, and I doubt you could hit that with spinning platters. Effectively, each channel is a SATA link, the lowest supported speed of the devices is used as the link speed for each channel. Since the HP Expander only negotiates SATA at 3gb/s we should assume that it's backhaul is negotiating at 3gb/s as well (which is proven by the speeds we see when using all channels simultaneously. In theory, even a card like the Adaptec ASR-52445 would be faster than my current setup, even though its a 3gb/s controller - because all the ports would be on the same card, and not restricted to the 8 channels available for backhual on my current setup. I'd rather upgrade though and be less worried about limitations as solid state media slowly takes over the market lol -
[Support] Linuxserver.io - Plex Media Server
Xaero replied to linuxserver.io's topic in Docker Containers
HP 487738-001 / 468405-001 (they are the same part) There are some 24 port HBAs on the market now that are just a tad pricey, but the allure of only utilizing a single slot is quite nice. There are also a couple that have 2x external ports as well, which would be nice as eventually I'll add a disk shelf to expand (many years away, I hope) -
[Support] Linuxserver.io - Plex Media Server
Xaero replied to linuxserver.io's topic in Docker Containers
Strange, it seems to be encode bottlenecked from any probing I do. Disk read speed according to iotop for the process toggles between ~200kb/s to ~1.5mb/s with the main page unable to even show which disk is being hit (though I know which disk it is by finding it on the disk.) IO Tests on the disk show it capable of reading at ~150-200mb/s sequential, and no other activity is on that disk. So that should mean the Disk, and interface is good. The transcode directory is in tmpfs so DDR4-2133 shouldn't be the bottleneck either. The connection *is* slow, but I am streaming using a preset that works on other video files (720p 2mb/s) I'll have to dig at logs some more to see if I can find a "real reason" for it to not transcode this just fine, as it should be able to according to the specs on paper. -
#!/bin/bash #This should always return the name of the docker container running plex - assuming a single plex docker on the system. con="`docker ps --format "{{.Names}}" | grep -i plex`" echo "" echo "<b>Applying hardware decode patch...</b>" echo "<hr>" #Check to see if Plex Transcoder2 Exists first. exists=`docker exec -i $con stat "/usr/lib/plexmediaserver/Plex Transcoder2" >/dev/null 2>&1; echo $?` if [ $exists -eq 1 ]; then # If it doesn't, we run the clause below docker exec -i $con mv "/usr/lib/plexmediaserver/Plex Transcoder" "/usr/lib/plexmediaserver/Plex Transcoder2" docker exec -i $con /bin/sh -c 'printf "#!/bin/sh\nexec /usr/lib/plexmediaserver/Plex\ Transcoder2 -hwaccel nvdec "\""\$@"\""" > "/usr/lib/plexmediaserver/Plex Transcoder";' docker exec -i $con chmod +x "/usr/lib/plexmediaserver/Plex Transcoder" docker exec -i $con chmod +x "/usr/lib/plexmediaserver/Plex Transcoder2" docker restart $con echo "" echo '<font color="green"><b>Done!</b></font>' #Green means go! else echo "" echo '<font color="red"><b>Patch already applied or invalid container!</b></font>' #Red means stop! fi EDIT: Just corrected some flawed assumptions on the logic above. Using grep -i to grab container name so that it matches without case sensitivity. Using a variable to capture the return value of the stat, since docker exec -it can't be used and docker exec -i always returns 0. Flipped -eq 0 to -eq 1 since that was the inverse of the intended behavior. Only weird thing is something prints "plex" lowercase and I don't know where. EDIT2: Figured that out, docker restart $con prints the name of the container once it's restarted. Could redirect the output to /dev/null, though.
-
[Support] Linuxserver.io - Plex Media Server
Xaero replied to linuxserver.io's topic in Docker Containers
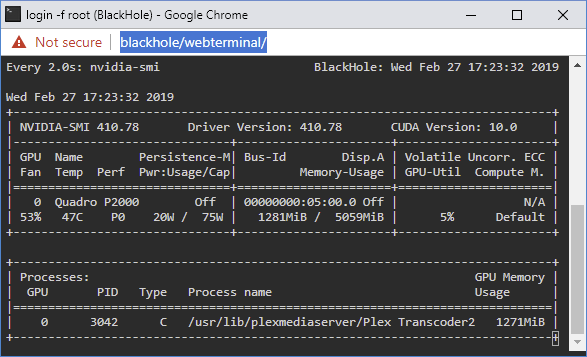
I need some assistance troubleshooting poor transcoding performance. I've been struggling with this since I built my new server late last year. I figured the issue was a lack of understanding on the capabilities of the components I selected for the server. Plex was an afterthought, so I wasn't too upset with making a mistake with component selection. Server specs are as follows: SuperMicro X10DRL-IO 2x Xeon E5-2658v3 64gb DDR4-2133 Fully Buffered ECC quad channel (4x16gb sticks - in the correct slots, board reports quad channel) 1x nvidia Quadro P2000 added recently for transcoding via the new nvidia plugin. 24x8TB Western Digital RED drives connected to an HP SAS Expander at 3gb/s (not 6gb/s, limitation of this strange SAS Expander) Raid controller is a 9211-8i 2xIntel 1tb 660p NVME SSD for cache Since this is a dual socket system, paying attention to CPU/PCI-E Lane associations is important. Thankfully this board only has ONE slot on CPU2. Slot arrangement is as follows: 660p SSD's are on a carrier card in the TOP PCI-E x8 slot, which is CPU1 Slot 6 Port Expander is in the lowest x8 slot which is a PCI-E 2.0x4 slot, on the chipset (not on either CPU) - but should only be pulling power from the slot. Raid Controller is in the slot above that, which is PCI-E 3.0x8 and is CPU1 Slot 2 Graphics card is in the only x16 slot on the board which is CPU1 Slot 5 Any time I go to transcode certain 4k files to any resolution the client reports that the server is not powerful enough to transcode for smooth playback. This seems bonkers since I have 48 CPU Threads and a dedicated GPU for transcoding. I figured originally since the CPU has no QuickSync Video that this was the problem, and that I'd need some sort of extra acceleration to get things done. So I threw the P2000 in, tossed unraid-nvidia in it, configured the container to use the new GPU and also added the nvdec parameter to the Plex Transcoder so that I could use the GPU for decoding and encoding. Video files are stored on the rotational media, fwiw though it shouldn't matter at this bitrate even. I get 15 seconds in to this file: And then it starts buffering and says the server isn't powerful enough. Checking nvidia-smi shows that the card is being used for encoding: And checking further shows that it is also being used for decoding: CPU Usage in this circumstance is quite low, suggesting that the audio stream shouldn't be bottlenecking. The video quality also suffers substantially, colors are washed out and there is significant banding. I'm at a loss for what to try to solve this. The target transcode is 720p, for reference, though streaming 1080p at 1080p works just fine on this same machine, even before adding the GPU for transcoding.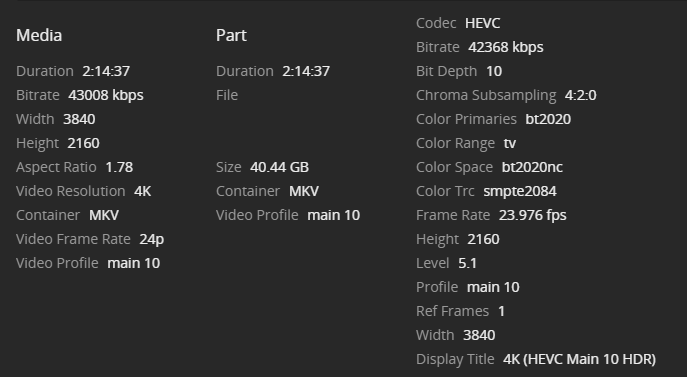
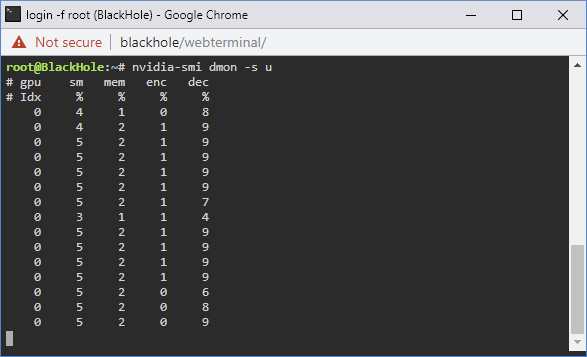
-
Understood - though you wouldn't be patching anything - just a wrapper script (which is what most containers use for startup anyways) Just a suggestion, after all. Eventually mainline Plex will support nvdec either way so not a big deal to work around until then.
-
Feature suggestion for the Plex Docker (suggesting it here because it's relevant here) Replace the /usr/lib/plexmediaserver/Plex Transcoder binary with a script that calls that binary like so: #!/bin/sh if [[ -n NVIDIA_VISIBLE_DEVICES ]]; then /usr/lib/plexmediaserver/Plex\ Transcoder2 -hwaccel nvdec "$@" else /usr/lib/plexmediaserver/Plex\ Transcoder2 "$@" fi Plex versions > 1.15 have nvdec support enabled in their FFMPEG build - but it isn't invoked ever. Using this the GPU is successfully used for both encoding and decoding. This can be verified via `nvidia-smi dmon -s u` and watching the `dec` column.






