

Dmtalon
-
Posts
160 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by Dmtalon
-
Build is a few years old now, has been rock solid, until recently. I have had 2 VM's (windows 7 and windows10) and a Plex docker. The windows 7 VM runs my "house audio" via a pass-through audio PCI card, and also runs uTorrent. First sign of issues, is extracted RAR files either being empty (extraction failed), or corruption (or what I thought was corruption). I had 5 data drives, 1 parity, cache and an app drive. Cache drive is a fairly old 1TB WD Black, app drive is a samsung 128GB SSD. VMs/Dockers live on the app drive, and downloads would download to the VM, then copy to a directory (through cache). I assumed my cache drive was dying even though no red ball, and decided to move into 2018 and dump the separate cache/app drive and put in a 500GB SSD as my cache/app drive. That all went fairly smooth, however one of my VM's didn't want to come up. I messed with it for a while, but eventually plugged the old app drive into another pc (booted upbuntu usb live) and tried copying over the vm again. I did this and boom, VM came up. Fast Forward, uTorrent (or some process) was still having issues. I decided since I had a nice new big cache/app drive to install ruTorrent docker, Got that up and running and added some existing recent torrents to it pointing to there already downloaded location. It was here I discovered that uTorrent didnt' seem to be completing the downloads. ruTorrent was finding them at like 96-97% complete and then finishing them. So, I assumed that this was just some kind of uTorrent issue, and moved on with life using ruTorrent docker vs uTorrent on my VM. It was this same time I discovered pi-hole and pi-hole docker so I installed and got that working/setup too. SO I'm feeling all good and things are working etc.. Yesterday my VMs/Dockers crashed, and i had all kinds of I/O errors in my logs. So I SSH in and try to look in /mnt/cache but no go, i/o errors. OK, lets shut down the array go into maintenance mode and do some checks. BUT, I can't get /mnt/cache unmounted. I let it sit, I tried lsof/fuser etc.. but the kernel was the only process that seemed to have it locked, so I pulled the plug and rebooted. Everything came up but Parity wanted to run. I stopped it, stopped the array, and put it in maintenance mode. I wanted to do some checks on the cache drive. It seemed to find some errors it couldn't fix (and google didn't help me a whole lot honestly) "Metadata CRC error detected at xfs_bmbt block" Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... - scan filesystem freespace and inode maps... - found root inode chunk Phase 3 - for each AG... - scan and clear agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 Metadata CRC error detected at xfs_bmbt block 0xec53a00/0x1000 Metadata CRC error detected at xfs_bmbt block 0xec53a00/0x1000 btree block 1/451648 is suspect, error -74 - agno = 1 - agno = 2 - agno = 3 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 2 - agno = 0 - agno = 3 - agno = 1 Phase 5 - rebuild AG headers and trees... - reset superblock... Phase 6 - check inode connectivity... - resetting contents of realtime bitmap and summary inodes - traversing filesystem ... - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify and correct link counts... done After trying to run xfs_repair w/o -n and ultimately with -L those errors stay, so I restarted the array and let it run a parity check through the night. It found 2.4 million errors. and when I just took the array offline (stopped, restarted in maintenance mode to get the errors above) it told me I had an unclean shutdown and needed another parity check. I'm attaching some screen shots, and a diagnostics report from just now after the parity. Before I keep digging in this hole I'm in, I'm hoping someone can maybe help me climb out. Thanks, sorry for the rambling. nas1-diagnostics-20180401-1056.zip
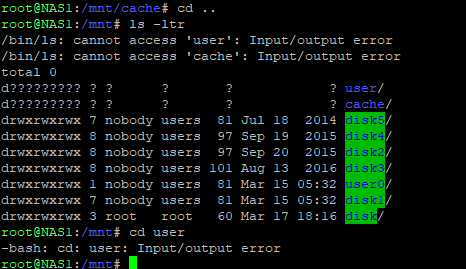

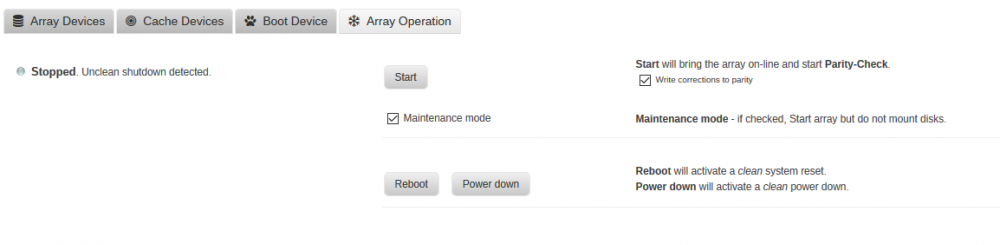
-
Thanks @trurl... Sorry for the trouble. My initial 'issue' matched the existing post which put me in the other thread and I was just trying to find out if my docker was the issue
-
I might have a couple things going on... <sigh> I have what looks like a dorked up cache drive (xfs) root@NAS1:~# xfs_repair -v /dev/sdi1 Phase 1 - find and verify superblock... - block cache size set to 2277800 entries Phase 2 - using internal log - zero log... zero_log: head block 182199 tail block 181661 ERROR: The filesystem has valuable metadata changes in a log which needs to be replayed. Mount the filesystem to replay the log, and unmount it before re-running xfs_repair. If you are unable to mount the filesystem, then use the -L option to destroy the log and attempt a repair. Note that destroying the log may cause corruption -- please attempt a mount of the filesystem before doing this. And since this was a cache drive I didn't care enough to troubleshoot a LOT. and tried to just clear the logs. root@NAS1:~# xfs_repair -L /dev/sdi1 Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... ALERT: The filesystem has valuable metadata changes in a log which is being destroyed because the -L option was used. Invalid block length (0x0) for buffer Log inconsistent (didn't find previous header) empty log check failed fatal error -- failed to clear log I guess next I'm just going to attempt to reformat it.
-
Sorry, I'm not the OP, so I kind of hijacked his post probably a party foul
-
how do you know loop2 is docker image? (is this just default?) I'm getting these errors for loop3 Mar 24 16:27:16 NAS1 kernel: BTRFS error (device loop3): bdev /dev/loop3 errs: wr 3, rd 0, flush 0, corrupt 0, gen 0 Mar 24 16:27:16 NAS1 kernel: loop: Write error at byte offset 91684864, length 4096. Mar 24 16:27:16 NAS1 kernel: print_req_error: I/O error, dev loop3, sector 179072 Mar 24 16:27:16 NAS1 kernel: BTRFS error (device loop3): bdev /dev/loop3 errs: wr 4, rd 0, flush 0, corrupt 0, gen 0 Mar 24 16:27:16 NAS1 kernel: BTRFS: error (device loop3) in btrfs_commit_transaction:2257: errno=-5 IO failure (Error while writing out transaction) Mar 24 16:27:16 NAS1 kernel: BTRFS info (device loop3): forced readonly Mar 24 16:27:16 NAS1 kernel: BTRFS warning (device loop3): Skipping commit of aborted transaction. Mar 24 16:27:16 NAS1 kernel: BTRFS: error (device loop3) in cleanup_transaction:1877: errno=-5 IO failure Mar 24 16:27:16 NAS1 kernel: BTRFS info (device loop3): delayed_refs has NO entry
-

unRAID Server Release 6.2 Stable Release Available
Dmtalon replied to limetech's topic in Announcements
Finally upgrading from 6.1.9 to 6.3.3 so I went through the procedures for my VM's however neither fs0 or fs1 work. After posting this, after reading/searching more I learned I could type exit here, but this takes me to the BIOS but doesn't allow me to boot into windows. This was a working windows 7 install. Here is the VM page. -
Convert from PhAze's Plex Plugin to needo's Plex docker
Dmtalon replied to Dmtalon's topic in Docker Containers
If you switch, your old image will still be there, it'll just start a new one. I don't remember having to redo any settings (are they saved on plex cloud?) I am a plex pass user though so not sure if that is why. I no longer use needo's, I use this one: https://registry.hub.docker.com/u/linuxserver/plex/ -
Convert from PhAze's Plex Plugin to needo's Plex docker
Dmtalon replied to Dmtalon's topic in Docker Containers
Good to know, thanks -
Convert from PhAze's Plex Plugin to needo's Plex docker
Dmtalon replied to Dmtalon's topic in Docker Containers
Just FYI, now a days, I use this plex docker: https://registry.hub.docker.com/u/linuxserver/plex/ And you log in once its up/running vs in the configuration. Notice the highlighted part to pull the plexpass version. I also force my transcode directory onto my ssd app drive.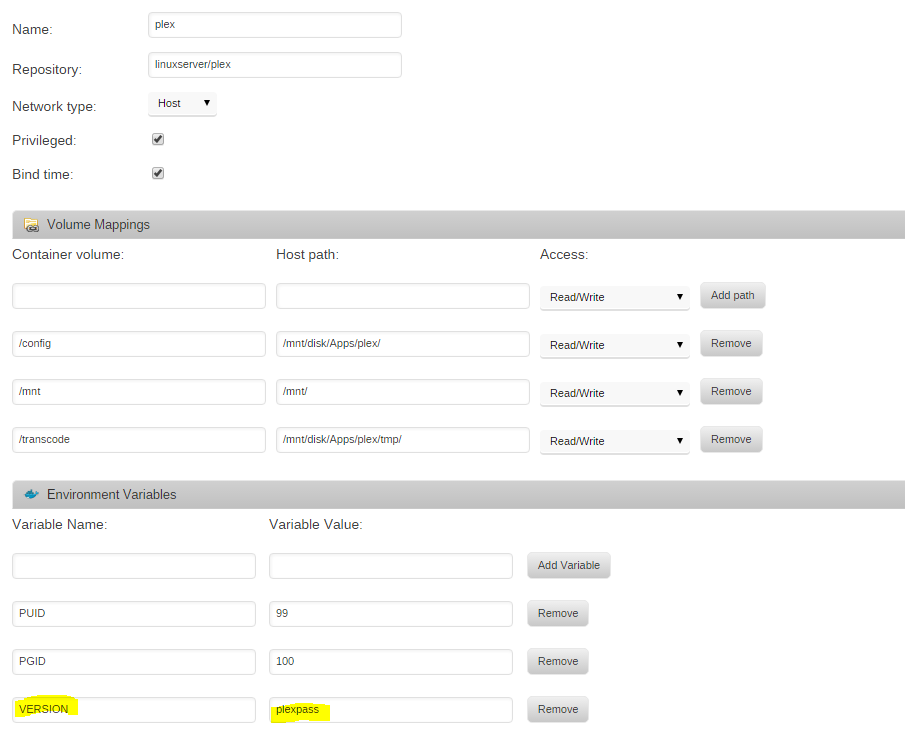
-
Help Add More PCI Device Pass Through to unRAID 6
Dmtalon replied to jonp's topic in VM Engine (KVM)
07:00.0 PCI bridge: Creative Labs [sB X-Fi Xtreme Audio] CA0110-IBG PCIe to PCI Bridge 08:00.0 Audio device: Creative Labs [sB X-Fi Xtreme Audio] CA0110-IBG 08 is what I'm passing through to my windows 7 VM. This is (I believe) a custom version of the SB X-Fi Xtreme card. It is a PCI card, and is for my whole house audio (Casatunes). Its a 6 channel audio card with an aux in and IR out. /usr/local/sbin/vfio-bind 0000:08:00.0
-
unRAID Server Release 6.0-beta15-x86_64 Available
Dmtalon replied to limetech's topic in Announcements
Not sure how common this will be but I had to copy my .xml's back to /etc/libvirt/qemu after the upgrade. I was a couple versions behind on 14b but the upgrade didn't move my .xml's I had them backed up (which I'd suggest you do first). -
unRAID Server Release 6.0-beta15-x86_64 Available
Dmtalon replied to limetech's topic in Announcements
Do I need to do anything else after copying my .xml files back to /etc/libvirt/qemu? Will that solution survive a reboot? I copied three OS.xml files and one network/vlan.xml file. -
unRAID Server Release 6.0-beta15-x86_64 Available
Dmtalon replied to limetech's topic in Announcements
Go to the settings tab. Click VM Manager. Turn "enable" to yes if not already set, then click apply. If already set, try setting to "no", then apply, then yes, then apply. See if this resolves your issue (this is essentially restarting libvirt if not already started). Also, did you clear your browser cache? No Joy. Edit 1 I do not see my .xml's in /etc/libvirt root@NAS1:/etc/libvirt# ls -ltr total 42 drwxr-xr-x 3 root root 1024 Sep 27 2014 storage/ drwxr-xr-x 3 root root 1024 Sep 27 2014 qemu/ drwxr-xr-x 2 root root 1024 Sep 27 2014 nwfilter/ -rw-r--r-- 1 root root 13800 Sep 27 2014 libvirtd.conf -rw-r--r-- 1 root root 518 Sep 27 2014 libvirt.conf -rw-r--r-- 1 root root 2134 Sep 27 2014 virtlockd.conf -rw-r--r-- 1 root root 18355 Sep 27 2014 qemu.conf -rw-r--r-- 1 root root 2169 Sep 27 2014 qemu-lockd.conf Did I just miss some step? Should they be there? I have backup's should I put them there under qemu? Edit 2: I copied my .xml's for the domain's and the lan (had a vlan.xml moved it into networks) restarted and my vm's show up now. Started my windows 7 and it seems to be up/running ok.
-
unRAID Server Release 6.0-beta15-x86_64 Available
Dmtalon replied to limetech's topic in Announcements
Am I supposed to have to do anything for the new VM manager to see my existing KVM VM's? I just get an empty VM's tab. I read through this tread and didn't see where I should have to recreate them here. Did something go wrong? I removed the libvirt/kvm plugin's then used the webgui to update from b14 to b15 -
Thanks dmacias, Finally got a chance to do this. I shut down docker/KVM/libvirt in settings, then manually unmounted /etc/libvirt. Made a copy of virtman.img, then ran e2fsck against it. Only thing of note, is I have the following file: boot/config/plugins/virtman/virtman.img not the one you listed, but it was what was mounted in /etc/libvirt. I also wasn't 100% sure how to answer all the questions. I did not create a lost&found but answered y to everything else. it is showing there are still errors... Not sure what, if anything I should do at this point. I brought everything back up and all seems ok. I havent' seen any syslog entries yet about the errors. root@NAS1:/boot/config/plugins/virtman# e2fsck virtman.img e2fsck 1.42.8 (20-Jun-2013) virtman.img contains a file system with errors, check forced. Pass 1: Checking inodes, blocks, and sizes Pass 2: Checking directory structure Entry 'Windows7.xml' in /deleteme (31) has deleted/unused inode 54. Clear<y>? yes Pass 3: Checking directory connectivity /lost+found not found. Create<y>? no Pass 4: Checking reference counts Pass 5: Checking group summary information Block bitmap differences: -(628--632) Fix<y>? yes Free blocks count wrong for group #0 (1319, counted=1324). Fix<y>? yes Free blocks count wrong (1319, counted=1324). Fix<y>? yes Inode bitmap differences: -54 Fix<y>? yes Free inodes count wrong for group #0 (130, counted=131). Fix<y>? yes Free inodes count wrong (130, counted=131). Fix<y>? yes virtman.img: ***** FILE SYSTEM WAS MODIFIED ***** virtman.img: ********** WARNING: Filesystem still has errors ********** virtman.img: 53/184 files (0.0% non-contiguous), 116/1440 blocks
-
Thanks, Do you know how to fsck it? can I run e2fsck against that img? I assume I need to bring down libvirt to do that?
-
I'm getting a notification that I need to do an fsck on loop0 which based on the file system I assume is on my SNAP drive and has something to do with my docker image. Mar 12 14:38:46 NAS1 kernel: EXT4-fs (loop0): error count since last fsck: 54 Mar 12 14:38:46 NAS1 kernel: EXT4-fs (loop0): initial error at time 1410555868: ext4_lookup:1437: inode 31 Mar 12 14:38:46 NAS1 kernel: EXT4-fs (loop0): last error at time 1410804989: ext4_lookup:1437: inode 31 Does anyone know how I can run an fsck on this drive/file ? Edit: Looking more into the GUI, I see that my docker seems to be loop1 Label: none uuid: 3f2db28e-8d29-4793-b017-6019498a79ba Total devices 1 FS bytes used 2.17GiB devid 1 size 4.00GiB used 3.12GiB path /dev/loop1 Btrfs v3.18.2 so, I'm not sure how to find this.
-
unRAID Server Release 6.0-beta14b-x86_64 Available
Dmtalon replied to limetech's topic in Announcements
is this safe to do without backing up settings etc? I have KVM (web virt manager, livbirt installed and using a windows VM) with snap supporting my single docker (plex server). I'd prefer to not have to 'redo' my setup if possible. -
unRAID Server Release 6.0-beta14b-x86_64 Available
Dmtalon replied to limetech's topic in Announcements
You have an older version of SNAP. SNAP is updated from the webpage. Now that the webpage is blank, you can't update SNAP that way. You need to uninstall the SNAP plugin and re-install it to get the latest version. Some changes were made in the later betas that affected the webpage of SNAP. I did end up trying that last night. The uninstall *seems* to get stuck, watching the logs it isn't doing anything, if I refresh the screen the plugging is gone. Then I reinstalled using your snap v6 page URL. But it still shows blank. I'm guessing I'm not getting it fully uninstalled or something. Any ideas? Thanks for the reply! -
unRAID Server Release 6.0-beta14b-x86_64 Available
Dmtalon replied to limetech's topic in Announcements
Just updated from 6b12 to b14, and my snap page is blank. My update steps were to remove apcups plugin, and then I manually updated copying the new files to flash, and rebooted. Thanks -
Kernel: ata5.00: exception Emask error after latest reboot.
Dmtalon replied to Dmtalon's topic in General Support
Ok, thanks... I'll give that a try before getting too worked up about it :-) -
Anyone know what this might be? It appears that it worked it out and is up and running. I did not have any symptoms in the gui, I was just looking in the logs for the spindown command being issues, and saw this: Jan 22 20:53:34 NAS1 kernel: ata5.00: exception Emask 0x10 SAct 0x30000 SErr 0x400000 action 0x6 frozen Jan 22 20:53:34 NAS1 kernel: ata5.00: irq_stat 0x08000000, interface fatal error Jan 22 20:53:34 NAS1 kernel: ata5: SError: { Handshk } Jan 22 20:53:34 NAS1 kernel: ata5.00: failed command: WRITE FPDMA QUEUED Jan 22 20:53:34 NAS1 kernel: ata5.00: cmd 61/08:80:00:4d:30/00:00:03:00:00/40 tag 16 ncq 4096 out Jan 22 20:53:34 NAS1 kernel: res 40/00:88:60:bc:34/00:00:03:00:00/40 Emask 0x10 (ATA bus error) Jan 22 20:53:34 NAS1 kernel: ata5.00: status: { DRDY } Jan 22 20:53:34 NAS1 kernel: ata5.00: failed command: WRITE FPDMA QUEUED Jan 22 20:53:34 NAS1 kernel: ata5.00: cmd 61/08:88:60:bc:34/00:00:03:00:00/40 tag 17 ncq 4096 out Jan 22 20:53:34 NAS1 kernel: res 40/00:88:60:bc:34/00:00:03:00:00/40 Emask 0x10 (ATA bus error) Jan 22 20:53:34 NAS1 kernel: ata5.00: status: { DRDY } Jan 22 20:53:34 NAS1 kernel: ata5: hard resetting link Jan 22 20:53:34 NAS1 kernel: ata5: SATA link up 6.0 Gbps (SStatus 133 SControl 300) Jan 22 20:53:34 NAS1 kernel: ata5.00: configured for UDMA/133 Jan 22 20:53:34 NAS1 kernel: ata5: EH complete
-
Convert from PhAze's Plex Plugin to needo's Plex docker
Dmtalon replied to Dmtalon's topic in Docker Containers
Sorry, I modified my post, it wasn't the Application Support part, it was the capital L in library. I modified the first post to include the highlighted line. -
Convert from PhAze's Plex Plugin to needo's Plex docker
Dmtalon replied to Dmtalon's topic in Docker Containers
I do have that in the original post, the "Application Support" is highlighted in red. Glad you got it working. -
Convert from PhAze's Plex Plugin to needo's Plex docker
Dmtalon replied to Dmtalon's topic in Docker Containers
Glad it helped! believe me, I was just as confused :-)






