




pappaq
Members
-
Joined
-
Last visited
-
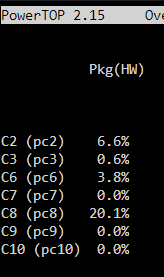
Thank you. I assume the HDDs are NOT spun down, right? Otherwise that would be a massive idle powerdraw tbh.
-
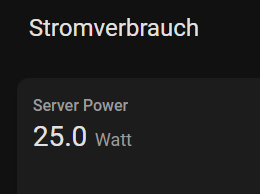
Very interesting. Could you provide the powerdraw of the system?
-
Inzwischen läuft das Setup seit diesem Post durch. Jedoch habe ich mit den Controllern ab und zu etwas zu kämpfen, da sie manchmal eine Platte nicht mehr erkennen. Vor allem bei einem Reboot, dann fehlt einfach eine. Einziger Workaround ist das Ausschalten und dann wieder Anschalten, dann funktioniert alles einwandfrei. Jedoch habe ich mit dem Setup immer wieder iowait Probleme. Und ich weiss einfach nicht mehr, wo ich noch suchen soll...hat sonst wer mit der Board und Controller Combo ähnliche Probleme? Ich bin für jeden Hinweis dankbar. Grüße
-
If these errors won't rise, it should be fine, right?
-
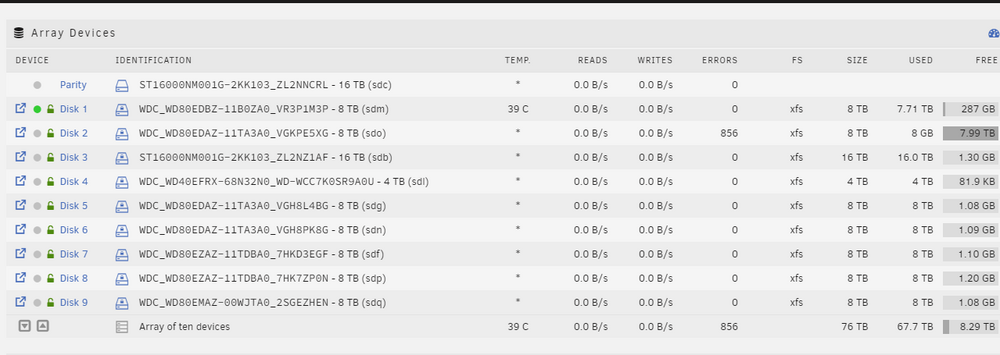
In the UI I see this, still:
-
I've run 2 parity checks now. One correcting, one without. The disk still has its 856 Errors. Is there still something I should do? Here the diagnostics. dringenet-ms-diagnostics-20241206-1941.zip
-
Will do so, tomorrow! Thanks.
-
Here you go: dringenet-ms-diagnostics-20241203-2008.zip
-
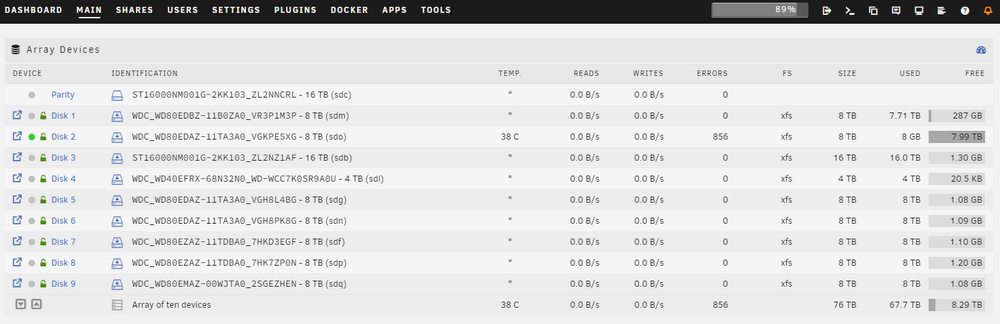
Hey there, my system reported errors on one disk during parity check. I canceled the parity check to lower stress on that drive so I can securely scatter the data from that disk to the other disks, because my plan is in order to secure the array again I am going to exchange the current parity with a 18TB drive and fill in the disk2 with the old parity drive. Before I commence, I wanted to ask if these errors are an indicator for a failing drive? I've done a short SMART selftest and the drive seems okay. Thanks for your input in advance!
-
Ich bin immer noch auf 6.12.4. Daran liegt es wohl nicht. Aber wenn es dadurch nicht mehr zum Abmelden der Platten kommt, dann nehme ich die 2,5-3W hin.
-
Ich habe seit dem Flash auf die neue Version eine Erhöhung des Stromverbrauchs des Servers um 3 Watt im Idle. Ist das hier auch schon jemand anderem passiert?
-
Danke, dann werde ich es zunächst auch erstmal mit der Version probieren dieses WE.
-
Welches ROM hast du geflasht? 11080000.ROM oder 11180000.ROM?
-
Moin, entschuldige, dass ich jetzt erst wieder hier reinschaue. Ich habe die Notifications aus gemacht für das Forum hier. Freut mich aber, dass du meinen Build nachbauen konntest. Ich habe inzwischen ein ähnliches Problem mit den Controllern. Ich konnte noch nicht einkreisen, welcher von den beiden dafür sorgt, dass HDDs nicht mehr erkannt werden beim Neustart, aber ich denke auch weitere ioWait etc. Probleme werden bei mir davon ausgelöst. Bin gerade bei der Fehleraufnahme. Zu deinem ASPM Problem: Auf dem Screenshot kann ich auf Anhieb nichts erkennen, das bei mir anders aussähe. Welche PCIe Slots hast du denn nun im Gebrauch?
-
Scrubbed the pool again and the errors are gone, for now...the scrub speed was very good though. The speed is slow anyways and the iowait is super high when there is traffic on the zpool...




