




nexusjosh
Members
-
Joined
-
Last visited
Everything posted by nexusjosh
-
A good idea. But when I shut down my array, I always manually shut down all of my docker containers and VM's, then shut down the array, then shutdown, or restart UnRaid. Right now I have one windows VM, and 2 Dockers, one being Plex, and the other being Lancache.
-
Three posts up from yours, I attached it. @Arbadacarba Yes, that is possible. The question would be: What was causing the extremely long shutdown. If my server starts acting up again, I'll post here. I'll leave this thread up for a few days, before marking it as Solved.
-
I don't understand my server. I changed a bit of the physical config, and now its purring better then ever. The only other issue I'm having is trying to add a Disk 8. When I add the disk, and start the array, it sort of just doesn't do anything. The last time I added a disk about a year or maybe two ago, it prompted me for permission to format the disk, then just added it to the array. Has that changed?
-
swiftserver-diagnostics-20221025-1844.zip
-
OK so any ideas on why UnRaid is so ungodly slow, any indication from the logs?
-
What sort of error would it give, or where would it display any error it comes across?
-
Hey guys! I had a scare earlier this year, when my server kep't crashing. When I was doing through mountans of troubleshooting, I attempted to reset my OS on the Flash Drive. I think it perhaps has lead to issues now? Over the last couple of weeks, I've noticed my server acting... for lack of a better word, strange. Slow, and I recently attempted to upgrade it with another disk... which hasn't worked. Even now, I reset the server, and its doing a Parity Check (Even though it was a clean shutdown), and its stuck paused. Even when I attempt to Stop the Array, it takes Forever to execute the command, and stop the array. Same with Reboot or Shutdown Any ideas? I have asked in the past if there is any way to verify OS files, and no-one has answered that question. It feels like a classic OS error. Here is the prior thread: swiftserver-syslog-20221025-0207.zip
-
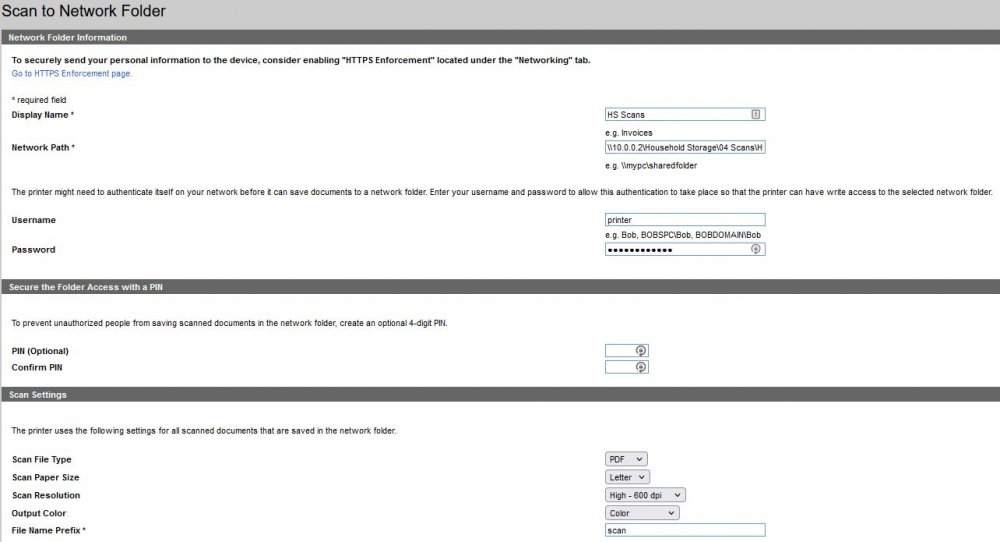
Its sad no-one has replied. I just got a used M477fdn, and was tinkering with its settings. I wanted to get Scan to Network functioning, but when I do "Save and Test" it fails. I made the printer its own user in UnRaid. The fields that could be wrong are "Network Path" and I have "\\10.0.0.2\Household Storage\04 Scans\HP StN" 10.0.0.2 being my server address. "Household Storage" being the Share and the the nested folders from there. If anyone has set this up, and can help myself and @henris I, and no doubt he would be thankful.
-
At this moment, I'm going to say its a tentative resolution. From what I understand, various BIOS updates, not to mention the most current release back in 2019, had various micro architecture updates. When the MB called the CPU's to do something specific (I am no Engineer) and the CPU's couldn't. It'd crash. It almost always crashed when under load, but not always. I've had it under a full load, at 80-95% CPU load, which was causing the system to crash, and it is now stable. I remember when I originally purchased the MB, I saw on the site "E5-2600 v2 family" I googled that, bringing me to This page. The page listing all CPU's in the generation. I didn't realize at the time, that the CPU had to also be 26xx. So it worked for YEARS, and it wasn't until I was upgrading the system, and decided to do a BIOS Upgrade. The System STILL BOOTS, and it isn't until there is a call from the BIOS to do something that the CPU is too new to? To not. Its quite sad that SuperO didn't just support the newer CPU's? They OBVIOUSLY work. But it is what it is. @m1a8x2 If you want to try the same thing I did. Look at the version of your BIOS, and see if there is an earlier version online. Or contact your motherboard manufacturer directly, and request the earlier BIOS rev. they have for "Troubleshooting Purposes" All in all. I feel like there is probably a custom Bios somewhere on the interwebs. I might look for it at some point, because after I rolled back the BIOS, I've found the actual menu to be strangely buggy. Its also funny, a few months ago, I was going to upgrade the processors. But now, I'm certainly NOT going to push my luck. Though perhaps I could try and get my hands on a pair of E5-2697 v2... Better, and In spec. Hmm...
-
Update: I sent the SuperO Tech the same message I sent here, and he called me quickly. He reviewed some pics I sent, and took it to a couple of different departments. It was pointed out that it could be the two CPU's I have paired with my MB. Since officially the Motherboard only supports Intel® Xeon® processor E5-2600 and E5-2600 v2 family, and I have two E5-4610 v2. So he sent me one of the original BIOS builds, and I've rolled back the BIOS. I have it under full load now. so we'll see what happens! Its insane that a "Non Supported CPU" would just be unstable, and the BIOS wouldn't just reject the CPU upon boot like every other Motherboard I've ever seen does. This has all been a roller coaster. If this BIOS Rollback doesn't fix my issue, I'll try that. Information Edit: The BIOS I was provided was x9dr3p3. I'm attaching it here, in case anyone in the future needs it. Fair warning though, on my system at least the BIOS interface is strangely, buggy. You can't left arrow to the save menu, instead you have to press F Keys to save BIOS changes, restore defaults, etc. If I note any other strange bugs, I'll update this post. x9dr3p3.c04.zip
-
Update: Resetting BIOS settings made no difference. The SuperO support tech called me, and we discussed what was going on for a bit. He said the only thing it could be at this point is thermals. I re-seated both CPU's, thoroughly cleaned the CPU's and heatsinks of new paste and applied new thermal paste. I then put the server under full standard load, and after about 20 minutes under full load it reset. At the time I was monitoring the tempatures, and on both CPU's, the temps didn't go above 40C.
-
Update: No change. Continuing talks with SuperO Support. I just returned all bios settings to Default, so we'll see if that makes any difference?
-
Update: I just swapped the PSU from my Server and gaming rig, so we'll see if that makes any sort of difference. We'll see if the server continues to crash... Or my gaming PC starts crashing. Edit: Aaaaaaand Crashed! Server crashed that is. New PSU made no difference. Sigh.
-
So, from the IPMI logs, maybe it is the PSU? But maybe its just... Sort of failing, because of the Sata Rail? Ugh.
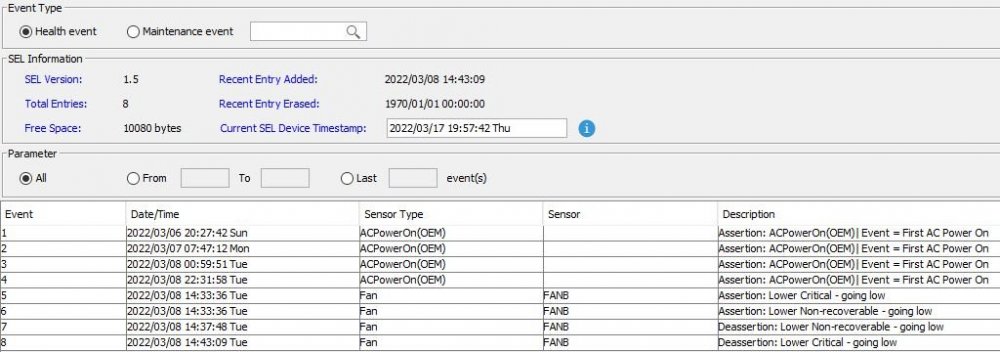
-
Hey its all good. Its something. When the system crashes the IPMI does not. I've been busy the last few days, so I haven't been able to sub the PSU. If it IS the PSU then this will have been a the 2nd PSU in 5 years, which is a bit crazy, but we'll see. And if it is, which PSU should I purchase to be the permanent replacement?
-
Yes. Though I always figured that the IPMI would error out, if the voltages went out of spec? Attached, Though you really can't see as of whats going on really, all that well.
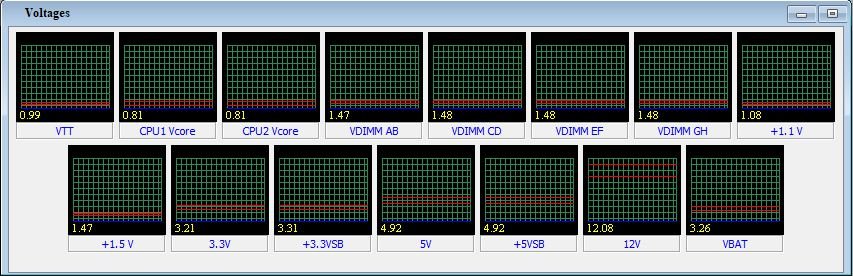
-
Its possible. Today, I'm going to try and re-seating the two CPU's, see if that makes any sort of difference. If not, I'll see if I can find a CPU I can plug in and see if there is any difference. The PSU in it is only about 6 months old, EVGA Super Nova. I don't have a spare one on hand, and at peak, according to the UPS, the server only pulls 300 Watts, and the Super Nova is rated for 1,000. Perhaps, given my server has so many Exos drives, the PSU is having a hard time with so much pulling from the 12V rail? Le sigh. I shall have to investigate. Edit But then, before I removed all of plugins, the server wasn't doing anything when it was power cycling. The Array was just On. The VM's & Docker Containers were off. This problem is so inconsistent its ridiculous.
-
Update: Everything was going so well, I was moving the server back to full normal production, and it just crashed once more, while under heavy load. Temps look fine. Nothing in the IPMI event log. For giggles I even just replaced the BIOS battery! (But tested the one that was in the system, and it was just fine.) Thoughts, ideas, anyone? Edit: Pain.

-
Update: So, I've installed my usual dockers once more, and my server is back to its normal production. for the last couple hours. Uptime: 3 Days, 2 Hours, 26 mins and counting. Could it have been a VM all along? But then I wasn't running the VM when it was crashing. We'll see what happens after a couple of days. I'm going to update the above post for giggles as I complete the smart tests on each drive.
-
Update: I am So confused. This issue is so... RANDOM!!! Ran just fine for 2 days once more, Created a New VM to replace the old one. And it has been running for 9 hours without issue. Granted the VM just exists, and is running win 10. I haven't put it to work yet. Will update tomorrow, when I put the VM to work. Could it have been an old VM image that is roughly 3 years old? 😰 Current up time is 2 days, 13 hours, and counting. Edit: Oh, and I am having it grind through extended SMART tests. It takes about a day for each drive. Parity: Completed without error Parity 2: Completed without error Disk 1: Completed without error Disk 2: Completed without error Disk 3: In Progress Disk 4: Disk 5: Disk 6: Cache: VM Drive: Hot Spare:
-
Update. It appears to be reverting somewhat? But I have drilled down to potentially what appears to be the issue? Upon getting my VM back up, that is a dev VM for my small business that has some reasonable HDD IO, file transfers, etc, the server is back to crashing after a couple hours, it appears. As it completed a Parity check without issue... I'm back to square 1. Could it be one of the drives? If so, I don't understand why a Parity check would finish with no issues. Maybe something is going on with the HyperV? But I just generated a new one, and loaded up an older VM... The only other thing I did was add Unassigned Devices and re-added an old VM image. At this moment, I'm going to run an extended self test on each drive, and see if any errors pop up? Any thoughts? Ideas?
-
So, the server is far more stable, but still crashing. It was on for 6 days straight, completed a parity check, but I woke up, checked it, and it crashed one more last night.
-
OK, been on and stable for almost 4 days now. Going to grab unassigned devices and re-add my VM, and verify stability with it first.
-
So, Instead of launching it into safe mode, I reset the server again, and started the array. Perhaps, it crashed becasue I didn't restart the server after clearing the plugins? Well, its been running for 29 hours now, and counting, sooo... Perhaps it IS fixed. I'll update again either 1: The server crashes again. 2: if it is on and stable for 3 days. And I'll begin installing plugins, re-add my VM, and re-add the docker I use.
-
Sigh. My machine still crashed after about 18 hours of running. I'm going to boot it into safe mode, and validate it runs fine in it. Right now, I'm back to having no idea what is causing the hard reboots. It seems more stable now though? I guess?



