




UncleStu
Members
-
Joined
-
Last visited
-
I have a weird oddity that I don't run into too often, but curious if there is a fix for it or if I need to live with my work around. I have an older printer that has a scan to share function. Sadly it relies on NetBios (SMB 1.0) to be enabled. The printer is rock solid, except for this legacy SMB support. And it is on the latest firmware too. If I patch or reboot my unraid server, the printer will not connect to the SMB shares after the reboot. My other Windows clients can without any issue. If I stop the array, toggle the NetBios support from yes, to no, to yes, then click apply and start the array back up, the printer will connect to the share. I honestly don't know if I just need to restart the array or if I need to make that toggle change so I can click Apply for it to work. Any suggestions or known resolutions? unraid-diagnostics-20260715-1216.zip
-
I ended up deleting all the scheduled jobs and creating individual jobs, one for each VM to backup in the morning. I/E: VM1 on Wed, VM2 on Thur, VM3 on Fri. I just checked on this and I have three backups of VM3. One from Wed, one from Thur, and one from Fri. The scheduling completely ignores what was saved and appears to only backup the last saved config being shown in the left column. Also none of them were stopped, even though the Force Stop was enabled when the job was saved/scheduled. Curious if this plugin is still maintained or if I should be looking at a different one to backup my VMs.
-
I recently added a secondary cache pool to my server and noticed over the last couple of reboots that I am getting rpcbind warning messages. I don't recall these being there before. They only seem to happen after restarting the server and don't repeat after it has been online for a little while. The only NFS mounts that I know of (AKA remember) are to share my isos and backup location with my Proxmox server. I did have a 3rd NFS share, which I just removed after generating the diagnostics. This 3rd share used to be used by my Synology, which I have since retired. (and clearly forgot to clean up after it.) Any idea where these errors are coming from? I'm running unraid 7.2.4, which I know are part of the diags, but wanted to put that out there. Apr 13 16:55:37 unRAID kernel: svc: failed to register nfsdv3 RPC service (errno 107). Apr 13 16:55:37 unRAID kernel: failed to unregister udp with rpcbind Apr 13 16:55:37 unRAID kernel: svc: failed to register lockdv1 RPC service (errno 107). Apr 13 16:55:37 unRAID kernel: failed to unregister tcp with rpcbindunraid-diagnostics-20260413-1753.zip
-
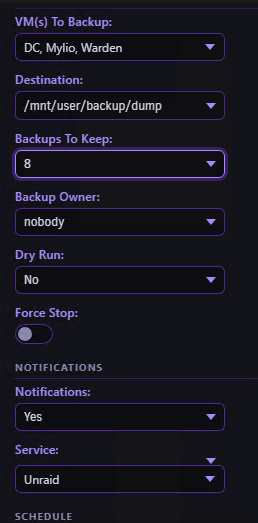
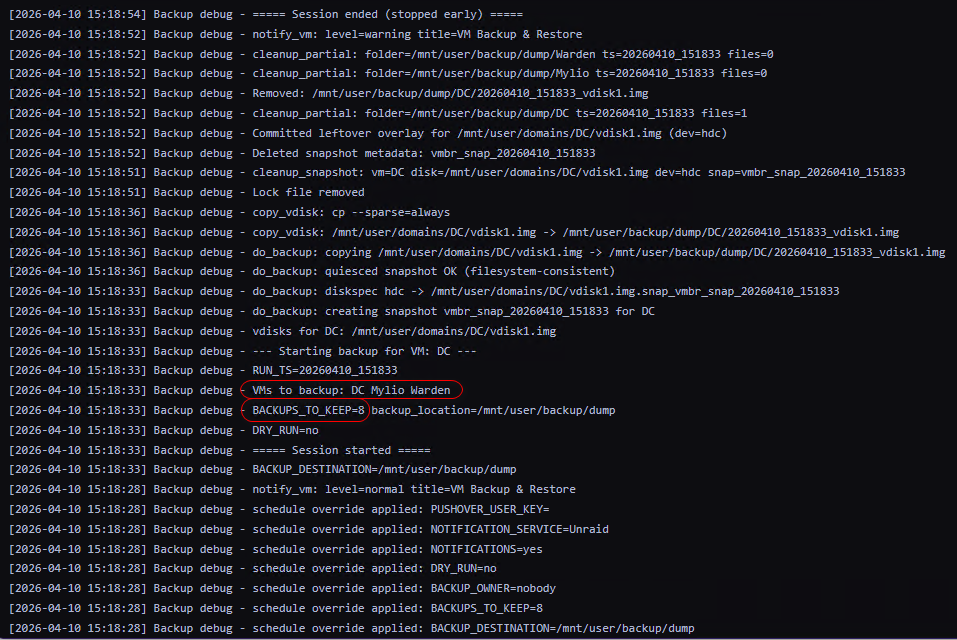
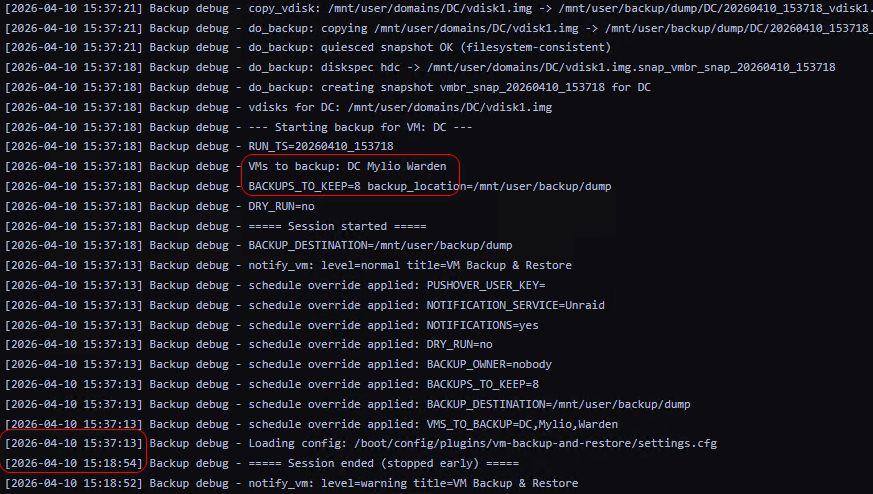
I have two scheduled jobs since one of my VM's I don't care so much about losing if I do. However when I "run" the second scheduled job it kicks off the job based on the config that is showing within the Backup window. The section down the left side. Semi long winded explanation, sorry. My original job I created was for 3 of my 4 VMs. I had a retention of 8 backups. I scheduled to run it this morning at 3 AM, and it did. I'm not sure if it actually shutdown my VM's though since the logs all showed "creating snapshot". I did have Force Stop enabled. Or so I thought I did. I have one VM that I must shutdown for it to have a clean backup. This afternoon I changed the retention from 8 to 7 and saved the job. However when I click on the bottom Run button for my Windows 11 job, it kicks off the job that was still showing within the Backup Config section. Backup Config section (Note the Backups to keep = 8) Scheduled jobs (note the Keep = 7 here) Snippet of my Debug logs: Note the Backups to keep AND VMs to backup. I ran the Windows 11 backup job. What kicked off was from the config screenshot above. Last note. The Force Stop option will not stay toggled on. I Edit my job and turn this on, then click save. It will remain on at this moment, but if I leave the page and return, it shows toggled off. If I edit the job again, it still shows toggled off. EDIT: Actually, it appears to kick off my original built job period. As a test I Edited my Windows 11 job so it would appear in the left config section. Enabled Force Stop again, Clicked Save. Then clicked the bottom Run. It proceeded to kick off a backup from my original job. Retaining 8 backups of my 3 VMs. I never let it run long enough to see if it makes it to my Windows 11 backup. That backup took 3 hours and I'm not during that mid-day. EDIT edit: Manually selecting everything in the config section and clicking "Backup Now" worked as expected. I have Force Stop enabled, so no snapshot. Looks like this option may be broken in scheduled jobs?


-
I think I remember a 6.x version changing the default from Enabled to Disabled. I just don't know exactly where/when. And yes, the help context is confusing. Probably an oversite of the text change when the default was changed. The User Script workaround works great though.
-
Is FTP supposed to be enabled or disabled upon startup? I'm 99% sure the answer is that FTP is supposed to be disabled upon boot. I remember my first unraid builds where FTP would start even though I disabled it. Now I have a need to have it enabled upon boot and I've noticed that is disabled after every reboot. I know of the User Script work around to start it after the array starts, but the Help section could use some clarification on what is default now. This screenshot is after a reboot.

-
UGH. But good that G.Skill has a lifetime warranty. Not my first time dealing with them for bad RAM either. Both my other unRAID servers have had bad RAM. TY, I'll bring it down for maintenance this weekend and run memtest.
-
OH! I just assumed that it would have been collected in the Diagnostics. root@unRAID:/var/log# cat mcelog mcelog: failed to prefill DIMM database from DMI data Kernel does not support page offline interface Hardware event. This is not a software error. MCE 0 CPU 28 BANK 1 TSC 1decad135796b0 MISC 80 ADDR 9369f8680 TIME 1759235008 Tue Sep 30 05:23:28 2025 MCG status: MCi status: Corrected error MCi_MISC register valid MCi_ADDR register valid Threshold based error status: green MCA: corrected filtering (some unreported errors in same region) Generic CACHE Level-3 Generic Error STATUS 8c2000409e4b110a MCGSTATUS 0 MCGCAP c16 APICID 58 SOCKETID 0 MICROCODE 12f CPUID Vendor Intel Family 6 Model 183 Step 1 Hardware event. This is not a software error. MCE 0 CPU 28 BANK 1 TSC 1e4849f79b50b5 MISC 80 ADDR 100f38680 TIME 1759266613 Tue Sep 30 14:10:13 2025 MCG status: MCi status: Corrected error MCi_MISC register valid MCi_ADDR register valid Threshold based error status: green MCA: corrected filtering (some unreported errors in same region) Generic CACHE Level-3 Generic Error STATUS 8c2000419e4b110a MCGSTATUS 0 MCGCAP c16 APICID 58 SOCKETID 0 MICROCODE 12f CPUID Vendor Intel Family 6 Model 183 Step 1
-
I can't locate a mce log. I don't have the Nerdpack installed either. Based on the general information that the Fix Common Problems sent me to, it sounded like I only needed the Nerdpack from version 6.10 or older. When I look through the attached diags, specifically looking at the syslog files, I am not seeing anything other than a random MCE Hardware error logged, but nothing about what it logged. Sep 30 05:23:28 unRAID kernel: mce: [Hardware Error]: Machine check events loggedThat's all I see. Many single MCE entries. Usually following a docker warning about an updated image being available or before a message about my disks spinning down.
-
Overnight my Fix Common Problems plugin reported Machine Check Events started logging. Everything was perfectly fine yesterday. I'm not sure where or how to read the diagnostics to know what the issue is. I don't see anything standing out in the system log. unraid-diagnostics-20251001-0910.zip
-
I wonder if this is another company victim to the Salesforce/SalesLoft security incident?
-
Pretty sure @spyd4r was asking in regards to the telegraf container. I have had mine pinned on 1.20.2-alpine for a long time, but my logs were getting filled with the warning about the inputs.docker API being depreciated. Following this post by @cassiusdrow, I was able to upgrade off to something newer. I tried going to telegraf 1.34.3-alpine, but got the same inputs.diskio errors. I ultimately went back to 1.24.4-alpine and my logs are quiet. Which is what I was after in the first place. If the fix is easy, I would like to go to something newer, less prone to vulnerabilities, etc.
-
Not that it matters since you have keyed in on the issue. I am in the process of moving disk 2 so I can remove it. I excluded it from all my shares beforehand. I just checked my split is set as what I believe is default. "Automatically split any directory as required". Mover has been running for several hours and everything is looking good.
-
Second parity check finished with 0 errors.
-
I just added two drives to my array with the intent to move the data off two other drives and then remove the initial two for repurposing. After reading the release notes, the mover utility still takes your config settings into effect. Making me wonder if you have most-free set for your share(s). Perhaps your disk 5 has the most free space and your share settings are set to most-free. I could potentially see this as an issue to where it would move it off disk 5 and onto disk 5, then delete the file. If this is the case, almost seems like the mover utility need to exclude the source disk you are moving off of. I was thinking about playing it safe and excluding my two disks I'm pulling out from the shares before running it. But now I'm scared to lose anything.







