




tone
Members
-
Joined
-
Last visited
-
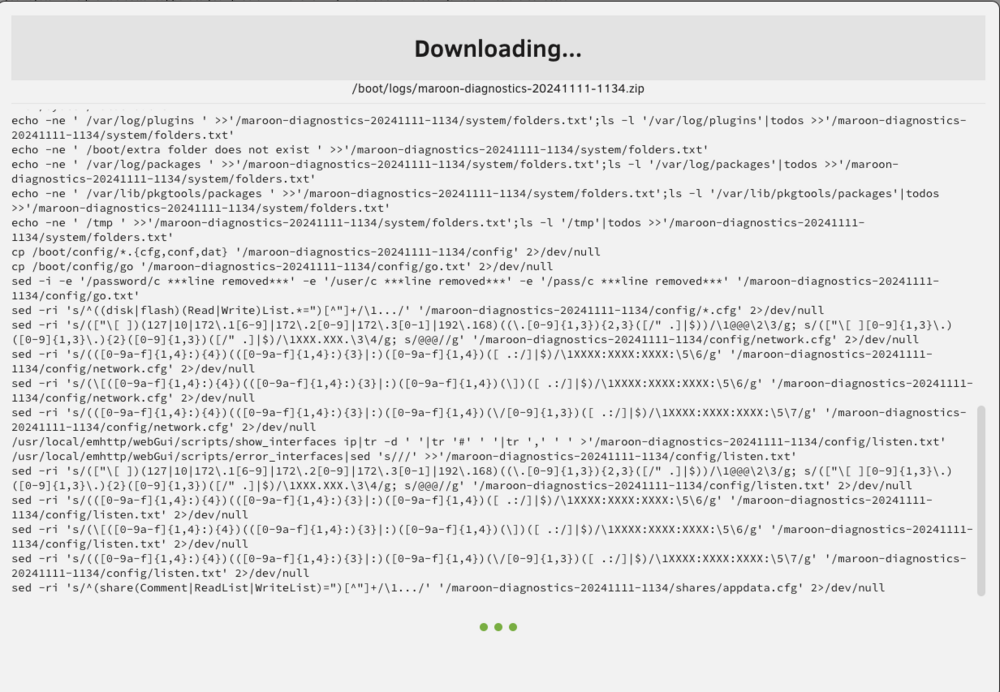
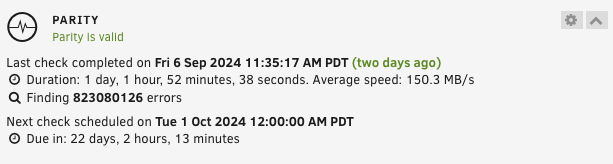
Ok update here. I actually turned off the ZFS backups (uninstalled Sanoid and the ZFS Plugin and disabled the user scripts) and had not had an error for 1+ month. I also increased the fans so there was better cooling in the case and on the HBA. Anyway, I had an error last night but now on only one disk (Disk 6, which was the ZFS backup target): Log has new errors too: I am not able to download a diagnostics as it freezes/hangs: Here is the disk log for Disk 6 (sde): LMK if this should be a new post/topic altogether. Any idea what I should do? TIA!
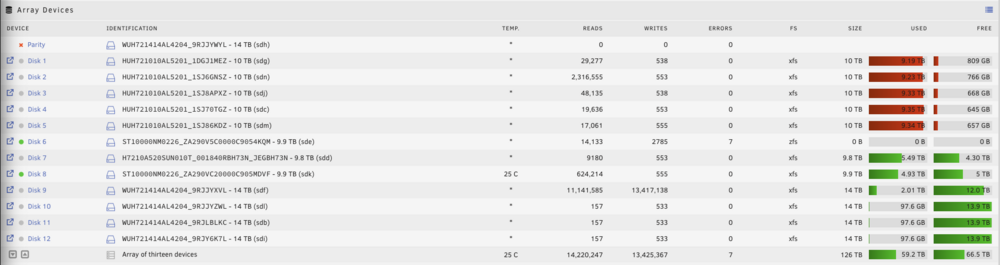
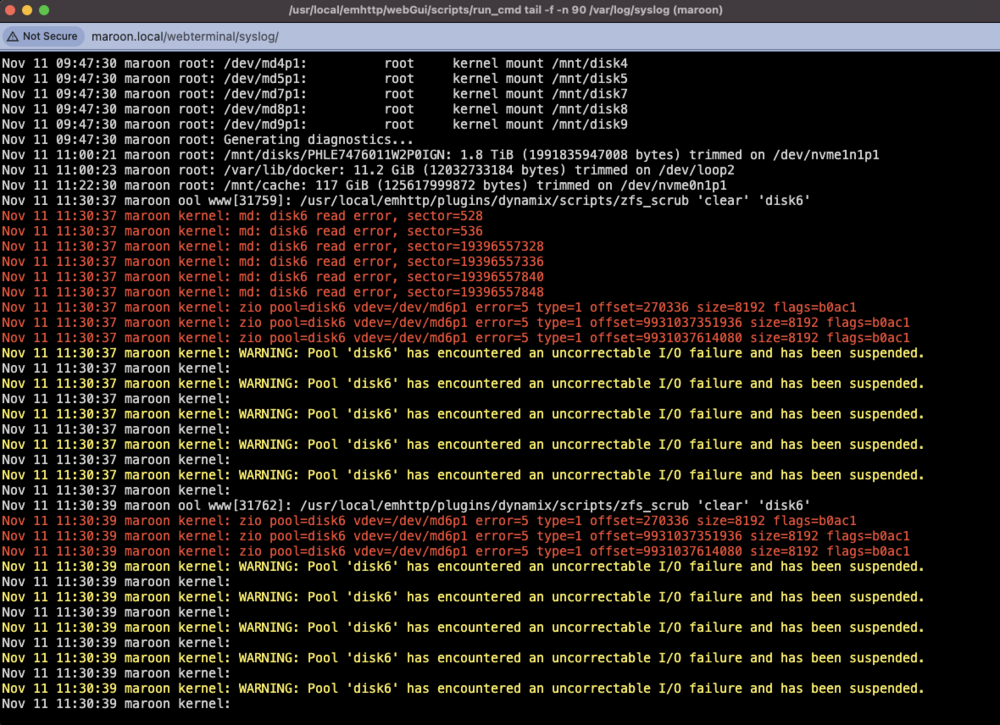
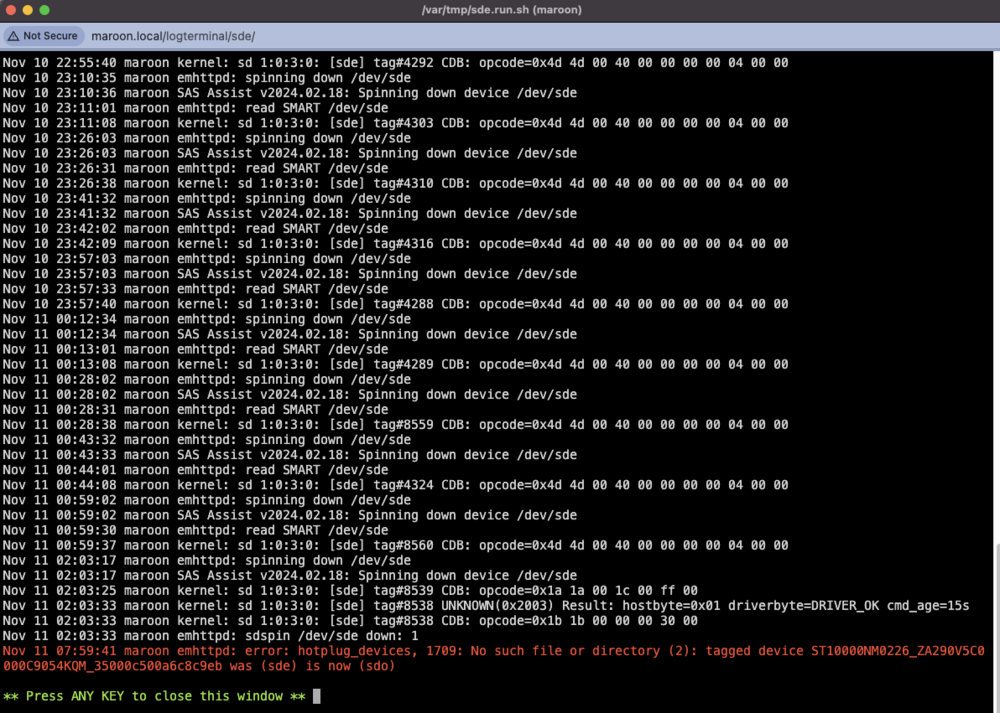
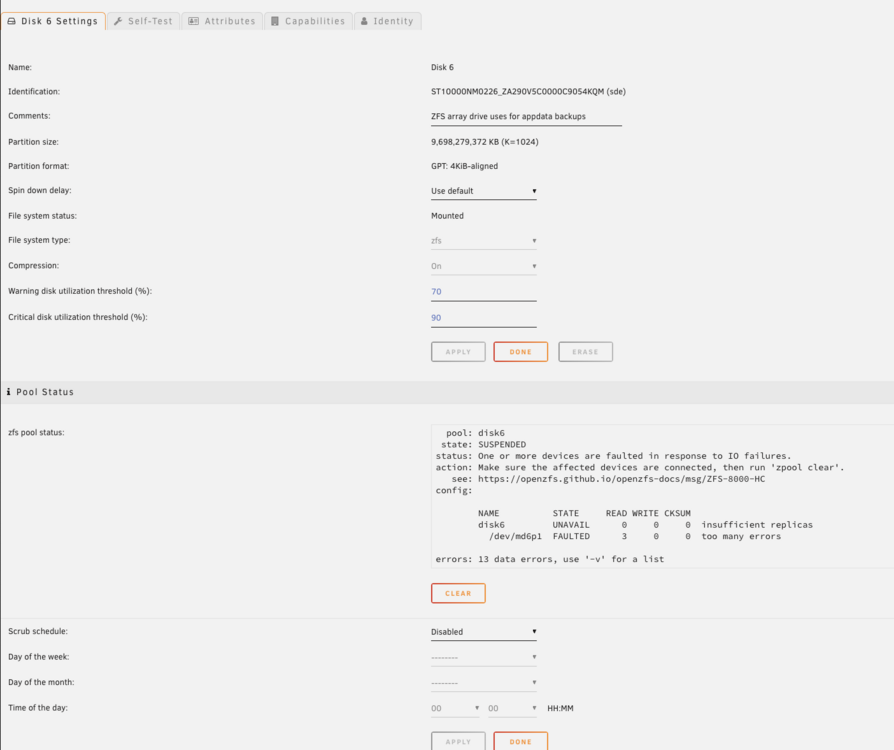
-
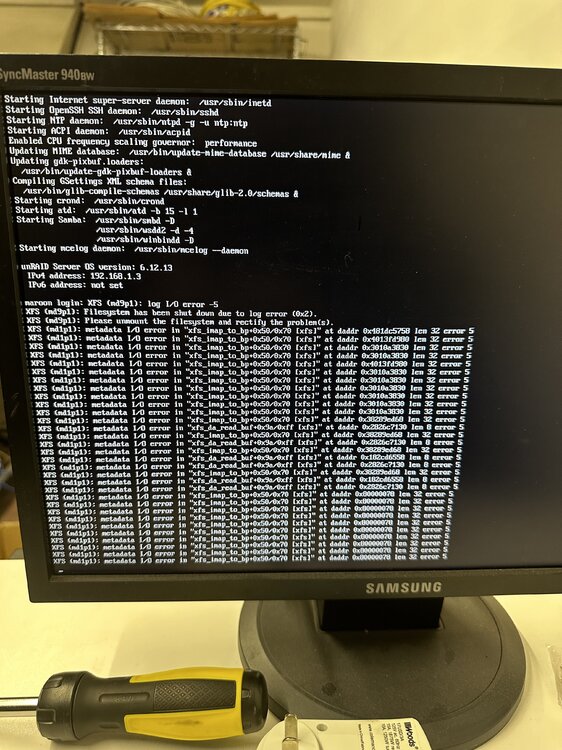
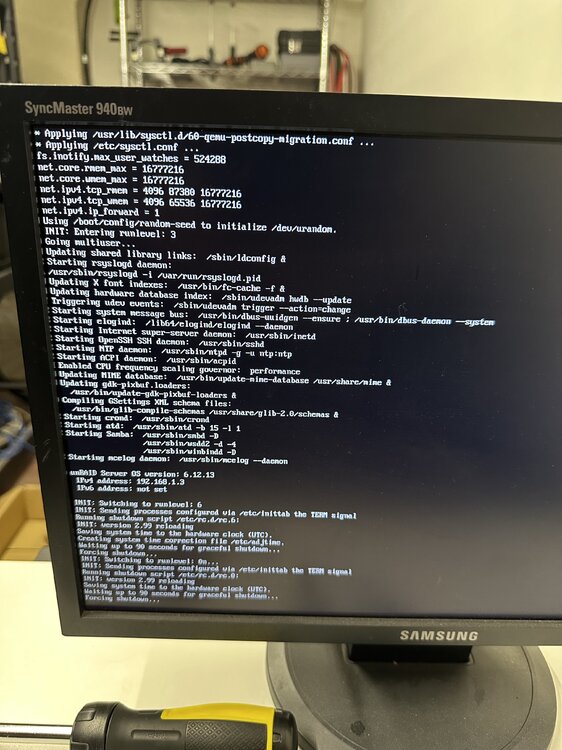
Ok, I have done a few things since the last post: I got a dedicated fan on the heatsink of the HBA (blowing toward it) I still got errors so I replaced the HBA with another one (from ebay) still getting errors so now I think its either the SAS cables or my backplane or my HDDs? another symptom I am experiencing is that the server has locked up at 100% cpu waiting on iowait process. also shutdown doesn’t seem to work, it gets stuck at “Forcing shutdown…” I attached my latest diagnostics incase the errors are different but otherwise I will replace the cables then if needed backplane maroon-diagnostics-20240929-0959.zip
-
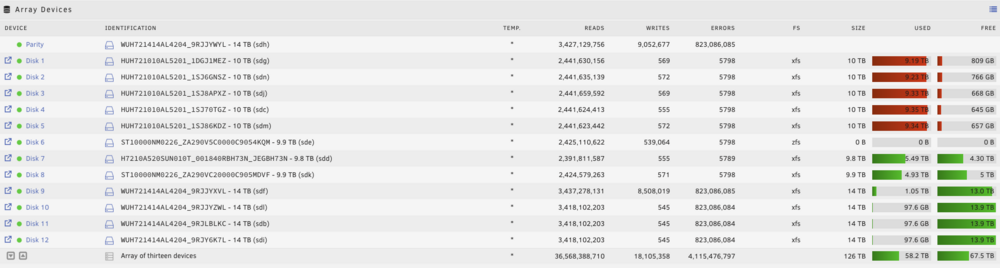
Ok it happened again, here are some screenshots and attached are my diagnostics. Thank you for the help. Hoping this isn't really bad maroon-diagnostics-20240908-2145.zip
-
Thanks for responding. I have enabled the syslog server and will post again when it happens. Appreciate the help!
-
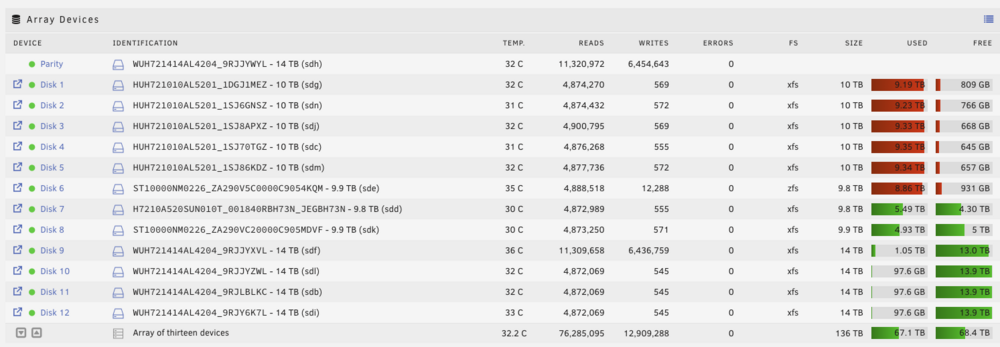
In the last week or so I started getting unraid notifications that multiple disks (around 4-6) were having read errors. When I logged into the dashboard I saw on the Main tab that those disks had error counts in the table. I have 13 disks (1 parity) and the errors ranged from 1 to ~1200. When I restart the server all errors goto zero and I get an unraid notif saying all read errors have returned to normal. Since that first time it has happened about 2-3 more times with the most recent time the system locked up and I had to hold the power button to restart it. I didn't take a screenshot or pic of the dashboard when it had all the errors. I will do that next time Some info about my setup: - All HDDs are SAS and were bought used from eBay in batches (so HDDs brands/models cluster together) - All HDDs go through my Supermicro backplane (I believe it is bpn-sas3-826el1) - Backplane is connected to mobo via HBA card (Adaptec asr-7805) I find it highly unlikely that HDDs across multiple vendors and generations would start failing at the exact same moment so I wonder if it is the backplane or HBA card. Does that seem reasonable? How can I verify this? Attached my diagnostics zip, the monitor log before I had to force shutdown, and my hardware setup described above. Thanks in advance! maroon-diagnostics-20240905-0943.zip



-
Not sure if this is the correct place to ask but I am having some issues with spinning down my disks (all SAS). Unraid version: 6.12.13 (servername = maroon) Spin Down SAS Drive Plugin version: 2024.02.18 While manually spinning down my disks (Unraid GUI -> Main -> Click green circle per disk) some disks spin down fine (sdg, sdn) but I always (100% repro) get this error on Disk 6 (sde). It takes a while (~15-20 seconds) and then the log shows the kernel errors. It also spins up all the previously spundown drives and does SMART checks -- is this normal/expected? What are those kernel errors? The only thing I can think of is that Disk 6 is my ZFS pool backup for appconfig -- is that preventing it from spinning down? here is the syslog: Aug 26 09:33:22 maroon emhttpd: spinning down /dev/sdg Aug 26 09:33:22 maroon SAS Assist v2024.02.18: Spinning down device /dev/sdg Aug 26 09:33:41 maroon emhttpd: spinning down /dev/sdn Aug 26 09:33:41 maroon SAS Assist v2024.02.18: Spinning down device /dev/sdn Aug 26 09:33:51 maroon emhttpd: spinning down /dev/sde Aug 26 09:33:51 maroon SAS Assist v2024.02.18: Spinning down device /dev/sde Aug 26 09:34:08 maroon emhttpd: read SMART /dev/sde Aug 26 09:34:12 maroon kernel: sd 1:1:14:0: [sde] tag#764 UNKNOWN(0x2003) Result: hostbyte=0x05 driverbyte=DRIVER_OK cmd_age=10s Aug 26 09:34:12 maroon kernel: sd 1:1:14:0: [sde] tag#764 CDB: opcode=0x28 28 00 37 bc e6 9a 00 00 05 00 Aug 26 09:34:12 maroon kernel: I/O error, dev sde, sector 7481013456 op 0x0:(READ) flags 0x0 phys_seg 5 prio class 2 Aug 26 09:34:12 maroon kernel: md: disk6 read error, sector=7481013392 Aug 26 09:34:12 maroon kernel: md: disk6 read error, sector=7481013400 Aug 26 09:34:12 maroon kernel: md: disk6 read error, sector=7481013408 Aug 26 09:34:12 maroon kernel: md: disk6 read error, sector=7481013416 Aug 26 09:34:12 maroon kernel: md: disk6 read error, sector=7481013424 Aug 26 09:34:12 maroon kernel: sd 1:1:14:0: [sde] tag#763 UNKNOWN(0x2003) Result: hostbyte=0x05 driverbyte=DRIVER_OK cmd_age=10s Aug 26 09:34:12 maroon kernel: sd 1:1:14:0: [sde] tag#763 CDB: opcode=0x28 28 00 37 bc e6 90 00 00 05 00 Aug 26 09:34:12 maroon kernel: I/O error, dev sde, sector 7481013376 op 0x0:(READ) flags 0x0 phys_seg 5 prio class 2 Aug 26 09:34:12 maroon kernel: md: disk6 read error, sector=7481013312 Aug 26 09:34:12 maroon kernel: md: disk6 read error, sector=7481013320 Aug 26 09:34:12 maroon kernel: md: disk6 read error, sector=7481013328 Aug 26 09:34:12 maroon kernel: md: disk6 read error, sector=7481013336 Aug 26 09:34:12 maroon kernel: md: disk6 read error, sector=7481013344 Aug 26 09:34:12 maroon kernel: sd 1:1:14:0: [sde] tag#762 UNKNOWN(0x2003) Result: hostbyte=0x05 driverbyte=DRIVER_OK cmd_age=10s Aug 26 09:34:12 maroon kernel: sd 1:1:14:0: [sde] tag#762 CDB: opcode=0x28 28 00 37 bc e6 89 00 00 05 00 Aug 26 09:34:12 maroon kernel: I/O error, dev sde, sector 7481013320 op 0x0:(READ) flags 0x0 phys_seg 5 prio class 2 Aug 26 09:34:12 maroon kernel: md: disk6 read error, sector=7481013256 Aug 26 09:34:12 maroon kernel: md: disk6 read error, sector=7481013264 Aug 26 09:34:12 maroon kernel: md: disk6 read error, sector=7481013272 Aug 26 09:34:12 maroon kernel: md: disk6 read error, sector=7481013280 Aug 26 09:34:12 maroon kernel: md: disk6 read error, sector=7481013288 Aug 26 09:34:12 maroon kernel: sd 1:1:14:0: [sde] tag#761 UNKNOWN(0x2003) Result: hostbyte=0x05 driverbyte=DRIVER_OK cmd_age=10s Aug 26 09:34:12 maroon kernel: sd 1:1:14:0: [sde] tag#761 CDB: opcode=0x28 28 00 37 bc e6 6c 00 00 05 00 Aug 26 09:34:12 maroon kernel: I/O error, dev sde, sector 7481013088 op 0x0:(READ) flags 0x0 phys_seg 5 prio class 2 Aug 26 09:34:12 maroon kernel: md: disk6 read error, sector=7481013024 Aug 26 09:34:12 maroon kernel: md: disk6 read error, sector=7481013032 Aug 26 09:34:12 maroon kernel: md: disk6 read error, sector=7481013040 Aug 26 09:34:12 maroon kernel: md: disk6 read error, sector=7481013048 Aug 26 09:34:12 maroon kernel: md: disk6 read error, sector=7481013056 Aug 26 09:34:23 maroon emhttpd: read SMART /dev/sdg Aug 26 09:34:23 maroon emhttpd: read SMART /dev/sdn
-
Hi, I was not able to access my unraid webUI (6.9.2) due to the SSL Certificate Update. I was able to follow the instructions and regain access to my server UI. I was a bit frustrated because I have not been able to previously upgrade the OS (see here). I figured that latest is 6.11.5 and maybe in the last 3 patches since 6.11.2 there have been some improvements and fixes around upgrading. I backed everything up (flashdrive and parts of my appdata) and tried the upgrade path. TLDR: same result as last time. Booting is frozen at: which is the same as before. I figured I would post here hoping someone could help me before I start the rollback process (revert to 6.9.2). Appreciate the help. One other thing to note, during boot after the upgrade I saw this which is not normal during boot for me: Although it did pass after about 1 min.
-
Hi all, I decided to upgrade Unraid OS today from 6.9 to 6.11.2. The download and install went fine then asking me to reboot. The reboot has been stuck for ~30 mins at the image below. I have not force restarted or pulled the plug yet. Thoughts?
-
Following up here. I uninstalled rclone and did a full shutdown (not reboot). One thing to note is that I stopped the array before clicking shutdown to make sure containers had been stopped. That shutdown/restart worked flawlessly, first time in over a year! I will keep playing with it this weekend and try to see if I can reproduce it: - reboot vs shutdown - stopping array before shutdown vs not - having rclone installed vs not
-
Here are my diagnostics. Thank you! unraid-diagnostics-20211016-1416.zip
-
Like every morning for the past week. Before I take the dog out I turn on the server and cross my fingers. This morning the server successfully booted up! No changes since last time. Is there something I can enable or do to add extra logging or verbose debug statements during future boot ups? This is still a serious problem. Thanks
-
Hi all, TLDR: Unraid indefinitely hangs or is stuck during the boot process at this command: I have been plagued with this issue for a while now but finally it boiled over since I cannot successfully boot unraid anymore. It has been days without being able to use my server and I am very frustrated. If you search for this it really does seem like there are many people with the same issue. @limetech is this a larger problem worth investigating? Here is a list of related posts I have found: https://forums.unraid.net/topic/50963-solved-unraid-refuses-to-boot/ https://forums.unraid.net/topic/72755-hang-on-reboot-fine-on-cold-boot/ https://forums.unraid.net/topic/114019-unraid-startup-wont-complete/ https://forums.unraid.net/topic/59506-server-wont-boot-stuck-at-syslogd/ https://forums.unraid.net/topic/88212-boot-stops-in-syslog-on-second-boot-asus-rs720/ Here are a list of things I tried: Put your flash drive in your PC and let it checkdisk (chkdsk [drive] /f /r /x) Plugging flash into PC, make backup of your 'config' folder. Then reformat the usb flash - volume label UNRAID - then copy over release from zip file. Click 'make_bootable' as administrator (don't forget this step), then drag your 'config' file backup to the flash I am pretty desperate at this point and would love any help. Thank you!
-
+1 I would love to figure this out. What more can we do?















