




Lassley7
Members
-
Joined
-
Last visited
Everything posted by Lassley7
-
im getting this when i tried to do the move to TMP licensing.
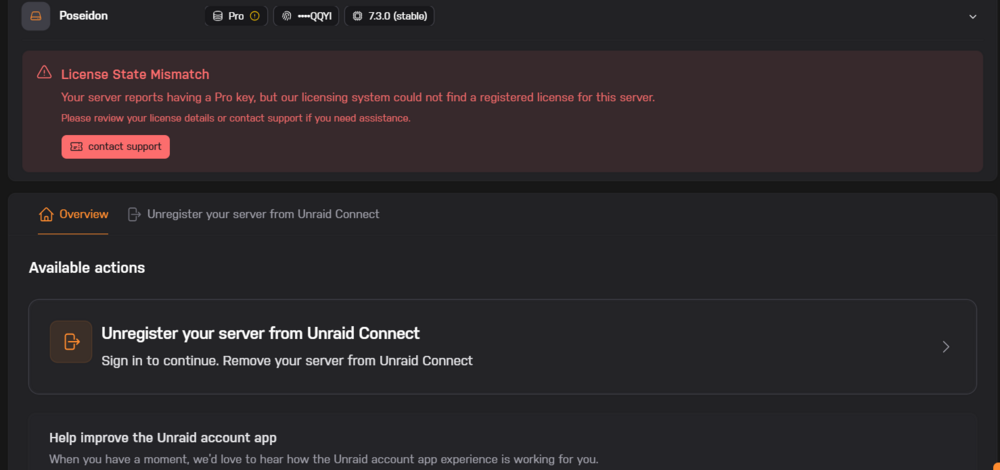
-
anyone?
-
im trying to setup some containers to route through tailscale via swag and a A name pointing to swags tailnet IP infact i have already setup one of the containers and all is working fine, however i was trying to setup filebrowser and noticed that docker exec -it swag getent hosts filebrowser was returning nothing, so i disabled tailscale within swag and ran it again and it was listed.. i thought maybe it just needed to see it and then i could re-enable tailscale.,, i was wrong so now what? for some reason with tailscale enabled in swag cant see the container.. and yes they are on the same docker network
-
i got a email today that i linked below.. i do not own a r520 nor do i use IDrac. does this mean someone was able too get into my unraid account? is there anything i need to check? so far i have logged out of unraid.net on my server. changed my password, and changed my auth provider. is this good enough? any way i can tell if they are still connected? any help is much appreciated
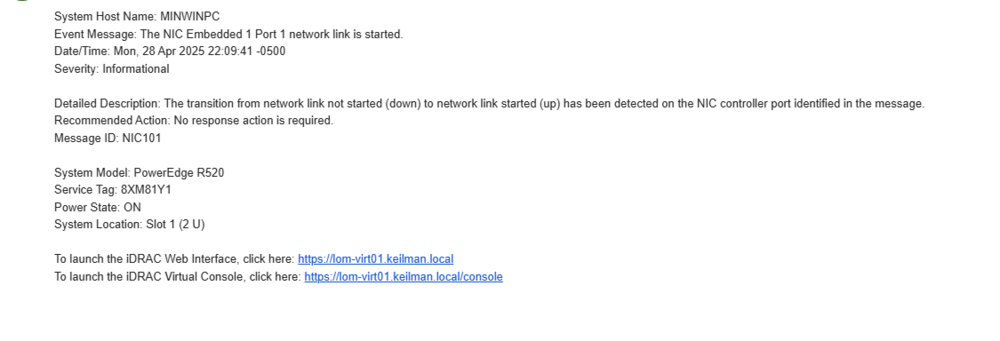
-
thanks @JorgeB
-
i recently came in possession of a few 8tb drives out of a synology nas, during the initial pre clear one of the drives had UDMA CRC errors since then i have checked all the cables and reseated the drive in its bay, i ran a extended smart test and it passed, and the count has not gone up. would you say im safe too go ahead and add this drive to the array? here is the extended test results.. anything stand out? thanks in advance WDC_WD80EFZX-68UW8N0_VJHARRJX-20250409-1004.txt
-
I hope I’m not missing something but I tried updating via community apps and it pulls the update, says it’s been updated. Then goes back too there’s an update available. Is anyone else seeing this?
-
So something is kicking the server off/on from the internet. Does the diag show my network settings? Do they look correct? I did jump quite a few versions. So. I wonder if I need to update my network settings
-
Idk if this is in the diag logs but I am seeing this error as well? Could this be causing it? More importantly what is this error? P.s for some reason I can’t wrap the code via my phone.. ```oseidon nginx: 2025/02/12 09:25:37 [error] 11327#11327: OCSP responder timed out (110: Connection timed out) while requesting certificate status, responder: r11.o.lencr.org, peer: 23.64.114.214:80, certificate: "/boot/config/ssl/certs/certificate_bundle.pem" Feb 12 10:30:25 Poseidon kernel: WARNING: CPU: 10 PID: 1254906 at fs/notify/fdinfo.c:55 show_mark_fhandle+0x77/0xe6 Feb 12 10:30:25 Poseidon kernel: CPU: 10 PID: 1254906 Comm: lsof Tainted: P O 6.6.68-Unraid #1 Feb 12 10:30:25 Poseidon kernel: Call Trace: Feb 12 Feb 12 16:04:45 Poseidon kernel: PMS BTQ[1786413]: segfault at 14c500000068 ip 000014c5deeb6d0f sp 000014c5addb0558 error 4 in ld-musl-x86_64.so.1[14c5dee6f000+53000] likely on CPU 10 (core 4, socket 0)```
-
Sometime between 7am-10am yesterday morning. Sorry I can’t be more precise
-
Sorry I should have explained that the above diag was when the system hung up and I didn’t reboot only thing I did was reset the router states to get back in. If nothing else jumps out I know this is probably unrelated but can a container issue cause this? My plex containers has been on the ritz due to a corrupted db but I don’t see that causing the system to hang up?
-
I will do this. But I am assuming that everything thing else in the diag looks ok?
-
hmm i do see this happening alot in the sys log. is this normal activity? Poseidon kernel: br-2b0f514dcdc9: port 10(veth91f1544) entered disabled state Feb 12 16:16:05 Poseidon kernel: veth923cc83: renamed from eth0 Feb 12 16:16:06 Poseidon kernel: br-2b0f514dcdc9: port 10(veth91f1544) entered disabled state Feb 12 16:16:06 Poseidon kernel: veth91f1544 (unregistering): left allmulticast mode Feb 12 16:16:06 Poseidon kernel: veth91f1544 (unregistering): left promiscuous mode Feb 12 16:16:06 Poseidon kernel: br-2b0f514dcdc9: port 10(veth91f1544) entered disabled state Feb 12 16:16:06 Poseidon kernel: br-2b0f514dcdc9: port 10(veth996ffa0) entered blocking state Feb 12 16:16:06 Poseidon kernel: br-2b0f514dcdc9: port 10(veth996ffa0) entered disabled state Feb 12 16:16:06 Poseidon kernel: veth996ffa0: entered allmulticast mode Feb 12 16:16:06 Poseidon kernel: veth996ffa0: entered promiscuous mode Feb 12 16:16:06 Poseidon kernel: br-2b0f514dcdc9: port 10(veth996ffa0) entered blocking state Feb 12 16:16:06 Poseidon kernel: br-2b0f514dcdc9: port 10(veth996ffa0) entered forwarding state Feb 12 16:16:06 Poseidon kernel: br-2b0f514dcdc9: port 10(veth996ffa0) entered disabled state
-
ever since updating too 7.0 im randomly loosing connection to my server, as if someone is ripping the ethernet cable out.. im having a hard time pinpointing what is happening i do know that when it happens my internet is up and stable. i can also see the DHCP lease, and i am able too ping my unraid machine via another local machine. im hoping someone here can help me pinpoint what is causing this. when this happens unraid connect doesnt catch it and still reports the machine as UP but wont let me manage. the only fix i have found as of now is restting my router states table or a manual reboot. here is a diag. thanks in advance poseidon-diagnostics-20250212-1814.zip
-
Then what was throwing the errors to begin with? It had to be bad disk/data…
-
The disk wasn’t good, that’s why I got into this mess to begin with. That’s why I’m confused as to why it’s now showing good, when nothing has changed other then the data is on a new disk in the array and this one is now empty.
-
From the beginning we narrowed this issue down to a bad connection/drive. After doing all the steps to recover my data off that drive, I then ran 2 extended smart tests. And they both passed without error. Does this mean the drive was good? And the data that I copied back over to the array was not? I’m confused on how it was a bad drive and now it’s showing good. Should I put this drive back in the array? I posted the smart test above
-
But IF it’s not, will that corrupt parity again? Folks on discord said unraid doesn’t care about the data only the sectors? Also would you trust putting this drive that was throwing errors back in? Now it reads as a good drive so that doesn’t make sense to me. That tells me the data that was bad on that drive is now back in the array..
-
So I got everything back up and running. I’m going to assume that corrupted data can throw errors again? I moved all the data without issues too a new drive, once the “bad” drive was empty I ran 2 extended smart test and both said passed 0 errors.. doesn’t this likely mean I likely moved bad data back too my array? And the drive was actually never bad… should I run a new parity sync? poseidon-smart-20230905-0505.zip
-
Will krusader do this? Do you have a recommended tutorial for rsync for my situation? Thanks for all the help recently
-
What app would you recommend? I’ve never had too copy over “bad” data before anytime I’ve had a drive fail I’ve been able too use the proper way of emulating and rebuilding its all replaceable data on that drive so I’d rather skip ANY that could be bad and not risk it “trying multiple times first”
-
Will it skip them or will I have to tell it to skip them using UD? So a bulk copy should be fine? Also is a party sync after copying with UD needed right away
-
How would you handle this once the sync is done? Could the errors be from empty bits? “Bit rot” or likely in the files? Would u copy a little at a time and test? I don’t want too corrupt my array again
-
I followed The "Remove Drives Then Rebuild Parity" Method as a bunch suggested on discord… they said to then mount the disk with issues using UD and copy it over… I hope this wasn’t a mistake
-
poseidon-diagnostics-20230901-0543.zip


