




KptnKMan
Members
-
Joined
-
Last visited
Everything posted by KptnKMan
-
There are a few in this thread that have the same array/shutdown issue, but you've got a point that it may not be enough to pull it immediately. There is another thread on this forum about the startup message, and I cannot fathom how many people might be experiencing "can't shutdown" issues. I know I searched through the forum enough times and trawled through logs to find my own conclusion. Still, I still think it's important to highlight this link, so that others might find it. I disagree that this doesn't warrant further discussion, it definitely does, but certainly less about the developer abandoning his project. I've been trying to investigate the codebase to find why the issues are encountered, already posted some of my own findings, and I would encourage anyone with deeper knowledge of unraid to chime in on this as maybe it can be fixed and submitted as a pull-request to the repo.
-
I get what you're saying, but I'm not getting into a discussion about what "feels" right. I'm stating the facts. Yeah, I can see why you and others would leave this plugin be, but its still out there, released in the Community Apps selection. It's clearly been released and is in the Community Apps selection, which is the recommended way to find and install plugins and extensions, right alongside official releases of plugins and the like. It's MOST DEFINITELY RELEASED, which has nothing to do with its Alpha/Beta status. Sorry, but that is the truth. I know personally that I'm not RELYING any of my data on this. My gripe has clearly been that it makes unraid unstable (In my case, MY unraid server), and not just for me, which is unacceptable and I want others to know the danger this plugin poses. If it doesn't work or is buggy within its domain... fine, no worries... but if it puts into danger your entire server and data by destabilising the whole system, causing startup and shutdown errors (And things inbetween) then this SHOULD be at the least pulled or fixed. That is not "relying on this to secure their data", its much more dangerous. What makes it worse is that it silently a problem, so just by installing it, an unraid system or array could be rendered unusable. Anyway I'm no super-dev myself but I've developed things in the past, and I understand that if you release something then you should be expected to support it, which is why I release anything rarely and support anything that I "release" online through ANY channel. Nobody is perfect, but this is the marked difference between those who try to be good developers (Emphasis on "try"), and those that don't. Take the high road and judge my unpopular opinion if you like, but it is what it is and I'm not trying to be rude or sugar-coat anything.
-
I understand what you're saying, but there is a marked difference between ALPHA and BETA software. This is the former, and I would argue it's PRE-ALPHA with the issues encountered by numerous people. I'm just saying it's inappropriately labelled, which is dangerous and playing with peoples data integrity. I know it's their own risk they take by installing it, but the BETA label is severely misleading and lacking. Absolutely, total agreement. I also stated that very point. However, for this plugin to move beyond its debatable BETA status, the dev needs to speak up and work with those willing to test. So far, I don't hear anything, and the GitHub account for this is quiet, to the point that the last dev commit was nearly 4 months ago. On the basis of that alone, it's hard to recommend this plugin for use at all.
-
Agreed that a lot of people don't read up before posting. I'm not trying to be rude. I also tried to post my findings to help the dev, and others, and my followup was to hopefully get something out of the dev. So far silence. Personally, I was a little annoyed about how this server-breaking issue has not been even acknowledged by the plugin developer. I battled with this for some weeks and had to hard-reset my server a few times, which is NOT IDEAL for anyone (Especially with cache-pool BTRFS corruption issues, which I've also personally experienced). I get that this is a "free" plugin and all but I wouldn't recommend anyone use this plugin as its marked as BETA, but is really very very unstable and seemingly untested, especially for a crucial solution such as VM Backups. It's doing some weird stuff that I'm unsure about, and should be marked as pre-alpha/alpha. Lastly, I know that they don't wish to step on people's toes, but a basic (Not advanced) solution to this kind of thing (Config/VM/Docker backup) really needs to be rolled into unraid core.
-
1. I understood the BETA nature of this plugin before using it (Please refer to the 1st line in the 1st post of this thread). 2. I have already been using the userscript version, since I found the plugin to be unstable. 3. It is important to report these issues so that: - others can know the unstable issues before using it, SO THAT THEY DON'T LOSE DATA FROM AN UNSTABLE SYSTEM. - The developer can work with those who want to find and test a fix. @Stupifier Not to be rude, but your response helps nobody. I have submitted my findings and report of what I've seen so far in this thread, so that the dev can help the people encountering strange unrelated errors and system instability. If you have something constructive to add to the discussion, please do so.
-
Something messed up is definitely going on. It would be great if the dev of this plugin would have ANYTHING to say please?
-
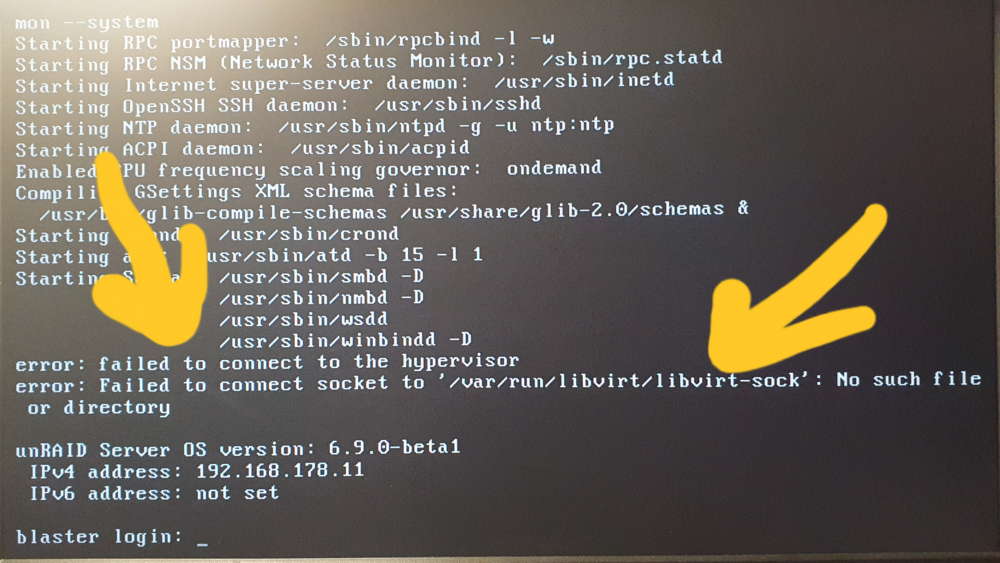
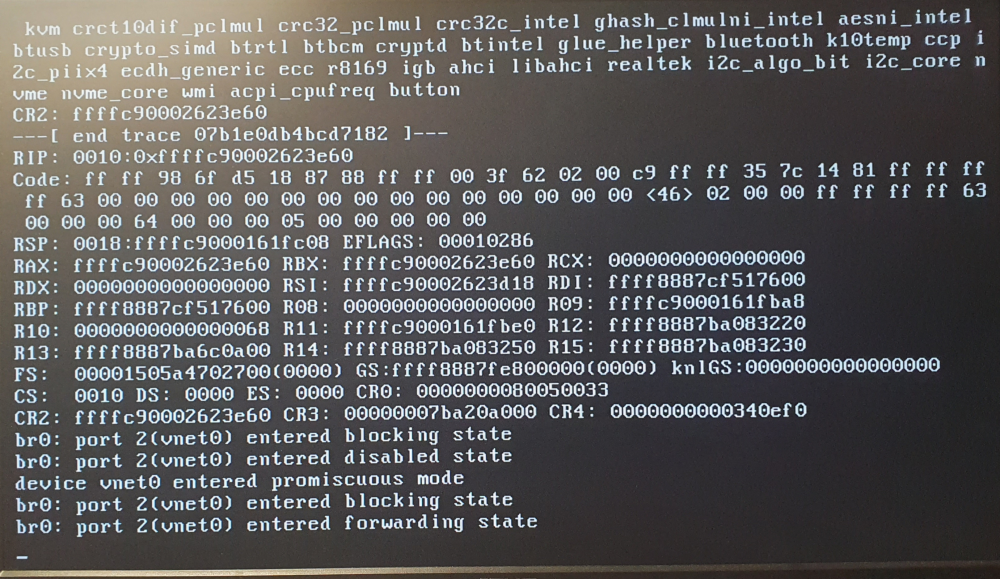
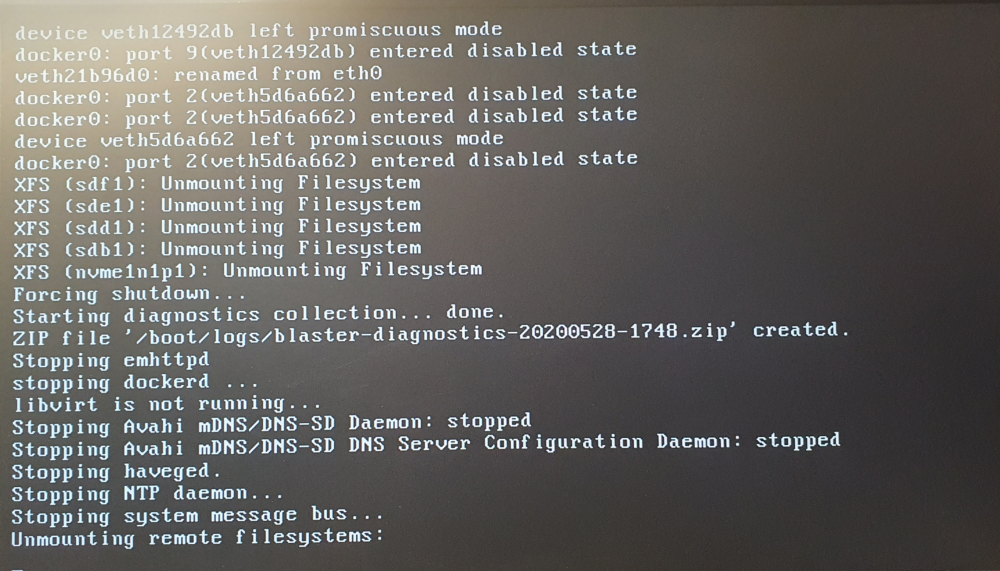
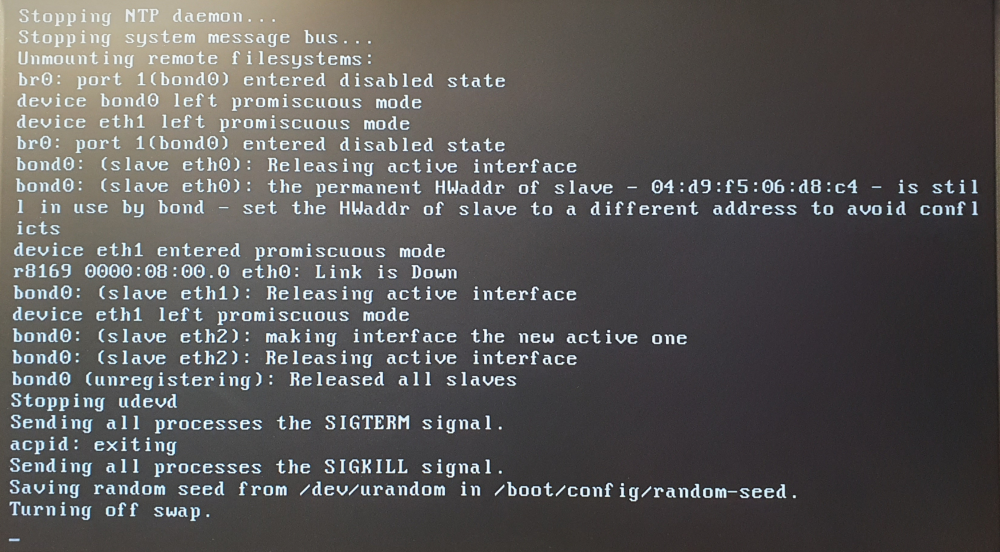
I've been using this plugin to backup my VMs for a couple weeks now, but unfortunately I've found that this this is the cause of my server being unable to shutdown. My unRAID was unable to shutdown and would freeze forcing me to hard kill the system, causing a parity check every time. I do not want to do this for an otherwise stable system. Rolled back from 6.9.0-b1 to 6.8.3 didn't solve it. Running in safe mode showed that everything worked, but I couldn't start my VMs due to the Unassigned devices plugin. Uninstalling the VM Backup plugin solved the issue, and removed the error at startup. Something in the VM Backup plugin is breaking the Hypervisor and messing with my bonded network connection. From what I can tell, first there's the "error: failed to connect to the hypervisor" error: Failed to connect socket to '/varrun/libvirt/libvirt-sock' : No such file or directory" After this, I seemed to be getting some kind of trace error when shutting down: More shutdown: And finally stalls here forever (I've waited a day for this, and it didn't shutdown😞 Uninstalling the VM Backup Plugin fixed the issue, and I can now shutdown/reboot without stalling, crashing and parity check. The errors have gone also. It is a real shame because I use this plugin daily (Nightly). Does anyone know why this is happening? I'd like to use this plugin.
-
Hi there, Hoping that maybe you could make an icon for my original Coolermaster Stacker 810 that I'm still rocking after all this time. 🙂 Thanks!

-
Still trying, the result of my `sensors-detect` root@blaster:~# sensors-detect # sensors-detect version 3.6.0 # Board: ASUSTeK COMPUTER INC. TUF GAMING X570-PLUS (WI-FI) # Kernel: 5.5.8-Unraid x86_64 # Processor: AMD Ryzen 5 3600 6-Core Processor (23/113/0) This program will help you determine which kernel modules you need to load to use lm_sensors most effectively. It is generally safe and recommended to accept the default answers to all questions, unless you know what you're doing. Some south bridges, CPUs or memory controllers contain embedded sensors. Do you want to scan for them? This is totally safe. (YES/no): YES Silicon Integrated Systems SIS5595... No VIA VT82C686 Integrated Sensors... No VIA VT8231 Integrated Sensors... No AMD K8 thermal sensors... No AMD Family 10h thermal sensors... No AMD Family 11h thermal sensors... No AMD Family 12h and 14h thermal sensors... No AMD Family 15h thermal sensors... No AMD Family 16h thermal sensors... No AMD Family 17h thermal sensors... Success! (driver `k10temp') AMD Family 15h power sensors... No AMD Family 16h power sensors... No Hygon Family 18h thermal sensors... No Intel digital thermal sensor... No Intel AMB FB-DIMM thermal sensor... No Intel 5500/5520/X58 thermal sensor... No VIA C7 thermal sensor... No VIA Nano thermal sensor... No Some Super I/O chips contain embedded sensors. We have to write to standard I/O ports to probe them. This is usually safe. Do you want to scan for Super I/O sensors? (YES/no): YES Probing for Super-I/O at 0x2e/0x2f Trying family `National Semiconductor/ITE'... No Trying family `SMSC'... No Trying family `VIA/Winbond/Nuvoton/Fintek'... Yes Found `Nuvoton NCT6798D Super IO Sensors' Success! (address 0x290, driver `nct6775') Probing for Super-I/O at 0x4e/0x4f Trying family `National Semiconductor/ITE'... No Trying family `SMSC'... No Trying family `VIA/Winbond/Nuvoton/Fintek'... No Trying family `ITE'... No Some systems (mainly servers) implement IPMI, a set of common interfaces through which system health data may be retrieved, amongst other things. We first try to get the information from SMBIOS. If we don't find it there, we have to read from arbitrary I/O ports to probe for such interfaces. This is normally safe. Do you want to scan for IPMI interfaces? (YES/no): YES Probing for `IPMI BMC KCS' at 0xca0... No Probing for `IPMI BMC SMIC' at 0xca8... No Some hardware monitoring chips are accessible through the ISA I/O ports. We have to write to arbitrary I/O ports to probe them. This is usually safe though. Yes, you do have ISA I/O ports even if you do not have any ISA slots! Do you want to scan the ISA I/O ports? (yes/NO): YES Probing for `National Semiconductor LM78' at 0x290... No Probing for `National Semiconductor LM79' at 0x290... No Probing for `Winbond W83781D' at 0x290... No Probing for `Winbond W83782D' at 0x290... No Lastly, we can probe the I2C/SMBus adapters for connected hardware monitoring devices. This is the most risky part, and while it works reasonably well on most systems, it has been reported to cause trouble on some systems. Do you want to probe the I2C/SMBus adapters now? (YES/no): YES Using driver `i2c-piix4' for device 0000:00:14.0: AMD KERNCZ SMBus Module i2c-dev loaded successfully. Next adapter: SMBus PIIX4 adapter port 0 at 0b00 (i2c-0) Do you want to scan it? (YES/no/selectively): YES Client found at address 0x1a Probing for `Analog Devices ADM1021'... No Probing for `Analog Devices ADM1021A/ADM1023'... No Probing for `Maxim MAX1617'... No Probing for `Maxim MAX1617A'... No Probing for `Maxim MAX1668'... No Probing for `Maxim MAX1805'... No Probing for `Maxim MAX1989'... No Probing for `Maxim MAX6655/MAX6656'... No Probing for `TI THMC10'... No Probing for `National Semiconductor LM84'... No Probing for `Genesys Logic GL523SM'... No Probing for `Onsemi MC1066'... No Probing for `Maxim MAX1618'... No Probing for `Maxim MAX1619'... No Probing for `National Semiconductor LM82/LM83'... No Probing for `Maxim MAX6654'... No Probing for `Maxim MAX6690'... No Probing for `Maxim MAX6680/MAX6681'... No Probing for `Maxim MAX6695/MAX6696'... No Probing for `Texas Instruments TMP400'... No Probing for `Texas Instruments AMC6821'... No Probing for `ST STTS424'... No Probing for `ST STTS424E'... No Probing for `ST STTS2002'... No Probing for `ST STTS3000'... No Probing for `NXP SE97/SE97B'... No Probing for `NXP SE98'... No Probing for `Analog Devices ADT7408'... No Probing for `IDT TS3000/TSE2002'... No Probing for `IDT TSE2004'... No Probing for `IDT TS3001'... No Probing for `Maxim MAX6604'... No Probing for `Microchip MCP9804'... No Probing for `Microchip MCP9808'... No Probing for `Microchip MCP98242'... No Probing for `Microchip MCP98243'... No Probing for `Microchip MCP98244'... Success! (confidence 5, driver `jc42') Probing for `Microchip MCP9843'... No Probing for `ON CAT6095/CAT34TS02'... No Probing for `ON CAT34TS02C'... No Probing for `ON CAT34TS04'... No Probing for `Atmel AT30TS00'... No Probing for `Giantec GT30TS00'... No Client found at address 0x1b Probing for `ST STTS424'... No Probing for `ST STTS424E'... No Probing for `ST STTS2002'... No Probing for `ST STTS3000'... No Probing for `NXP SE97/SE97B'... No Probing for `NXP SE98'... No Probing for `Analog Devices ADT7408'... No Probing for `IDT TS3000/TSE2002'... No Probing for `IDT TSE2004'... No Probing for `IDT TS3001'... No Probing for `Maxim MAX6604'... No Probing for `Microchip MCP9804'... No Probing for `Microchip MCP9808'... No Probing for `Microchip MCP98242'... No Probing for `Microchip MCP98243'... No Probing for `Microchip MCP98244'... Success! (confidence 5, driver `jc42') Probing for `Microchip MCP9843'... No Probing for `ON CAT6095/CAT34TS02'... No Probing for `ON CAT34TS02C'... No Probing for `ON CAT34TS04'... No Probing for `Atmel AT30TS00'... No Probing for `Giantec GT30TS00'... No Client found at address 0x52 Probing for `Analog Devices ADM1033'... No Probing for `Analog Devices ADM1034'... No Probing for `SPD EEPROM'... Yes (confidence 8, not a hardware monitoring chip) Client found at address 0x53 Probing for `Analog Devices ADM1033'... No Probing for `Analog Devices ADM1034'... No Probing for `SPD EEPROM'... Yes (confidence 8, not a hardware monitoring chip) Next adapter: SMBus PIIX4 adapter port 2 at 0b00 (i2c-1) Do you want to scan it? (YES/no/selectively): YES Now follows a summary of the probes I have just done. Just press ENTER to continue: Driver `k10temp': * Chip `AMD Family 17h thermal sensors' (confidence: 9) Driver `jc42': * Bus `SMBus PIIX4 adapter port 0 at 0b00' Busdriver `i2c_piix4', I2C address 0x1a Chip `Microchip MCP98244' (confidence: 5) * Bus `SMBus PIIX4 adapter port 0 at 0b00' Busdriver `i2c_piix4', I2C address 0x1b Chip `Microchip MCP98244' (confidence: 5) Driver `nct6775': * ISA bus, address 0x290 Chip `Nuvoton NCT6798D Super IO Sensors' (confidence: 9) Do you want to generate /etc/sysconfig/lm_sensors? (yes/NO): yes Copy prog/init/lm_sensors.init to /etc/init.d/lm_sensors for initialization at boot time. You should now start the lm_sensors service to load the required kernel modules. Unloading i2c-dev... OK
-
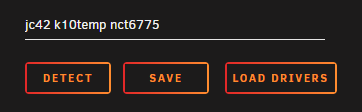
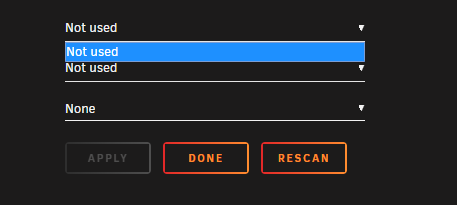
Hi all, I've been trying for a while to get temp monitor working with My Ryzen setup. Trying to get the temps working for my ASUS TUF GAMING X570-PLUS (WI-FI), without much luck. Recently with the 6.9.0-beta1 release, I understand that there is support in the new kernel. When I initially upgraded from 6.8.3 to 6.9.0-beta1, I noticed that some temps were visible, but they have gone and now I get an error in my log when I "Load Drivers". I've seen in the 6.9.0-beta1 release thread that I should add `acpi_enforce_resources=lax` to my flash syslinux config, which I did: (I also loaded perl from Nerd pack without issue or error). Log during detection process: May 6 11:11:40 blaster kernel: i2c /dev entries driver May 6 11:11:51 blaster kernel: nct6775: Found NCT6798D or compatible chip at 0x2e:0x290 May 6 11:11:51 blaster kernel: ACPI Warning: SystemIO range 0x0000000000000295-0x0000000000000296 conflicts with OpRegion 0x0000000000000290-0x0000000000000299 (\AMW0.SHWM) (20191018/utaddress-204) May 6 11:11:51 blaster kernel: ACPI: This conflict may cause random problems and system instability May 6 11:11:51 blaster kernel: ACPI: If an ACPI driver is available for this device, you should use it instead of the native driver May 6 11:11:51 blaster kernel: nct6775 nct6775.656: Invalid temperature source 28 at index 0, source register 0x100, temp register 0x73 May 6 11:11:51 blaster kernel: nct6775 nct6775.656: Invalid temperature source 28 at index 1, source register 0x200, temp register 0x75 May 6 11:11:51 blaster kernel: nct6775 nct6775.656: Invalid temperature source 28 at index 2, source register 0x300, temp register 0x77 May 6 11:11:51 blaster kernel: nct6775 nct6775.656: Invalid temperature source 28 at index 3, source register 0x800, temp register 0x79 May 6 11:11:51 blaster kernel: nct6775 nct6775.656: Invalid temperature source 28 at index 5, source register 0xa00, temp register 0x7d I can detect a few different drivers/devices: Error when I "Load Drivers": ACPI Warning: SystemIO range 0x0000000000000295-0x0000000000000296 conflicts with OpRegion 0x0000000000000290-0x0000000000000299 (\AMW0.SHWM) (20191018/utaddress-204) And now all the "Sensors" below are always blank no matter what: Any ideas what might be the matter?

-
Thanks @SpaceInvaderOne I appreciate the compliment. Just hoping that this helps someone else. I really hope that we could get a VM advanced UI for configuring the PCIe settings when using graphics card or sound card: - multifunction on/off - bus - slot - function These are PCIe devices, so it seems to be a common setting, that would translate to the XML like the other UI settings, overwriting the default. This would go a long way to making this easier to fix.
-
Well, I figured it out. I spent many hours trying many different things, but this turned out to be it. Really wished that someone could have pointed me in the right direction, especially with so many current thread posts about the same thing on this forum. As such, I hope that I might be able to help someone else by summarising my journey and how I got there. A full solution is below, but first, I highly recommend watching these 2 excellent videos from @SpaceInvaderOne. Really saved my bacon: 👍 I'm basically summarising much of what he put in the video. My Summary: I was able to fix an already working VM, with my newly added GTX1080Ti using these methods. I didn't need to disable Hyper-V as others have said, and I'm using the latest nvidia drivers. In the end, the "code 43" error that is prevalent, seems to be due to a couple of things: - Modified BIOS, removing application headers from file, using Hex editor. - Specifying GPU pci device as "multifunction" in VM XML. Modifying BIOS: - Download the Hex Editor, install. - Download your compatible BIOS from techpowerup. - Open the bios file in hex editor. I'm using HxD like in the video. - Look for line that looks like "UªyëK7400éLwÌVIDEO", mine was prefaced with a series of "ÿÿÿÿÿÿÿÿÿÿÿÿÿÿÿÿ" characters. - Next, delete everything above line "UªyëK7400éLwÌVIDEO", so that the matching offset reads "00000000" (8 zeros). - "Save As..." the file with a new filename. Save it somewhere on your unRAID system, like one of the shares. - I saved mine to "isos" share. You can save it anywhere on unRAID. - You're done. Modifying your VMs XML: - Before Starting, make sure your GPU is in its own IOMMU Group (Tools->System Devices). - If your GPU is not in its own IOMMU Group (Its fine if the GPU shares that group with the GPU-Audio). - Setup your VM in unRAID as normal. - I have had success using "Q35-4.2" Machine type, and "OVMF" BIOS. I left Hyper-V "on". - I'm using VirtIO Drivers "virtio-win-0.1.173-2" if that is helpful. - Specify your GPU and GPU-Audio Sound Card of the GPU. Always add your GPU-Audio, dont try to avoid it. You need it. - If you want to use your motherboard sound card, you should add it by clicking the green plus-sign on the left. - Either "CREATE" (Do not "Start VM after creation") or "UPDATE" the VM at the bottom, to set a baseline config. - Go back into the VM config. On the right change "FORM VIEW" to "XML VIEW". - Find the lines for the GPU and GPU-Audio, the line should start with "<hostdev" and a line later will end the section with "</hostdev". - You should see 2 hostdev devices, there may be more. The first should specify your GPU BIOS you specified earlier. - You need to change the the lines that specify the "<address" within the VM, not the "<address" outside the VM (in the host). - On the first line, change nothing, but add "multifunction='on'" to the end before the "/>" close. - On the second line, change the "bus" and "function" to match the first line, but add 1 to the function. - When done editing, I recommend copying the whole xml and keeping a backup somewhere. - Save the config by clicking "UPDATE" at the bottom. - You're done. Something to note is that if you change ANYTHING using the GUI, it will overwrite these pci XML modifications. So, again I'd recommend keeping a backup somewhere in your unRAID. With this, I was able to use my single nvidia card without issues. Thanks again to @SpaceInvaderOne for figuring this out. I hope this can help someone else. ☺️





-
I've dunped my BIOS out directly in unRAID, and trying to follow instructions to fix. I'm unsure if this means something but I've noticed when running "lspci v" is that there is no kernel driver listed next to my card: 0d:00.0 VGA compatible controller: NVIDIA Corporation GP102 [GeForce GTX 1080 Ti] (rev a1) (prog-if 00 [VGA controller]) Subsystem: eVga.com. Corp. GP102 [GeForce GTX 1080 Ti] Flags: bus master, fast devsel, latency 0, IRQ 5 Memory at f4000000 (32-bit, non-prefetchable) [size=16M] Memory at e0000000 (64-bit, prefetchable) [size=256M] Memory at f0000000 (64-bit, prefetchable) [size=32M] I/O ports at f000 [size=128] Expansion ROM at 000c0000 [disabled] [size=128K] Capabilities: [60] Power Management version 3 Capabilities: [68] MSI: Enable- Count=1/1 Maskable- 64bit+ Capabilities: [78] Express Legacy Endpoint, MSI 00 Capabilities: [100] Virtual Channel Capabilities: [250] Latency Tolerance Reporting Capabilities: [128] Power Budgeting <?> Capabilities: [420] Advanced Error Reporting Capabilities: [600] Vendor Specific Information: ID=0001 Rev=1 Len=024 <?> Capabilities: [900] Secondary PCI Express <?> 0d:00.1 Audio device: NVIDIA Corporation GP102 HDMI Audio Controller (rev a1) Subsystem: eVga.com. Corp. GP102 HDMI Audio Controller Flags: bus master, fast devsel, latency 0, IRQ 4 Memory at f5080000 (32-bit, non-prefetchable) [size=16K] Capabilities: [60] Power Management version 3 Capabilities: [68] MSI: Enable- Count=1/1 Maskable- 64bit+ Capabilities: [78] Express Endpoint, MSI 00 Capabilities: [100] Advanced Error Reporting Also, I'm unable to either unbind or bind the device: # echo "0000:0d:00.0" > /sys/bus/pci/drivers/vfio-pci/bind -bash: echo: write error: No such device # echo "0000:0d:00.0" > /sys/bus/pci/drivers/vfio-pci/unbind -bash: echo: write error: No such device
-
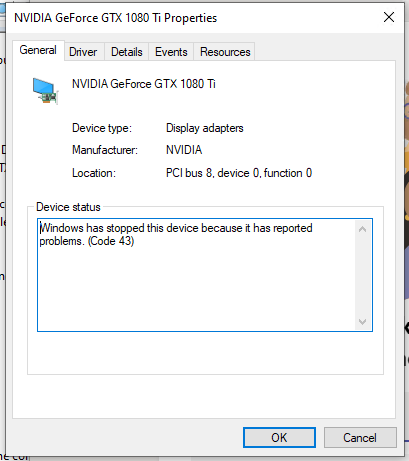
Another strange finding, is that my Windows 10 VM boots up and I can RDP to it. Looking around the system and forums more, it could be the "code 43" error.
-
I believe that this should be the correct BIOS for me to use from techpowerup, as it has the same modified date as the build date on my BIOS (2017-04-17) and VBIOS Version (86.02.39.00.90) that I got from the dump. Still doesn't work. I'm not sure what else to do.
-
Hi all, I'm hoping someone can help. I'm having trouble with passing through a GTX1080TI GPU. I am using model EVGA 11G-P4-6696-KR, known as "EVGA GeForce GTX 1080 Ti FTW3 GAMING". I had trouble finding a compatible BIOS on techpowerup, because there is no direct comparison. I saw that there are "FTW3 Elite Gaming" and "FTW3". I've tried the FTW3 BIOS, but not the FTW3 Elite, I'm concerned that it is not appropriate. So I dumped the bios in a bare metal Windows 10 install using nvflash, and have saved it to my array. Even still, I cannot seem to get my VM to boot with it using any configuration. The screen flashes and then no signal, every time. I need to reboot to get anything back. I was able to boot into Windows 10 using the bare metal install, so I think the card is working. I've watched the videos by SpaceInvader and I've passed through cards before using this system (An R9-290 and recently a RX-5600XT that I am returning). Both worked without much issue at all. Can anyone help with advice? I also dumped the version using nvflash: NVIDIA Firmware Update Utility (Version 5.590.0) Copyright (C) 1993-2019, NVIDIA Corporation. All rights reserved. Sign-On Message : GP102 PG611 SKU 50 VGA BIOS Build GUID : 402D5B72B8A34DFBBEB8A9C5CD99EE31 IFR Subsystem ID : 3842-6696 Subsystem Vendor ID : 0x3842 Subsystem ID : 0x6696 Version : 86.02.39.00.90 Image Hash : AAA37529FD718F13599221F885E83C25 Product Name : GP102 Board Device Name(s) : GeForce GTX 1080 Ti Board ID : 0xEE17 Vendor ID : 0x10DE Device ID : 0x1B06 Hierarchy ID : Normal Board Chip SKU : 350-0 Project : G611-0050 Build Date : 01/18/17 Modification Date : 04/17/17 UEFI Version : 0x30006 UEFI Variant ID : 0x0000000000000007 ( GP1xx ) UEFI Signer(s) : Microsoft Corporation UEFI CA 2011 XUSB-FW Version ID : N/A XUSB-FW Build Time : N/A InfoROM Version : G001.0000.01.04 InfoROM Backup : Not Present License Placeholder : Not Present GPU Mode : N/A
-
Thats great advice, thanks. I'm also using the CA User Scripts plugin for this, so good to know. I've had it in my mind to get down and get a more robust solution like this in place over my current simple copy. I'm no slouch o Shell scripts, so I'm going to see if I can write some scripts to accomplish these tasks. Thanks again.
-
This is amazing @Hoopster, thanks for putting this up. I've been looking at improving my backup process between servers, and integrating pfSense backups to unRAID. Along with the CA User Scripts plugin, I'm going to give this a try. I realise also that this is quite a while after your post, do you have any things you added to this, or is it still working as-is to now?














