




Womabre
Members
-
Joined
-
Last visited
Everything posted by Womabre
-
I created a bug report here:
-
Summary: After updating to Unraid 7.2, containers such as Nextcloud intermittently lose write access — uploads via web UI or sync clients fail. The issue appears to affect other containers as well and seems related to ZFS mounts becoming unavailable. Workaround: Execute zfs mount -a manually or via a scheduled user script (e.g. hourly cron) to restore write functionality. The issue is currently being discussed here:
-
Thanks! I just updated to 7.2.0 and my Nextcloud AIO container was down after a backup this night. And this was the fix! Before running the zfs mount -a command I got an error when running touch /mnt/user/nextcloud/test.txt
-
This has been fixed in 6.12.10 Version 6.12.10 2024-04-03 - Release notes
-
Thanks! Will keep an eye on that thread.
-
Just downgraded to 6.12.8. All drives immediately show up again.
-
When I switch the missing drives to a slot where the drive shows up the drive is available but the switched drive is now missing. Seems to be an issue with the config, driver, cable or hardware. Both slots are connected to my HBA but the other drives connected to it show up without an issue. I reseated all cable, without effect. Can someone maybe see something weird in my diagnostics? Attached are my diagnostics. breedveld-diagnostics-20240328-1426.zip
-
For me it was the IPMI plugin. Took around 30s on every page load to get the temp, fan speed etc. Remove it, everything is lightning fast again.
-
I've also been having this issue for year now. Running 6.12.5 (upgrading to 6.12.6 after writing this, the update triggered me to search for a solution again). Attached are my diagnostics. breedveld-diagnostics-20231202-1236.zip
-
Also got this issue for years now. The custom threshold is just ignored... I get notifications at 80% which is ridiculous for 10TB drives. The settings in dynamix.cfg are: warning="96" critical="97" unraid v6.12.4
-
Are you using the Unassigned Devices plugin to mount the NAS to your unraid system?
-
Yes, no problem. Just create two, or more, instances of the docker. One for each account.
-
I have everything running smoothly again. Thanks everyone for all the help, it was very useful! 🙂 Thanks! Set up that script to run hourly.
-
Just restarted the server again. Everything was looking OK. So I started recreating my docker.img After a few minutes the log was getting spammed with errors. And the btrfs file system switched to read only. breedveld-diagnostics-20210708-1540.zip
-
Just checked all the BIOS settings. No overclocking is enabled anywhere. I think the frequency you see in memtest is the CPU. Has been running quite a while now, no errors. I'm thinking maybe my SSD is dying...
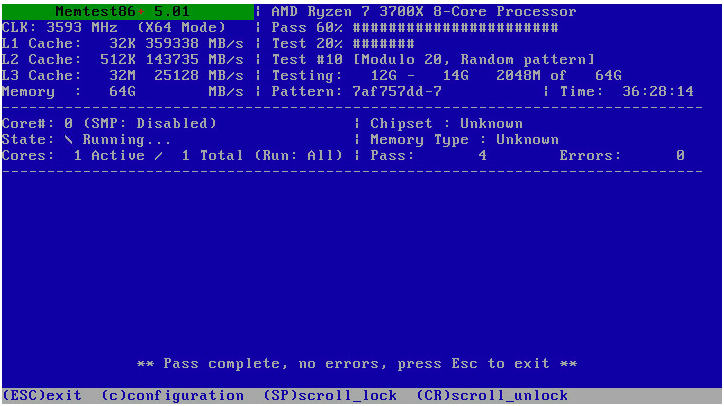
-
The btrfs restore was successful, and after that a repair managed to restore the drives and being able to mount them. The last 14 hours I've been running a memtest. Everything seems fine so far. Will keep it running until it at least hits the 24h mark.
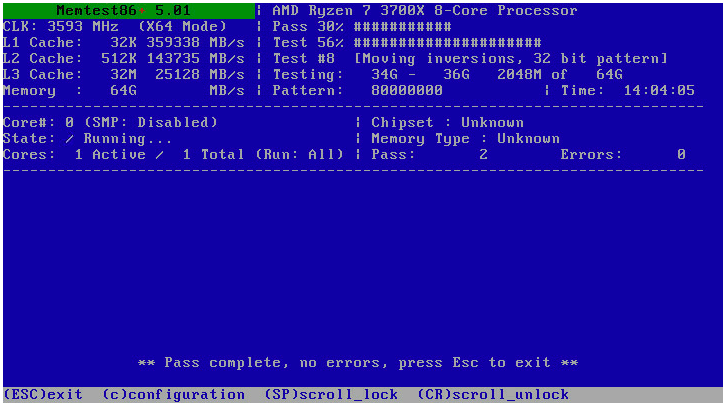
-
Just ran the following commands I found here blkid btrfs fi show 21bd917c-3bff-4b16-8083-3cc37e866bc0 Maybe create a new config with the drives? root@Breedveld:~# blkid /dev/loop0: TYPE="squashfs" /dev/loop1: TYPE="squashfs" /dev/sda1: LABEL_FATBOOT="UNRAID" LABEL="UNRAID" UUID="272C-EBE2" BLOCK_SIZE="512" TYPE="vfat" /dev/sdb1: UUID="9535ccd7-a35f-4ae7-9b81-1df827d3ff81" TYPE="crypto_LUKS" PARTUUID="43b637af-1d86-4885-9238-6deded95ffc5" /dev/sdc1: UUID="1b5ff8ec-dc95-4366-ae24-2aab29dbc19d" TYPE="crypto_LUKS" PARTUUID="dd35aaa3-1958-4f9f-95ae-dc2590c42fe9" /dev/sdf1: UUID="48a9fda0-8361-4d1e-a7f9-8797feb7d36d" TYPE="crypto_LUKS" PARTUUID="13e10a64-25b3-422f-b4a1-a404e7b9fd4f" /dev/sdh1: UUID="6cf73bfd-fbca-434d-bc43-6882086e40b3" TYPE="crypto_LUKS" /dev/sdg1: UUID="d45aaeb9-8d4c-434c-a338-05fda58744b8" TYPE="crypto_LUKS" PTTYPE="atari" PARTUUID="1d83dbb0-8657-4d63-8459-ac8a1cf9073b" /dev/sdi1: UUID="a4f92928-fd20-4a35-b000-a5a2911ef80d" TYPE="crypto_LUKS" /dev/md1: UUID="48a9fda0-8361-4d1e-a7f9-8797feb7d36d" TYPE="crypto_LUKS" /dev/md2: UUID="d45aaeb9-8d4c-434c-a338-05fda58744b8" TYPE="crypto_LUKS" PTTYPE="atari" /dev/md3: UUID="9535ccd7-a35f-4ae7-9b81-1df827d3ff81" TYPE="crypto_LUKS" /dev/md4: UUID="1b5ff8ec-dc95-4366-ae24-2aab29dbc19d" TYPE="crypto_LUKS" /dev/mapper/md1: UUID="410acbe9-5e05-4cbb-a6cc-7468a1594335" BLOCK_SIZE="512" TYPE="xfs" /dev/mapper/md2: UUID="0edff695-7439-4bf4-afab-714828a33068" BLOCK_SIZE="512" TYPE="xfs" /dev/mapper/md3: UUID="999f938a-e3d4-406e-adee-29ffc84a11a5" BLOCK_SIZE="512" TYPE="xfs" /dev/mapper/md4: UUID="7220097f-6376-4713-9962-48d664aed857" BLOCK_SIZE="512" TYPE="xfs" /dev/mapper/sdh1: UUID="21bd917c-3bff-4b16-8083-3cc37e866bc0" UUID_SUB="c9064e5a-ba80-448a-9440-19cd64187136" BLOCK_SIZE="4096" TYPE="btrfs" /dev/mapper/sdi1: UUID="21bd917c-3bff-4b16-8083-3cc37e866bc0" UUID_SUB="fbcdd800-48d6-4c13-a209-a3ed25321280" BLOCK_SIZE="4096" TYPE="btrfs" /dev/sdd1: PARTUUID="1646878a-800f-4ba7-a893-713aef59900d" /dev/sde1: PARTUUID="8095e8cc-a2ca-4ff0-9d3f-a22f526a1f51" root@Breedveld:~# btrfs fi show 21bd917c-3bff-4b16-8083-3cc37e866bc0 Label: none uuid: 21bd917c-3bff-4b16-8083-3cc37e866bc0 Total devices 2 FS bytes used 773.91GiB devid 1 size 931.50GiB used 866.03GiB path /dev/mapper/sdh1 devid 2 size 953.85GiB used 866.03GiB path /dev/mapper/sdi1
-
Sorry. Still had in Maintenance Mode. Bellow the diagnostics after a normal start. I also noticed that I now get this message: Unmountable disk present: Cache • Samsung_SSD_860_QVO_1TB_S4CZNF0M744639K (sdh) Cache 2 • ADATA_SU800_2I4820059015 (sdi) breedveld-diagnostics-20210705-2323.zip
-
Hi trurl. Here are the diagnostics. breedveld-diagnostics-20210705-2313.zip
-
This weekend my log got spammed with errors about the loop2 device. After some reading I decided to recreate the docker.img Halfway reinstalling al my containers I got errors and did some further digging and ran a BTRFS check on my cache pool. I also ran an extended SMART test without any errors. Can someone assist me in how to proceed further? [1/7] checking root items [2/7] checking extents extent item 395649875968 has multiple extent items ref mismatch on [395649875968 872448] extent item 1, found 2 backref disk bytenr does not match extent record, bytenr=395649875968, ref bytenr=395650023424 backref bytes do not match extent backref, bytenr=395649875968, ref bytes=872448, backref bytes=7913472 backpointer mismatch on [395649875968 872448] extent item 395656859648 has multiple extent items ref mismatch on [395656859648 2101248] extent item 1, found 2 backref disk bytenr does not match extent record, bytenr=395656859648, ref bytenr=395657936896 backref bytes do not match extent backref, bytenr=395656859648, ref bytes=2101248, backref bytes=17575936 backpointer mismatch on [395656859648 2101248] extent item 1702685908992 has multiple extent items ref mismatch on [1702685908992 475136] extent item 1, found 3 backref disk bytenr does not match extent record, bytenr=1702685908992, ref bytenr=1702686289920 backref bytes do not match extent backref, bytenr=1702685908992, ref bytes=475136, backref bytes=49152 backref disk bytenr does not match extent record, bytenr=1702685908992, ref bytenr=1702686339072 backref bytes do not match extent backref, bytenr=1702685908992, ref bytes=475136, backref bytes=16384 backpointer mismatch on [1702685908992 475136] extent item 1703009673216 has multiple extent items ref mismatch on [1703009673216 421888] extent item 1, found 2 backref disk bytenr does not match extent record, bytenr=1703009673216, ref bytenr=1703010017280 backref bytes do not match extent backref, bytenr=1703009673216, ref bytes=421888, backref bytes=90112 backpointer mismatch on [1703009673216 421888] ERROR: errors found in extent allocation tree or chunk allocation [3/7] checking free space cache [4/7] checking fs roots root 5 inode 6963467 errors 1000, some csum missing root 5 inode 25937011 errors 800, odd csum item ERROR: errors found in fs roots Opening filesystem to check... Checking filesystem on /dev/mapper/sdh1 UUID: 21bd917c-3bff-4b16-8083-3cc37e866bc0 found 830958428160 bytes used, error(s) found total csum bytes: 485124368 total tree bytes: 1190313984 total fs tree bytes: 431308800 total extent tree bytes: 155336704 btree space waste bytes: 215474656 file data blocks allocated: 1717250732032 referenced 826999590912
-
Hi Tom, I'm not the provider of this container. I only created the template file for use with unRAID. Try checking the logs if you can find something that might cause the container to become unhealthy.
-
The "AppData Config Path" and the "Data" path need to be mapped to a folder outside the container. For example, the data path is where all the photos are downloaded. You want to save these somewhere on you array. So this should be something like "/mnt/user/SHARE/iCloudPics" The container is like a small OS running inside it's own bubble. So the folder "/config" in the container redirects to the "/mnt/user/SHARE/iCloudPics" folder on your array. This is called a bind mount.
-
I have exactly the same problem. But also Yourls and Filerun suffer from slow loading speeds, not as bad as Nextcloud though. But Plex, Radarr etc. is lighting fast. Al run through the same SWAG container. Tried everything with Nextcloud. With Redis, without. Tinkered with a lot of SWAG settings. No effect. Removed all but the bare minimum apps from Nextcloud. No effect. Installed a new instance of Nextcloud as a test, lightning fast...
-
I've just updated the containers template to work with keyring authentications by default. This way it is a lot easier to configure. Can you try to create the container again using the new template? At minimum you need to provide you Apple ID and configure the "Data" path. Also make sure to place the ".mounted" file in this folder. For info check: https://hub.docker.com/r/boredazfcuk/icloudpd/
-
What does the log say?



