




KptnKMan
Members
-
Joined
-
Last visited
Everything posted by KptnKMan
-
Oh wow, just seen it now thanks. I'm glad this is being investigated. I guess I don't need to test disabling the other nics, if its being chased down. It doesn't "seem" (in my uneducated view) to be due to other nics being present, but I have no idea how to prove that. Still, I will test to see if the settings can at least persist in current state throughout like half a dozen reboots or so. It also seemed in my testing, that as soon as I try to line the interfaces up, it freaks out. Seems like interfaces get created then mess up what I'm blindly doing. Still, if the config assignments can at least persist, at least I can leave it alone and wait for smart people to fix it. Hopefully.
-
The duplicates are created BY THEMSELVES before any editing, and I documented the only ways I found to fix this known issue. If you check my thread, editing the network.cfg and network-rules.cfg manually is the ONLY way to make it work, and the GUI gets broken from edits and refuses to save when duplicate cards are created. This is tested on separate machines independently, and others have reported this all over the forum. So, I followed my previous method and this is the result. I'm saying clearly that this issue is NOT FIXED, but it seems to be tentatively stable in the GUI, at least in my current testing. I'm happy about that so far. I'm going to try some more poking at this in the coming weeks and post it in the thread I started about this issue, so check in there if you're interested in following. 👍
-
I'm not actively using the onboard for anything, although I still want to have working "active-backup mode 1" interface fault tolerance, which I noticed is now set by default apparently since upgrade 6.10.1 from 6.9.2. I'll try to test disabling the onboard nic in BIOS and see how that goes as well, but I'm not sure when I'm going to have time in the next days/week. As soon as I do this, I'll post my results and hope someone finds it useful. I'll just add that the upgrade to 6.10.1, in my setup at least, was flawless and currently without any noticeable issues. Bravo to limetech for this achievement, I know that 6.10 was long in testing. 👍
-
So I've got an update on this issue, especially for anyone wandering in looking for answers. Yesterday I updated both my unRAID systems to 6.10.1, and posting results. According to release notes, 6.10.1 is running Linux kernel version 5.15.40-Unraid (CVE-2021-33909 CVE-2021-33910 CVE-2022-0847). Notably, this is not kernel 5.16, which I understand has the fixes/updates for correct k10temp detection, so I assume that one of the modules has been backported to this version. Looking through the release notes, there are references to updated modules like lm_sensors: version 3.6.0 and others, but I cannot tell right now which specific library may have been updated. Secondary unRAID, ASUSTeK COMPUTER INC. TUF GAMING X570-PRO (WI-FI), BIOS version v4021 (Latest stable is 4204 with 4403 beta available). After the upgrade, it looks like all the sensors for the X570-PRO are working, I did not do any manual detection but showed up and lists everything I would expect: Primary Unraid, ASUSTeK COMPUTER INC. TUF GAMING X570-PLUS (WI-FI), BIOS version v4203 (Latest stable is 4204 with 4403 beta available). System works as expected, but seems to have reset to showing all the sensors again, I have not tried any manual detection. I note that Perl is no longer installed but everything seems to work: All things considered, I'd call this a win. 👍
-
So this is essentially the same post as I left in the other thread, but I'm leaving it here because of completeness and also if possible, I'd like to find out @Ford Prefect's opinion on the basic testing I did: Yesterday I took the dive and updated my secondary unRAID to 6.10.1, then later my primary once I saw everything was working well. In particular regard to the 10Gbit dual ConnectX-3 cards, I did some rudimentary testing after upgrade on both systems (I had 164 days solid uptime on my secondary 😁) and found that it works but (at least in my case) not perfectly. I'm going to be keeping an eye on it still, but I'll try to explain my findings. So after upgrading my secondary (My less fussy system because I hardly ever mess with it), I saw that the installed cards were all listed but they were listed as eth0 (mlx4_core), eth2 (mlx4_core) and eth3 (igc). So I went to the network.cfg and network-rules.cfg, and changed them to be eth0, eth1, eth2, and rebooted. Upon reboot I found the same issue where the cards were duplicated and had become eth0 (mlx4_core), eth1 (igc), eth2 (mlx4_core duplicate?), eth3 (mlx4_core). So I thought "uh oh" and edited the network.cfg and network-rules.cfg to reflect the original setup eth0, eth2, eth3. That seemed to work again, and I fully rebooted 3 times to check confirm that the configuration would persist through restarts. Seems good, so then I thought upgrade the primary unRAID to see what's really up. Upon upgrading my primary unRAID, I immediately saw that 4 cards were listed, eth0 (mlx4_core), eth1 (r8169), eth2 (mlx4_core duplicate?), eth3 (mlx4_core). So I thought to immediately try to duplicate the eth0+2+3 configuration of the secondary. After setting network.cfg and network-rules.cfg and rebooting, that seemed to work and no duplicated were present. They showed up as eth0 (mlx4_core), eth2 (mlx4_core), eth3 (r8169). I rebooted my primary server a further 3 times, to check that the card assignments were persistent. It looks at this moment like the configuration stuck, but I'm still hesitant to change anything. I'm planning in the coming days to reboot my primary a few more times and see if anything switches around, or goes strange. So far, so good though. 👍
-
Yesterday I took the dive and updated my secondary unRAID to 6.10.1, then later my primary once I saw everything was working well. In particular regard to the 10Gbit dual ConnectX-3 cards, I did some rudimentary testing after upgrade on both systems (I had 164 days solid uptime on my secondary 😁) and found that it works but (at least in my case) not perfectly. I'm going to be keeping an eye on it still, but I'll try to explain my findings. So after upgrading my secondary (My less fussy system because I hardly ever mess with it), I saw that the installed cards were all listed but they were listed as eth0 (mlx4_core), eth2 (mlx4_core) and eth3 (igc). So I went to the network.cfg and network-rules.cfg, and changed them to be eth0, eth1, eth2, and rebooted. Upon reboot I found the same issue where the cards were duplicated and had become eth0 (mlx4_core), eth1 (igc), eth2 (mlx4_core duplicate?), eth3 (mlx4_core). So I thought "uh oh" and edited the network.cfg and network-rules.cfg to reflect the original setup eth0, eth2, eth3. That seemed to work again, and I fully rebooted 3 times to check confirm that the configuration would persist through restarts. Seems good, so then I thought upgrade the primary unRAID to see what's really up. Upon upgrading my primary unRAID, I immediately saw that 4 cards were listed, eth0 (mlx4_core), eth1 (r8169), eth2 (mlx4_core duplicate?), eth3 (mlx4_core). So I thought to immediately try to duplicate the eth0+2+3 configuration of the secondary. After setting network.cfg and network-rules.cfg and rebooting, that seemed to work and no duplicated were present. They showed up as eth0 (mlx4_core), eth2 (mlx4_core), eth3 (r8169). I rebooted my primary server a further 3 times, to check that the card assignments were persistent. It looks at this moment like the configuration stuck, but I'm still hesitant to change anything. I'm planning in the coming days to reboot my primary a few more times and see if anything switches around, or goes strange. So far, so good though. 👍
-
Oh shit yo, I didn't even know that 6.10 went gold! I have some reading to do! I haven't decided when to upgrade, but I may wait a little bit and figure out some stuff or upgrade 1 of my systems and see. As always, stability is my top priority for my particular setup.
-
I wish I was happy with that, I'm basically in the same position, I've just left it alone and not touched it. But it means I cannot setup any complex networking until it is solved, because I want to setup interface failover on my servers, but I can't because of this instability. I've documented trying to make this work in my other threads on getting to 10Gbit and the thread linked earlier here as well. I just try not to think about how bummed I am about that, but stability is my priority.
-
This is definitely an issue I'd love to see an answer for, or in the least a sustainable workaround. Alas, every time I see this issue raised, I see the response "Update your firmware". I've documented my issues quite well on this forum (As linked above), and how I've tried to workaround it, but it seems to be hoops that I have to jump through after each reboot. Not a great solution for an automated headless remote server. I'd also appreciate to see what the results of the Debian server test are, if you got around to it.
-
Thanks, I appreciate you responding with an explanation and I appreciate your following advice but I have looked through the template trying to find a solution, and I have to say that your reasoning here contradicts just a couple things (This is just my opinion, I'm not the supporter of this template so it doesn't matter in that regard). You say that this overcomplicates things, but I would argue that a separate variable is arguably more simple. There are variables similar to this throughout your base template, that are unused, such as "GAME_PARAMS". I'm just saying, it's a little inconsistent with your implementation that there are variables unused, that can be enabled by what I would call "advanced users", which I assume would be "at your own risk". Again, just my opinion, but a separate variable is arguably a lot simpler and consistent. I couldn't agree more, I'm not arguing against best practice, this was just me trying to get the functionality to work. That's fair enough, I completely understand you don't want to support something that could potentially lock someone's account. In my opinion, a disclaimer that "This is unsupported" would be clear that this is functional but most definitely "Unsupported and at your own risk. Don't ask me for help if you lock your account". It would also help to answer questions about Steam Guard that I have already seen people asking here without doing any research (I tried to do research before asking). I couldn't agree more! 😁 Thanks, I'll check this out. Definitely good advice for an alternative. I've already been looking into setting up a second account for this purpose. Lastly, once again this is all just my opinion, so I'm just trying to test and ask questions. I appreciate you working hard on this template, and my request and offer for a PR is meant to be constructive not to indicate that there is something wrong with your template. I don't think that functionality that is "unsupported" is a bad thing, as long as that is clearly stated, because it may give a better understanding to other people. Saying that, I understand why you want to stay clear of it because of the potential hassle. I just wish that it was there because I am someone who genuinely wants to use it. Anyhow, thanks anyway. 👍
-
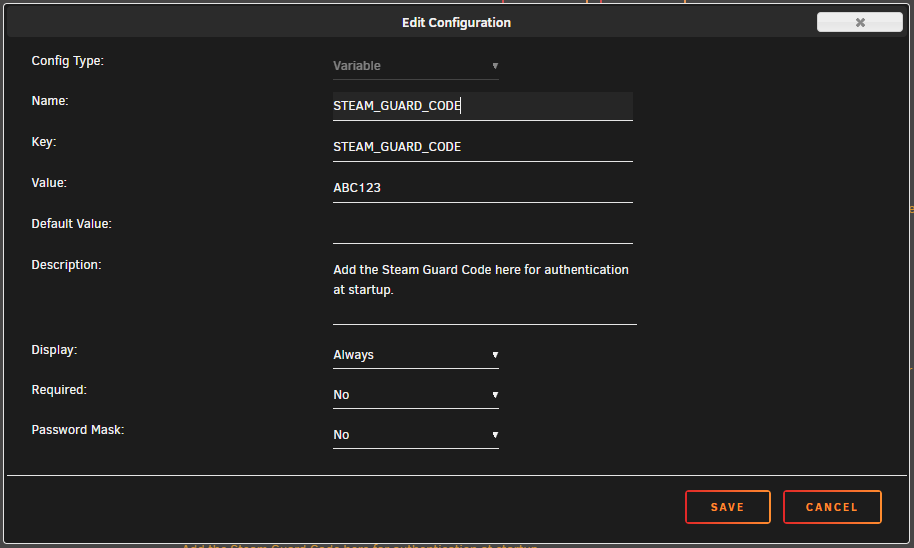
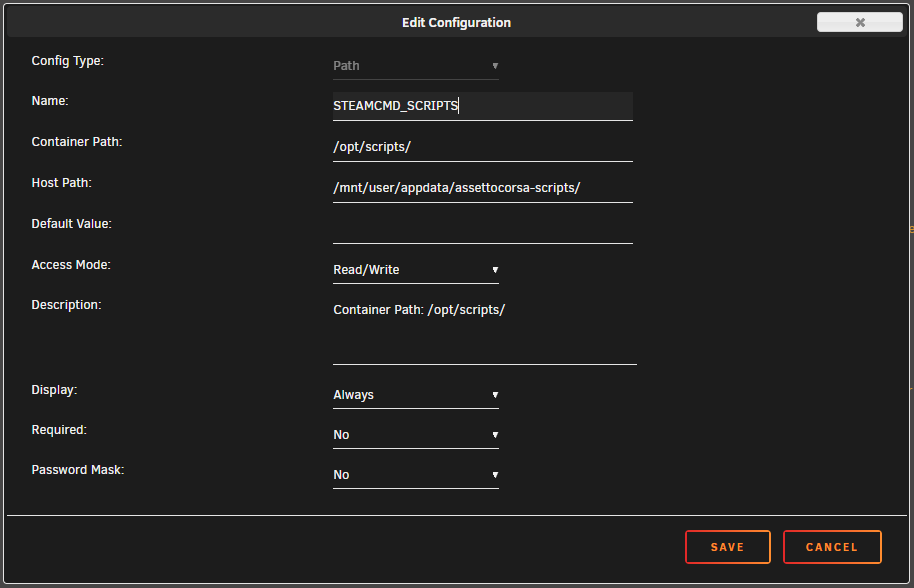
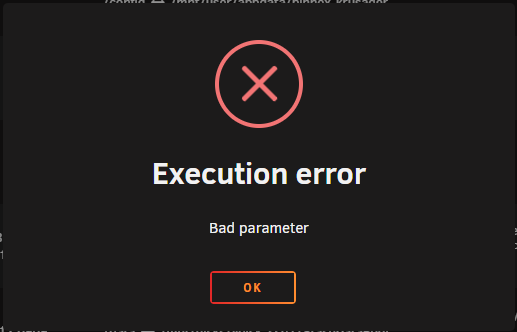
Hi @ich777 I've been trying to get the Assetto Corsa image to work, but of course I have Steam Guard enabled and it fails no matter what I've tried. So I have a few questions that maybe you might be able to enlighten me with your experience? I saw that (within the image) in the `/opt/scripts/start-server.sh` file contains everything for running steamcmd and the various steps including `---Update SteamCMD---` and `---Update Server---` and I've been trying to add `+set_steam_guard_code ${STEAM_GUARD_CODE} \` in there so that I could add a `STEAM_GUARD_CODE` variable in the Unraid template and make that work. I couldn't get this to work, mostly because restarting the docker container refreshes the files in `/opt/scripts/`. I tried adding the Path to the template, so that I could manually edit the scripts persistently (To add a couple lines in): But alas, this did not work, and presents an "Execution error" that I cannot solve, but works again when I remove the Path: I would like to test further but this has me stuck. Do you know how I can make that Path work? I also looked up the Valve Developer wiki and saw that the SteamCMD section specifies the `set_steam_guard_code` is available, but also specifies to check the latest version and commands on the GitHub repo, which specifies there that the `set_steam_guard_code` is also present, but isn't in practice. In practice, the syntax for `steamcmd login` specifies `login : <username> [<password>] [<Steam guard code>]` so this line worked for me in the command console: `/serverdata/steamcmd/steamcmd.sh +login MYSTEAMUSER MYPASSWD GUARDCODE +quit` I found that I could make this work by using the Steam Android app authenticator, I could wait for the Steam Guard code to reset then in the template IMMEDIATELY AND QUICKLY specify my `PASSWRD` (Steam-Password) variable as `MYPASSWD GUARDCODE` to authenticate with Steam Guard still enabled. This is time sensitive because the Steam Guard code resets within 30 SECONDS. Within this 30 seconds, both the `---Update SteamCMD---` and `---Update Server---` steps need to authenticate (login) in time before the Steam Guard code changes. Within `/opt/scripts/start-server.sh` the step `---Update SteamCMD---` doesn't require authentication and should be faster to run with `/serverdata/steamcmd/steamcmd.sh +login anonymous +quit` (At least in my testing), but the second step `---Update Server---` seems to require authentication and work with the command: ```/serverdata/steamcmd/steamcmd.sh +@sSteamCmdForcePlatformType windows \ +force_install_dir /serverdata/serverfiles \ +login MYSTEAMUSER MYPASSWD GUARDCODE +app_update 302550 \ +quit``` With all that in mind, could the variable STEAM_GUARD_CODE be added to the template as a variable immediately after the actual password? Here is an example of what I mean: ```${STEAMCMD_DIR}/steamcmd.sh \ +login ${USERNAME} ${PASSWRD} ${STEAM_GUARD_CODE}\ +quit``` I could put together a PR reflecting this, if you would consider this for advanced users? I would DEFINITELY consider using Steam Guard or such a variable advanced. I'm just trying to get this to work.
-
Hey man, I haven't solved this issue, I've just sort of been ignoring it for a little while because everything "works" well enough in its current state. My plan to have failover working is not possible with this issue present though, so that's a blocker. Every time I come back and see if anyone has gotten further, I see that the best advice is to upgrade the firmware and see if it fixes it. So far from what I've seen, reports show that the latest firmwares don't fix the issue. Bummer.
-
I've been on a mission to get UEFI and rBar working this last few weeks. I did everything above before reading all of this, and confirmed everything in a bare-metal install (Also so I could use NVFlash to backup the old and new BIOS). After all of this, I still get a black screen when booting the VM that works perfectly fine with CSM enabled. Interestingly, I also find that I am unable to boot into "Unraid GUI mode" when booting Unraid UEFI enabled. When I boot the "Unraid GUI mode", everthing appears to boot correctly, and at the last moment when the screen goes black to show the GUI all I see is a flashing terminal cursor in the top left corner of the screen. Normally the GUI would boot and display the graphical login prompt. Has anyone else experienced this or understand why this is? This happens before booting any VM, and VMs boot to a black screen also, when they would normally boot ok. I'm also seeing this in my logs with CSM disabled. I was going to start a new thread about this summarising my experience, but I don't know if maybe I/we should try to work together about it here?
-
@LexBergif you're interested in doing a lot of reading around 10Gb cards, I'd recommend checking out the thread I started about this. Lots of info in there, details, links and recommendations of what I did and eventually purchased. I'm still happy with my 10Gb setup to this day.
-
Please, I'm trying to seek some help. I have got this container running, but after setup when I got back to the login page it flashes up for a second then disappears. I've reinstalled multiple times, cleared postgres and redis, reinstalled all dependencies. I can login initially and setup Photonix, then next login the login screen flashes up for a second then disappears again. This happens from then on each time the login is accessed. The logs don't seem to show any errors, shows postgres connected. I've tried accessing from different browsers, InPrivate mode, different client workstations, same login prompt flashes up for a second then is gone. Its quite irritating and I cannot find what is the matter. Can anyone help?
-
Sorry no, I strongly disagree with the assertion of "going bleeding edge hurt nothing". We all know clearly enough, that updating can break thing just as much as fix things... and often does introduce issues. If you need your unraid for anything more than a test/play box, then it's something we all consider when upgrading especially to dev/RC releases. The prospect of encountering issues on a working server that you need for daily functions, for the sake of "bleeding edge" is (to put it lightly) discouraging. This thread is about temperature monitors in kernel versions of unraid, so that being said, the idea of upgrading to an unraid version to maybe get a feature that you know is not in the kernel version of that release is risking a lot and frankly a bit stupid.
-
Thanks, I appreciate you clarifying some of the key points here. I'm going to think a bit more about exactly my use case and figure out how this can be better worked into my backup plan process. I may use another tool together with this, to get 2-way syncing for some selective workflows.
-
Hi, using the settings RCLONE_OPERATION=copy and RCLONE_DIRECTION=both I can see traffic in both directions like so: 1) new local file, copied to remote, yes. renamed file produces duplicate. 2) new remote file, copied to local, yes. renamed file produces duplicate. 3) change local file (edit txt), changes are reflected on remote, yes. 4) change remote file (edit txt), changes are NOT reflected on local, no. Changes are overwritten. This is single changes, single change at a time.


-
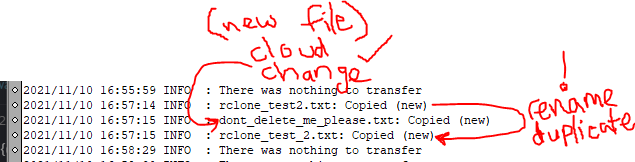
Ok, I understand the risks of what you've described, but I think maybe I'm not communicating this well enough. I think I'm using the word/term "sync" loosely, so maybe I can clarify. My bad. I set the variables to RCLONE_OPERATION=copy and RCLONE_DIRECTION=both, and made 2 changes on the remote cloud side; I created a new file "dont_delete_me_please.txt" and renamed a file "rclone_test2.txt" to "rclone_test_2.txt" (added the 2nd underscore to the filename). With that logic, I expected the operation to delete the local copy of "rclone_test2.txt", then copy down "rclone_test_2.txt" and "dont_delete_me_please.txt". But I had the duplicate behaviour as shown in the screenshot. It duplicated the renamed file, and copied down the new file. But I take it that the RCLONE_OPERATION=copy behaviour will never delete anything, but only copy, which is fair enough (Is that correct?). The original issue however, was that when setting RCLONE_OPERATION=sync, it would only sync in 1 direction. So am I correct in thinking that (Assuming RCLONE_DIRECTION=both) an RCLONE_OPERATION=sync operation will copy everything in 1 direction, then copy everything (including the previous copy) in the other direction (including new duplicates)? Am I missing something?
-
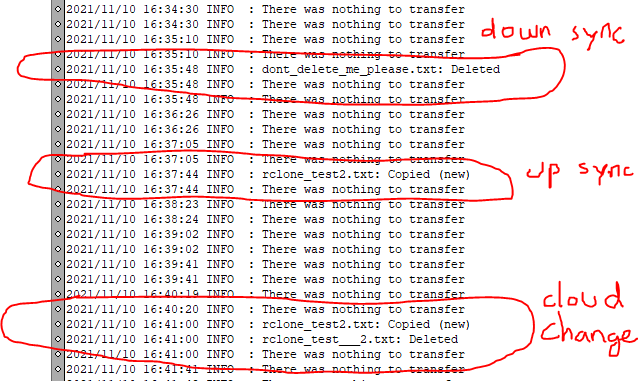
Ok, so I changed the variable RCLONE_OPERATION=sync to RCLONE_OPERATION=copy and now files are copied, but and changes are not recognised. As a result a changed file is duplicated, where the "old" (un-renamed) file is replaced and the "new" (renamed) file is synced. Any ideas?
-
Hi, After some messing around I've got docker to connect to my OneDrive, and I'm testing syncing. However, I can only seem to sync files UP, but not DOWN, and if I add files to the folder from the OneDrive side, they are deleted. If I change something on the OneDrive side, the "new" (changed) file gets deleted, and the "old" (unchanged) file is synced back up in its place. Seems like a working 1-way sync, I'm trying to get 2-way. I've resolved all errors in the logs/reports, and the link seems to be working. Anyone know why this is happening? I have the variables set as following: RCLONE_OPERATION=sync RCLONE_DIRECTION=both
-
Yeah that's fair enough, I didn't know if there was something else behind your comment. I suppose it is fair enough, I often think out loud as well. The script error does seem to have gone after the recreation, so I think there was a script with an "assumption" somewhere that didn't check if the bridge device existed first. it is a bit strange though. I'm not sure if I'll get to the bottom of that one, but hopefully someone can find this and it might help them in the future. I usually use notepad++ from another machine, which allows for whitespace and non-printable character detection, as I've had that annoyance before. Its a good thing to keep vigilant for, and I will do a deeper look to see if something is occurring. For now, it seems to have confirmed my suspicions that the files were created when the network configuration was modified in the GUI, but that caused a bunch of things to go wrong at the same time. It's quite sad that this doesn't want to behave with a relatively simple configuration.
-
If the temp improvements are confirmed to be in kernel 5.16, in my opinion it doesn't seem like a good idea to upgrade just to see if it will work if 6.10rc2 is confirmed to have kernel 5.14.15. Seems like a good way to possibly create more issues (Like the share configuration being disabled/modified) where there might not be right now. I've been waiting and considering 6.10rc2 for a while, especially with the first inclusion of swTPM for Windows 11, but still I wouldn't advise upgrade without solid reasoning. Right now, I've been watching and reading to see what the reported experiences are. I know I can potentially roll back, but that's not a great plan for me personally. I need my servers, and I'm still struggling with some other unraid issues around 10Gbit networking and bonding. Honestly, I wish that kernel 5.16 would be used if that includes temp monitor updates for X570 motherboards, but that will come later for other reasons I suppose. Also, my X570-PLUS seems to work quite well. Saying that, I'm not keen to change anything, as I've done that before and lost all of my sensors. ¯\_(ツ)_/¯
-
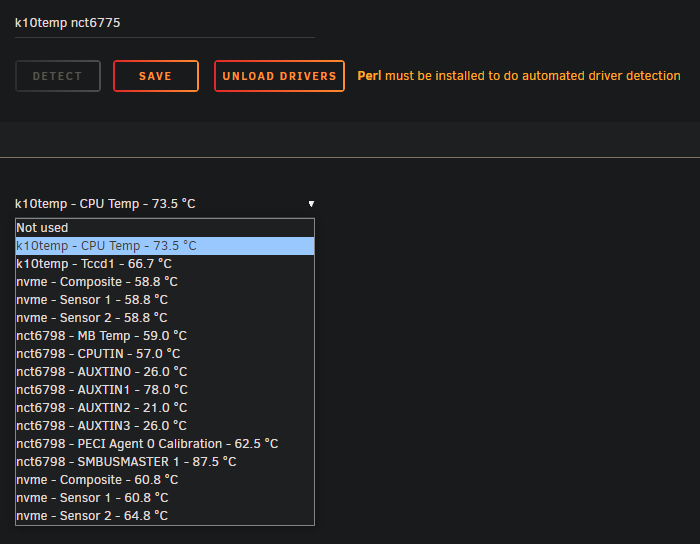
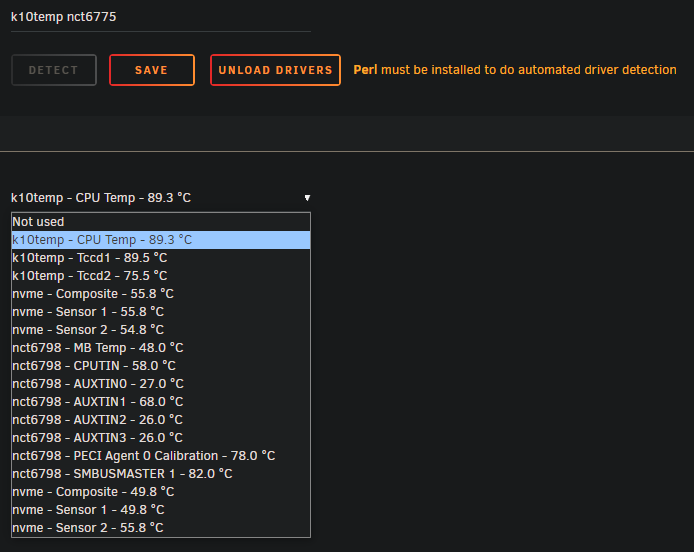
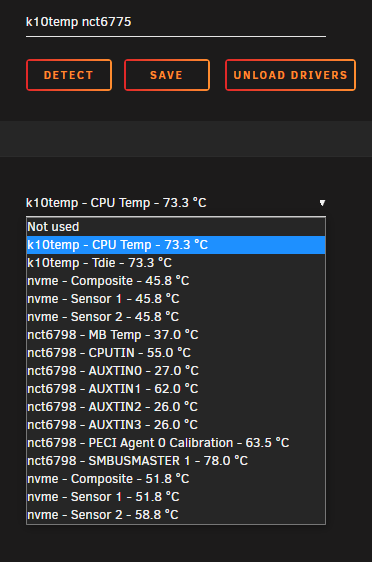
These are the sensors I see on the X570-PLUS: These are the sensors I see on the X570-PRO:
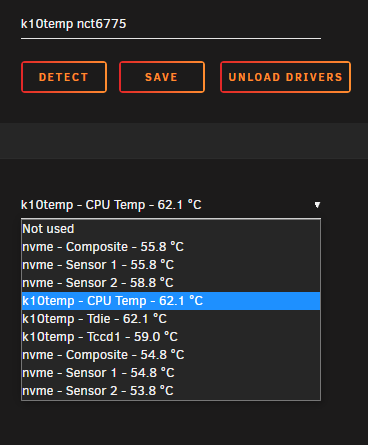
-
Hi, I upgrade both my systems last week to BIOS version 4021 and I've been having the same issues. I still have working temps on the X570-PLUS and not on the X570-PRO. Seeing as they are both using the same chipset, I've been trying to copy the temp configuration from Unraid1 over to Unraid2, but I've not managed to make it work yet. I did this by copying the file /boot/config/plugins/dynamix.system.temp.plg and the contents from /boot/config/plugins/dynamix.system.temp/ to the other server. After a reboot, that didn't seem to work. If anyone has any idea how I can copy a working temp config to another server, I would be grateful.











