





interwebtech
Members
-
Joined
-
Last visited
-
FYI working now. Was able to "thank" a post.
-
Attempts to upvote/like etc result in generic error message "Sorry, there was a problem reacting to this content."
-
I followed your contributions to unRaid over the years and have probably every one of your add-ons. You will be missed But every once in a while we will still spot your name in the code there somewhere. RIP
-
I joined when current version was 4 something. 5.X wasn't even being discussed yet. I migrated from an external RAID box running RAID5 (5 discs?) connected directly to my HTPC running MyMovies on Windows, Always on. Always spinning. Regular space heater. I did not realize at the time what it was costing me on the electric bill (more on that). I was looking at the Drobo line, mostly because it supported different disk sizes in the raid pool but passed on it as too expensive (thank deity as they've gone out of business). I stumbled across unRAID and decided to give it a try (I hadn't used Linux since college, strictly Windows). Started with a cheap tower with inexpensive AMD and a handful of 2TB & 4TB discs. It took me a week or more (I tend to block out traumatic memories lol) to transfer all the DVD & BRD rips to the new system. unRAID worked as advertised and I dove in headfirst in setting up Plex and other useful stuff. This was the time of plug-ins and avoiding incompatibilities. Almost immediately I noticed my electric bill dropping by HALF! Spinning down disks and only spinning up what was needed for playback was a revolution in cost savings! Fast forward to today and I am still loving unRAID! My server has changed drastically (see sig) but even with the fire breathing hardware I enjoy now, power costs are still reasonable. Docker changed the whole landscape for me. I don't run any VMs as my application requirements have changed now that I'm retired. No need for additional servers and such. Recently converted all my ReiserFS disks to XFS (beat the deadline - trauma lol). When I first set some of those up (before the eventual size upgrades over the years), it was the only choice for file system IIRC. Anyway it doesn't seem like its been 15+ years as this project is still fresh and exciting. New stuff coming along all the time. Its been a pleasure to be involved and to watch it grow from a one man shop to the vibrant enterprise it is now. Congratulations on 20 years! the OG system The current rig


-
Looks like you need a minimum of 850W to have a bit of headroom.
-
This might help you answer that question: https://www.newegg.com/tools/power-supply-calculator
-
Oh snap just realized there is already custom for header text. Sorry for the bother.
-
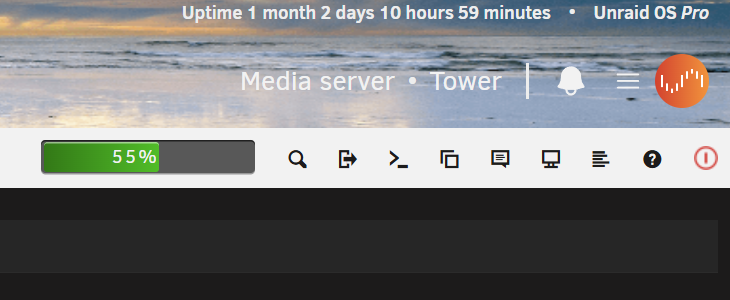
I use a custom banner which is black (See pic) and Black scheme sets that text as black. I reset banner to default and can now see that that section of text is indeed Black when set to Black scheme. Looks great for default banner. Is there a workaround (class?) to change just that section of text?
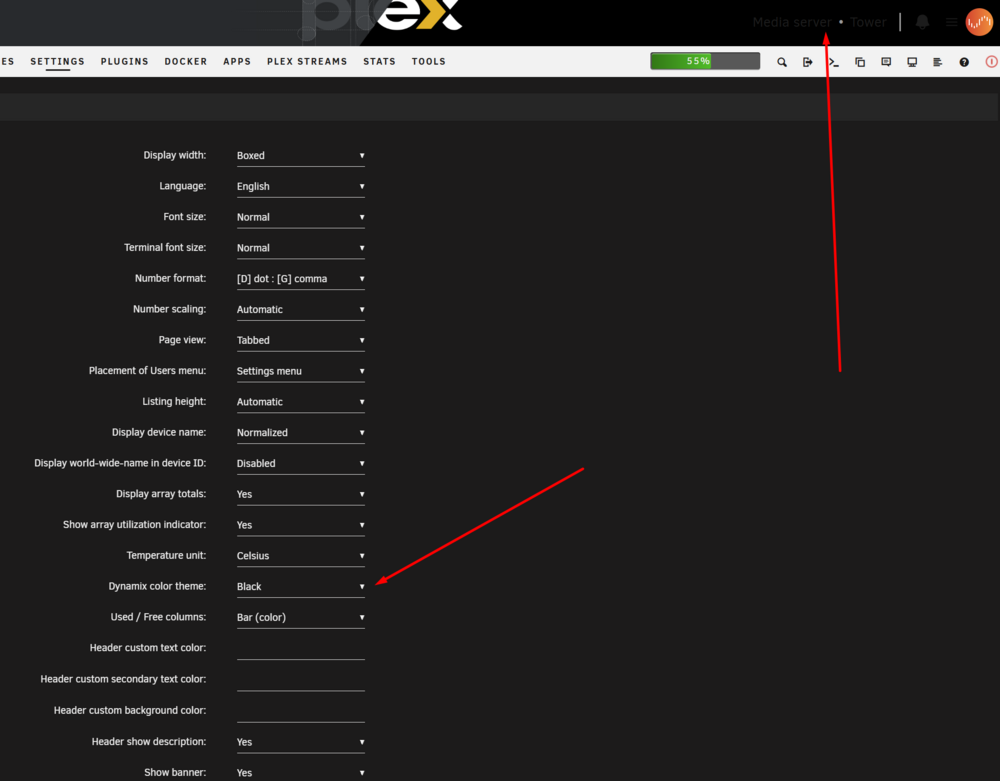
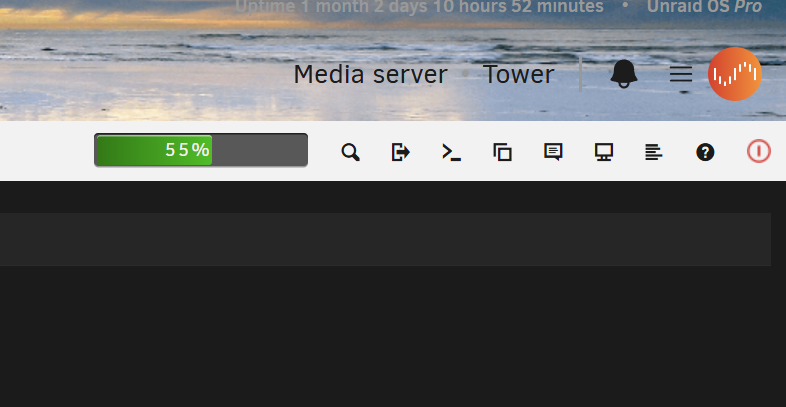
-
When color scheme is set to Black in Display Settings, the font color in the header is set to Black when it needs to be White (or at least lighter) to be visible on black background. Verified by switching to White or Azure color scheme the font colors are appropriate for the background and visible. Images attached for clarificatrion.
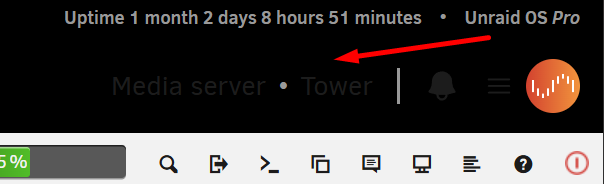
-
Correct me if I am wrong but the act of zeroing the drive will eliminate all folders (overwrite w/zeros) anyway. Same with converting and formatting.
-
Update: finally converted 11 ReiserFS disks to XFS. Been putting that off for years unRaid 7.x Pro 2x 22TB parity 290TB data array SanDisk 64GB Cruzer Fit USB Flash Drive (SDCZ33) StarTech.com 12U Adjustable Depth Open Frame 4 Post Server Rack 2x StarTech 1U Adjustable Mounting Depth Vented Rack Mount Shelf CyberPower OR1500LCDRM1U 1U Rackmount UPS System NORCO 4U Rack Mount 24 x Bays Server Rack mount RPC-4224 EVGA Supernova 850 G3, 80 Plus Gold 850W Modular Power Supply Gigabyte W480 VISION W Motherboard Intel® Core™ i9-10850K 10-Core Comet Lake 3.6GHz LGA-1200 CPU (passmark 23344) Noctua NH-L9x65, Premium Low-Profile CPU Cooler (65mm, Brown) 4x 16GB G.Skill Trident Z RGB Memory Module DDR4 4000 MHz (64GB) 4x Samsung 970 EVO 1TB - NVMe PCIe M.2 2280 SSD (MZ-V7E1T0BW) (2 mobo, 2 PCI-E slots) RAID1 2TB total 2x QNINE M.2 NVME SSD to PCIe adapter 2x M.2 Heatsink NVME Cooler w/active fans LSI Logic LSI00244 SAS 9201-16i 16-Port 6Gb/s SAS/SATA Controller Card 4x 10Gtek Internal Mini SAS SFF-8087 Cable, 0.5 Meter 1x NORCO Computer Parallel (reverse breakout) Cable (C-SFF8087-4S) 2x Gigabit network adapters bonded to a single interface

-
This plug-in is a life saver. I am on the last 12TB disk of the original 11 ReiserFS formatted drives (18 total). Been thinking about updating for years but always put it off as a massive hassle I would rather avoid. Finally jumped in when I read that 2025 is the year ReiserFS is being dropped from the kernel. Took me a minute (close to 2.5 days per drive) to get it done but now its almost over and I am ready to put this behind me. If you haven't already, send Juan a donation to acknowledge how useful his add-ons are especially this one at this time ;). Happy holidays Juan!
-
I am unable to stop the transfer process using 2024.12.23a. The red Stop button fades but the process continues. PS: Okay I refreshed the unbalance page and tried again and this time it stopped as should.
-
Came to report same error
-
Sounds like you just need a new drive to replace the fail drive. It's not a matter of sacrificing any data as it is emulated and slapping a new drive in and allowing it to rebuild the drive will bring everything back to normal. The new drive can't be smaller than the one you're replacing or larger than your parity.










