pappaq
Members
-
Joined
-
Last visited
Everything posted by pappaq
-
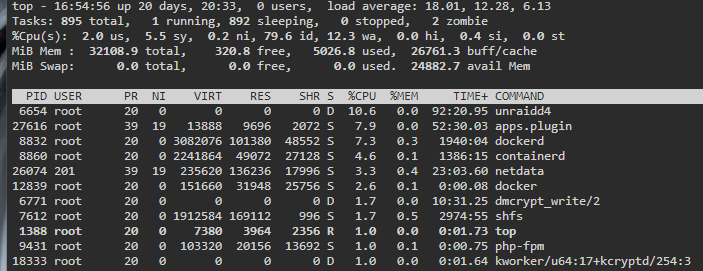
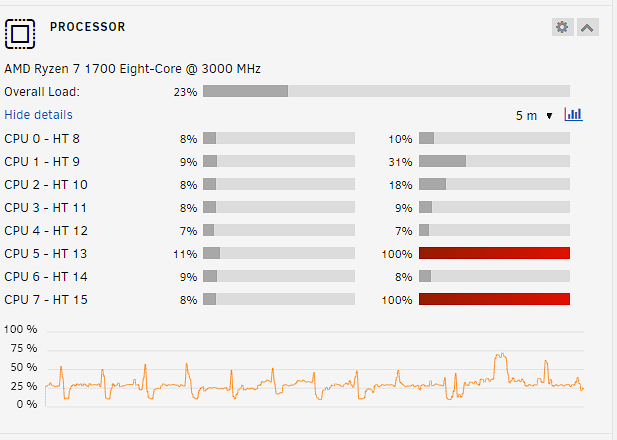
Hello everyone, I'm at the end of my tether...for weeks now I've been trying to fix iowait problems with my Unraid system. Whenever I think I have found the reason for iowait, the problem reappears after a short time. I don't know what to do anymore. First I changed my BTRFS cache to ZFS, which improved the performance a bit at first. (incl. upgrade from 6.9.2 to 6.12.4). Then, when high iowait reappeared, I suspected my download cache SSD. I replaced it, it was a Crucial P2 with QLC memory, which was very slow when writing. Now I have a WD Black in it, which works so far so good. Tonight I suddenly have completely absurd iowait numbers that I can't explain. Unraid is becoming less and less usable for me. The hours of fixing I've put in over the last few weeks are unbelievably high. Please, could someone help me with this? Whatever information you need, I'll try to provide it. One or more cores are always spiking to 100% because of iowait. dringenet-ms-diagnostics-20231115-1952.zip
-
Hey, thanks for pushing me with my nose on it...I needed the extra kick. I deleted all my 5 year old Filebot Docker, installed this one and bought a license. Everything works like before, I just had to look properly
-
Hey, maybe I'm searching for the wrong words but I can't find information about this docker regarding running headless, so without GUI. Is it possible to just give it the right renaming scheme and its input and output and let it run and everything is done automatically? My super old filebot instances do that but are running very old javascript versions...
-
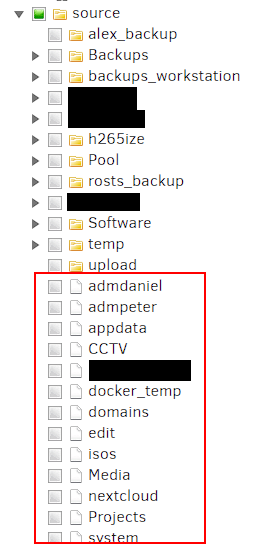
Hey there, I've got a problem with my duplicati configuration. Since I've changed my cache pool to ZFS duplicati can't backup the folders which are stored on chache. In the backup configuration window it looks like this: The folders in the red box are not shown as folders and the backups can't run. Any ideas?
-
The stutter only occures when copying to the cachepool and only when bigger files are copied. I'm fine with this because the overall performance of the system has increased dramatically.
-
After moving away from btrfs for the caches there is nearly no iowait. The performance is so much better, it's absurd. Thank you JorgeB for your support!
-
I've got no problem with the encryption overhead but the stuttering in transfers. That seems odd...
-
I did start dockers one by one and it seems like it only occurred when transcoding from emby was done. But not everytime. When zfs is not the solution I'm going to build up my emby installation from scratch.
-
Hello there, in the process of converting my cache pool to zfs encrypted I noticed spikes in CPU usage, while the mover is moving the appdate etc. back onto the cache. I've then tried to copy a file from an SSD to the cache. When writing to the cache the CPU spikes and the copy process pauses for a few seconds, kworker tasks ramp up and the copy process continues. I've got no issue with zfs using CPU but with sluggish writes. On the other hand copying FROM the cache pool to the said SSD does not trigger this behavior and everything runs smooth. My concern is that this haltering behavior has an impact on the future use by dockers and VMs etc. Is there anything I can do about it or is it an expected behavior? I've intentionally downgraded to 6.12.3 because of known issues regarding AVX2. dringenet-ms-diagnostics-20231022-1026.zip
-
Currently moving all data from my btrfs caches to convert them to zfs...lets see if this helps.
-
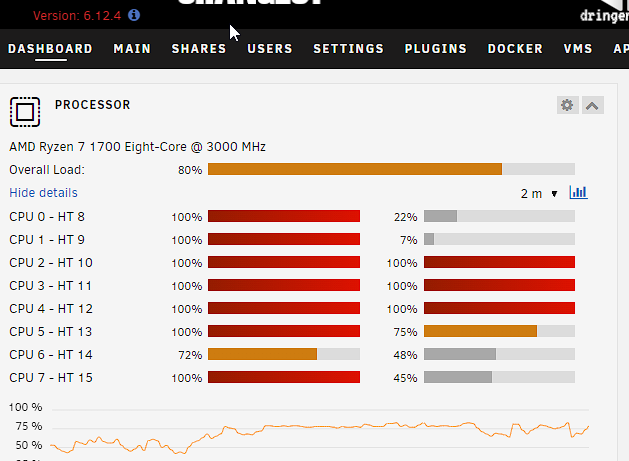
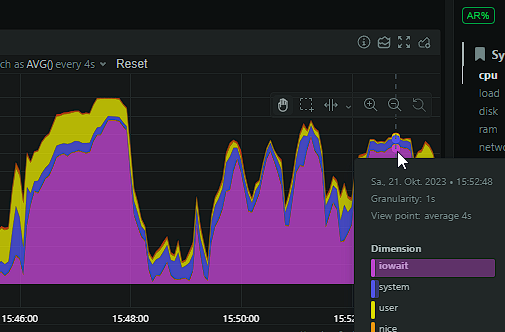
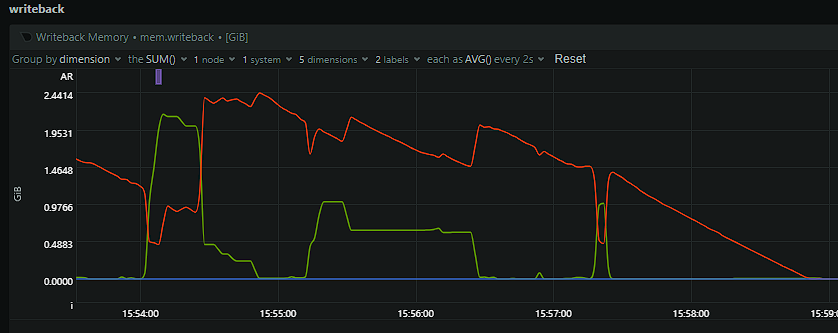
I've update unraid to 6.12.4, changed all possible shares to exclusive shares and updates everything I could. The same problem persists. I've even changed the transcoding of emby to the RAM. It seems like it is randomly doing memory writeback and that's causing the iowait to lock up the system. But I can't pin down what is causing this. Any ideas? dringenet-ms-diagnostics-20231021-1605.zip
-
Thank you. Will take some time to change everything. Will report back here.
-
The behavior occures all the time not only when copying files and I can't pin down what it is.
-
You mean like this?
-
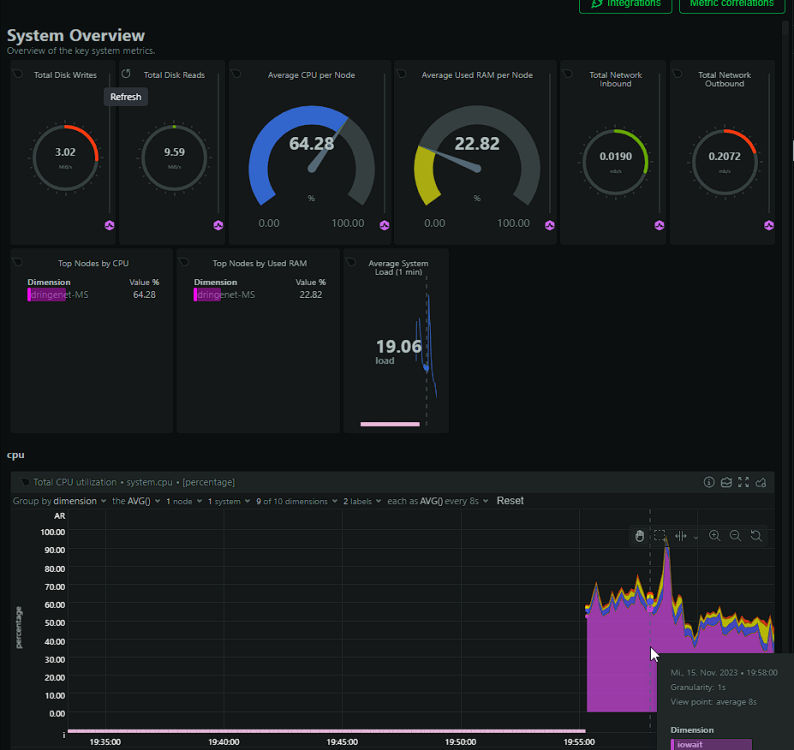
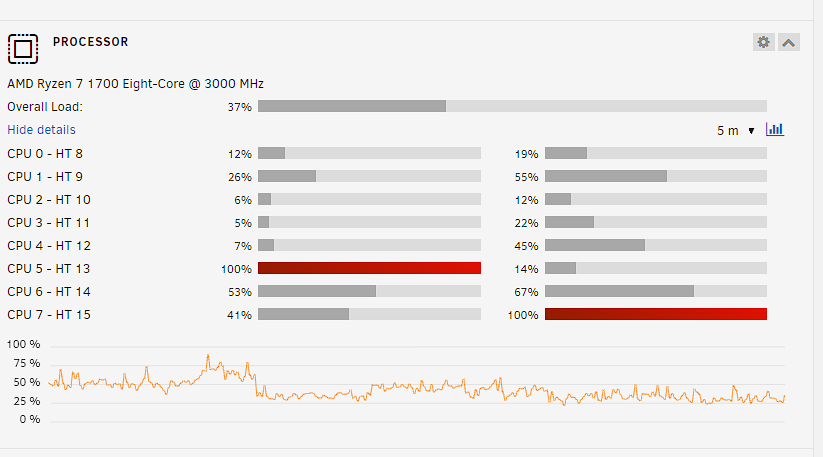
My problem has returned, worse than ever. The system is pretty much locked up when the iowait issue occures. Seems like memory writeback is the issue. Is there something I can do? I've found many threads about it but never a solution for it. Here some screenshots from my netdata and the diagnostics. dringenet-ms-diagnostics-20231021-1038.zip
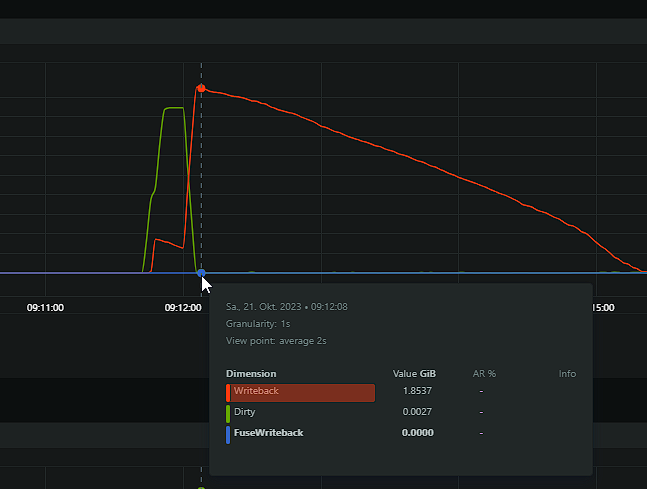
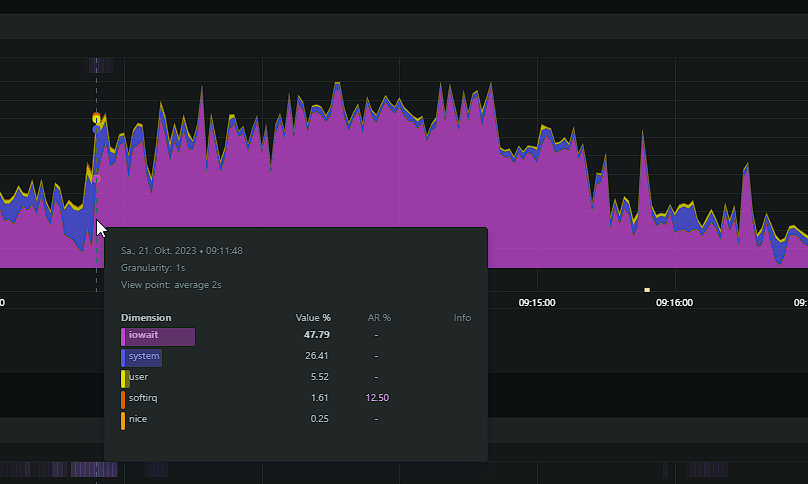
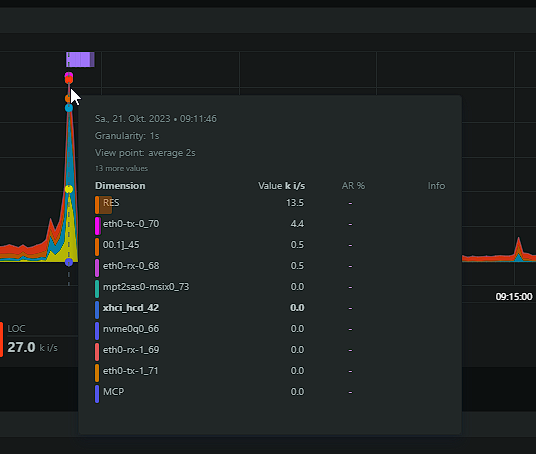
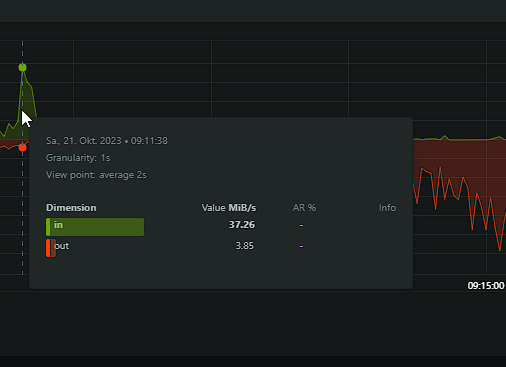
-
With "Repair corrupted blocks" enabled, I assume?
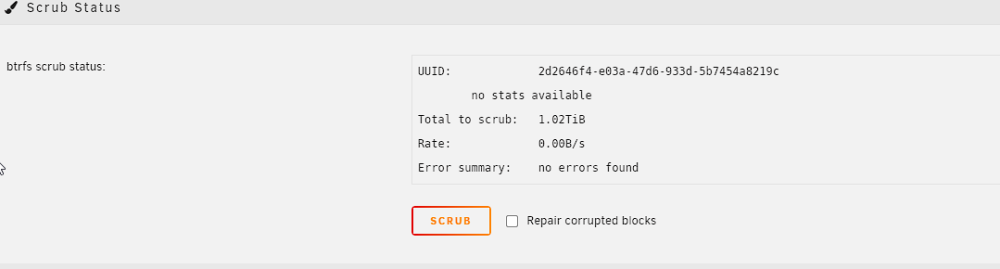
-
I am moving the files off of the App_Cache to my array, will replace the RAM on Thursday and replace the older 500GB SSD in the App_Cache for a 1TB SSD, to get an even 1TB App_Cache instead of the 1Tb + 500GB combo which resulted in 750GB. Was on my list anyway. I will recreate the docker-image then as well. How do I scrubb the two pools? Starting with the Data_cache, because the data of the other pool is currently moved. Thanks for your support!
-
I've removed two RAM modules and ran the test again for an hour and did not get any errors. Tried now to get the server back to run until the new RAM arrives but the docker service fails to start anyway. I'm getting this error. Did the RAM corrupted something? I've got a backup of all my appdata... New diagnostics are attached. dringenet-ms-diagnostics-20231002-1402.zip

-
JorgeB, you have answered my question in another post: Just ordered unregistered ECC! Thanks for the support!
-
Looks like we have a Winner. It was up to 25 errors when I stopped the test. I'm thinking about getting unregistered ECC memory now for replacement. My Ryzen setup should support it. I'm currently reading up about it, my knowledge about memory is a bit rusty. Would it prevent errors like these?
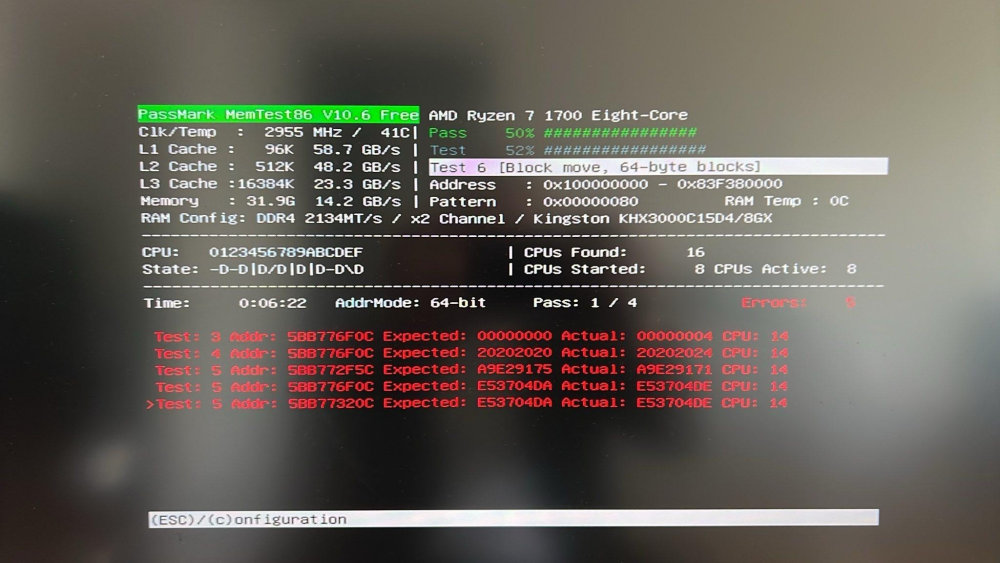
-
You mean RAM memtest? Okay.
-
Hey there, this morning I woke up to an error on my server. The Docker service didn't come up after the backup process this night. It seems like one of the cache drives in my application cache pool is failing. Both drive logs threw btrfs errors. After a reboot the cache and docker service are up and running again. I've read a little bit here in the forums and it seems like one of the two drives is failing. But I can't really figure out which one. Could somebody help me figuring out which one or if I have to switch both? Here the diagnostics and the smart logs of both drives. Thanks in advance! dringenet-ms-diagnostics-20231002-0808.zip dringenet-ms-smart-20231002-0822.zip dringenet-ms-smart-20231002-0823.zip
-
Hello, as stated in the title my server has detected hardware errors, says fixcommonproblems but does not tell me what is wrong. Here my diagnostics, maybe someone can help me! dringenet-ms-diagnostics-20230702-1501.zip
-
Yeah, thought so. Gonna do that tomorrow evening. Thanks for you feedback!
-
Unfortunatly nothing changed after shutting down the VM. The wa is still high and random cores are up to 100% load. Here are my diagnostics after shutting down the VM. Do you guys have an idea? dringenet-ms-diagnostics-20230424-1652.zip