




KptnKMan
Members
-
Joined
-
Last visited
Everything posted by KptnKMan
-
Hi I have been encoutnering a repeated error when trying to format my new array: Unmountable: Missing encryption key Hardware I'm using is a CWWK CW-X86-P6. The issue SEEMS to be with 2 drives out of 4, I have tried swapping them but the same 2 drives seem to go "missing" when I stop the array. The same 2 drives show the "missing encryption key" error when formatting the array. I restart the system, the drives are back, I setup the encrypted array and same issue. I've done the New Config a number of times to reset the array, and setup an new disk array, same issues. I can't see anything negatively drive related in the syslog. I'm running a preclear on all 4 of the nvme drives now to see if that shows up anything. Please any help would be great? blaster-diagnostics-20250526-2307.zip
-
I noticed that my mysql container is not working. All servers and systems cannot access. phpmyadmin cannot login. When in the container, trying "mysql status" returns: ERROR 2002 (HY000): Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock' (2) I've been hunting around inside the container, and can find no logs, because it appears that the main mysql process will not start. I'm not sure how this could suddenly happen, nothing changed in my configuration. Anyhow, I've tried chown on the directory /var/run/mysqld and /var/lib/mysql I tried to create the sock file manually, that produces no good results just another similar error. Tried creating a new symlink, that results in an error "cannot access '/var/run/mysqld/mysqld.sock': Too many levels of symbolic links" Tried deleting and recreating the contaner. Tried updating to latest (I was using 9.0.1 and updated to 9.1.0. I'm unsure how to install any tools in this distro, yum and dmf seem to be missing. I'm pretty stuck at this point, googling and trying to understand. Can anyone help?
-
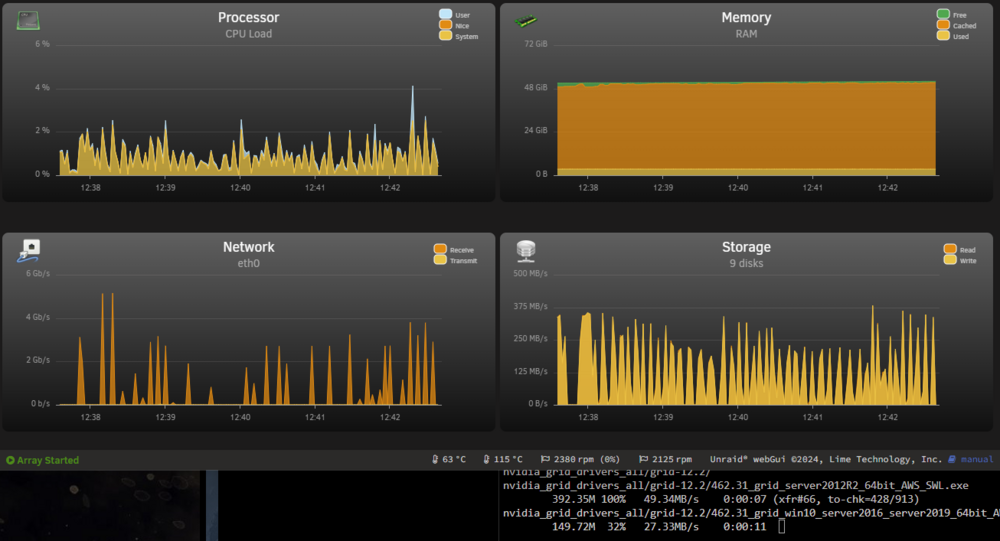
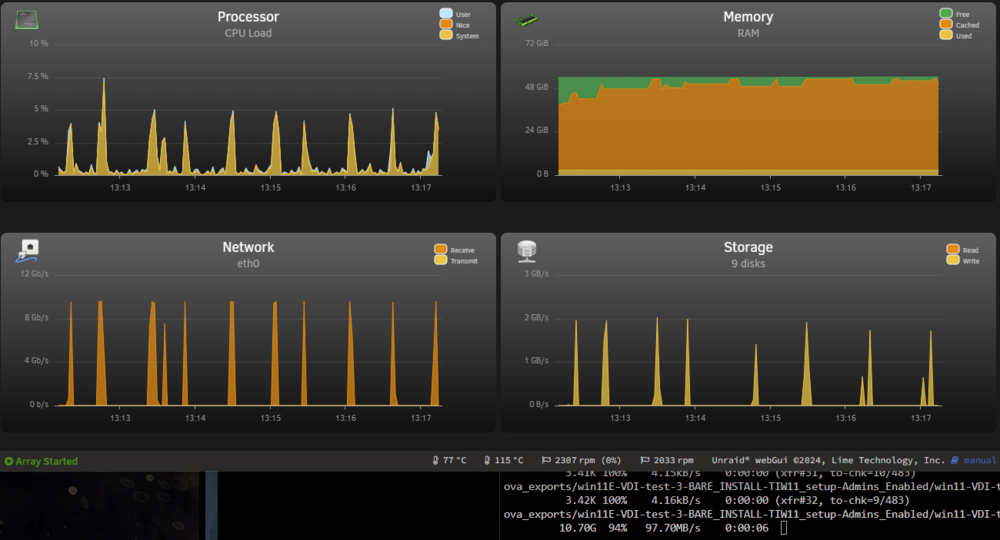
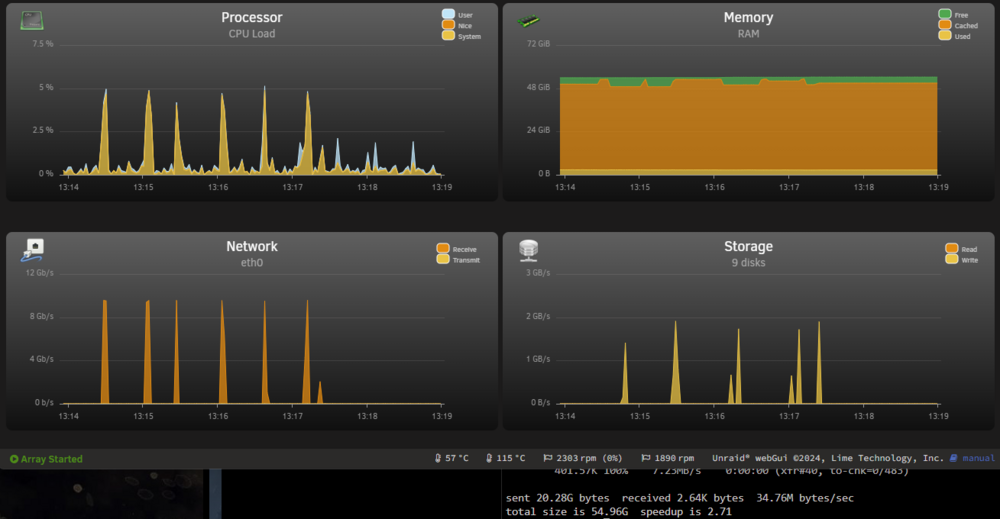
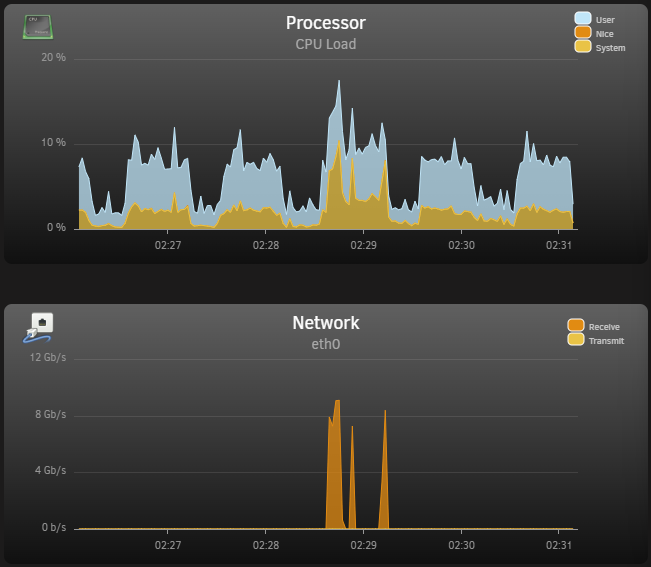
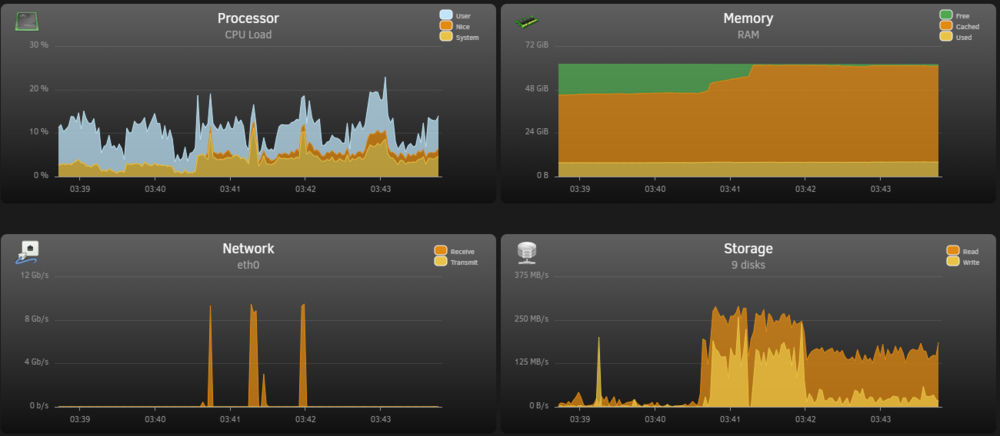
Thanks for the responses guys, I've looked into things and did another full review... but I still think SOMETHING was up. The reason I say this is that I know that my array is capable of writes more than 70MBs, and very low write speeds is what alarmed me. Its visible on the graphs that there is a lot of reading at 200MBs and little writing at a low ~10-15MBs. I also came to the same educated guess conclusion that it's caching, but the numbers still didn't sit right. I left it running all night, and I think the same happened, there was a relatively small amount transferred. Today, I saw my ISP router had an issue overnight (Coincidence, no idea), and decided I would do a full restart of the entire network and UNRAIDs (Have not done that in years at this point). So I cold started both the UNRAID servers, and cold started my ISP router, pfsense router, all wifi APs, all switches. After that I waited for everything to settle and started the transfer again. I also turned off Docker and VMs on both servers to make sure I'm seeing relatively real numbers. This is now what I'm seeing on UNRAID2: I think this is more inline with what I was expecting to see, the write speed of the disks is much higher at 200MBs, in fairly consistent bursts. Maybe its that the spinning disk caches will fill up and the writes will drop down again, but it seems pretty consistent so far. I woud still expect something above 15MBs, but maybe its a psychological thing like you said. Am I wrong in this estimation? I also did a test with trasferring 55GB with the cache turned on, to compare again, and its again what I would expect with writing to the cache at 2GBs, bursting to the NVME drive: And the 55GB finished, looked along what I expect, it's consistent even though its in bursts (Where before it seemed to stall for VERY long time): And with that done, I then waited for the cache to empty to disk and ran the mover: The mover is apparently great at consistent writes above 300MBs though. If the mover is writing at 300MBs to disk, and the remote transfers in from spinning disks anyway, is it better to just leave the cache on? In the end, would you advise migrating large data with the NVME cache on or off, I mean overall? I still have another ~6.5TB to migrate. I made sure that turbo writes/reconstruct write is turned on before this migration, it's actually been on a week now in preparation for this. Thanks for the reminder, I've been wondering, is it advisable to have this turned on long term as I have read that it is harder on the array disks?
-
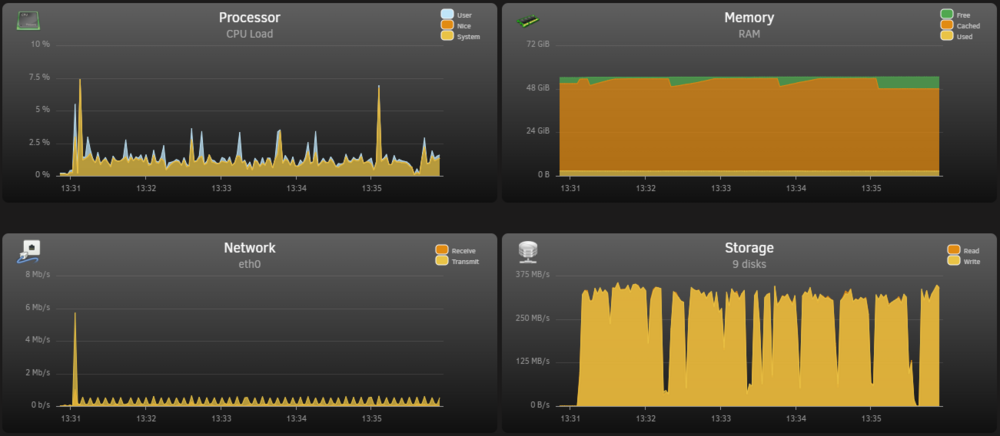
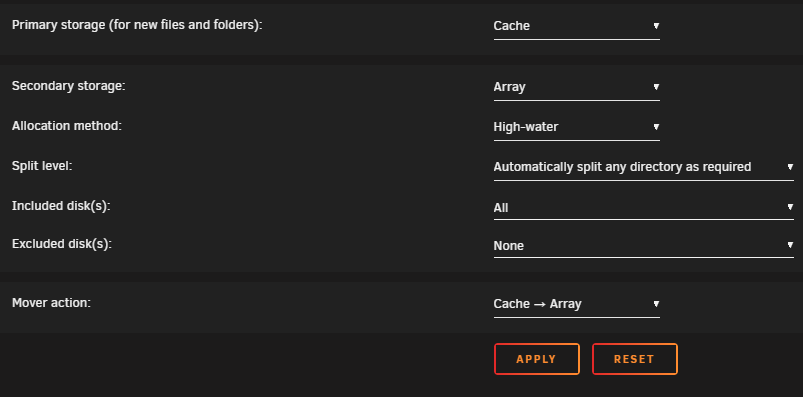
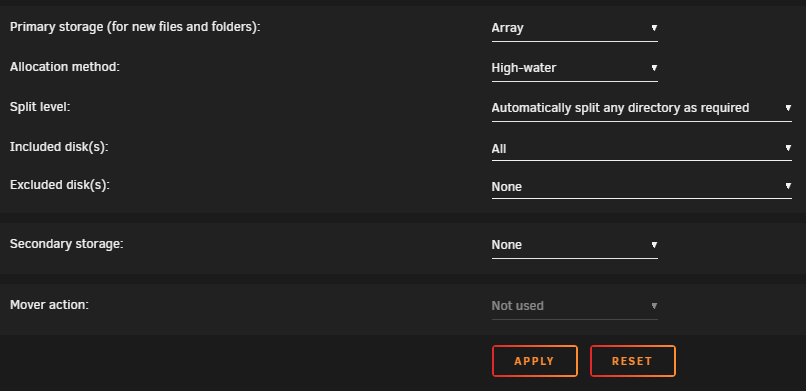
Hi, so I'm trying to move/migrate about 8TB of data between two unraid servers. Both systems equipped with 10Gbit networking, and have been working fine otherwise. I have mounted the UNRAID2 SMB unraid shares on UNRAID1 as remote mount points. I have been trying a "push" migration, running commands on UNRAID1 to "push" files over to UNRAID2. I have checked through all networking settings and everthing seems fine, nothing has been changed. Everything else is working fine on the network. I started doing migration using `mv` but then it cannot be resumed, so I switched to rsync using the following command: `rsync -avzh --remove-source-files --progress /mnt/user/isos/ /mnt/remotes/UNRAID2_isos/` After this rsync migration completes, I intend to run this to find and remove the empty dirs left behind (I never got this far): `find /mnt/user/isos/ -type d -empty -delete` I noticed that it would fill up the 2TB cache drive, and everything would slow right down while the mover on UNRAID2 started emptying the cache, and the transfer continued, and the whole process would stall while the mover frantically emptied the cache while more data was pushed. So, I figured that I would simply wait for the mover to move everything from the cache drive to array, on UNRAID2 change the `iso` share options to write directly to array without cache involved, and resume the move/migration again... Before: After: I figured it would be slower writing to the array disks at ~250MBs rather than NVME speed far above that, but I could leave it and let it run until its done, and the mover would not be required. I figured the source is the array disks on UNRAID1, so in the end its not much different in overall speed. Now when I started doing the migration without cache/mover involved, I've noticed that the transfer will start, about 3 or 4 files will be moved over, and then it would just stall. System Stats from UNRAID2: You can see here, the transfer would begin, it would copy some files, with some breaks, then stall and wait. After doing this a few times, I rebooted both systems multiple times, cold booted both systems multiple times, and rechecked all settings. Nothing seems odd. After this, I tried reconfiguring the `isos` share on UNRAID2 to use cache again, and that seemed to start working, but slower. So that seemed to work, but then the same problem would eventually occur where the cache would fill and speeds would slow down while the mover does its job again. So I stopped the transfer, ran the mover, and waited for all files to be moved. After this I reconfigured the `isos` share back to not use cache, and the same problem appeared (UNRAID2): I'm really at quite at a loss as to what is happening here. Can anyone help?
-
I'm sure I might not be the only person that wants a Miniforum MS-01 icon. Thanks anyone that can do this.


-
vm1-win10-data0.xml Here is the xml for the VM in question. I did try migrating the "/etc/libvirt/qemu/nvram/b154af59-fe03-1020-2c56-1a5f76d10671_VARS-pure-efi.fd" file on line 31, but still no joy. It's like this VM just doesn't want to be moved for some reason. I know it "works" because the Windows Recovery runs after a few reboots, but the actual OS refuses, just black screen forever. Oh, also I didn't use TPM BIOS just the normal OVMF.
-
I looked into the error and and this worked: root@unraid:~# virsh undefine --nvram "VM1-WIN10-Q35-OVMF" Domain 'VM1-WIN10-Q35-OVMF' has been undefined Still very confused about trying to get this particular Win10 VM running...
-
If you mean the domain dir on the cache disk, no there is nothing there. I have even deleted the vdisk and the VM refuses to go. That also doesn't seem to work, I get a message: root@unraid2:~# virsh undefine VM1-WIN10-Q35-OVMF error: Failed to undefine domain 'VM1-WIN10-Q35-OVMF' error: Requested operation is not valid: cannot undefine domain with nvram
-
This continues to be a confusing issue, especially as I have now migrated other Windows VMs between the same systems without issues. THis particular VM just seems to refuse to start on the new system. Also, it seems that I cannot delete THIS particular VM now, but I can create/delete other VMs. When I try to delete it, I just see the spinning arrows to infinity. I've rebooted enough times, cleared browser cookies cache, tried a different browser. If anyone has even an idea, I'd really appreciate anything...
-
I still haven't got this VM to work, and I've been trying everytrhing I can find. Is it possibly something to do with TPM, why it won't start? Does anyone have advice on how to copy TPM from another Unraid? Would really appreciate any ideas.
-
Hi, I have a pretty generic Win10 VM that I have migrated over to a different unraid server, and it refuses to start under the same generic settings. THe VM works fine on the old system (AMD Ryzen) but on the new system (Intel 13900H) there is no dice at all. After a few tries the Windows Startup Repair runs though, so it seems the VM is "booting" but starting actual Windows doesn't work. Interestingly, ANOTHER VM does boot, a similar Windows 10 generic VM (Migrated from AMD Ryzen system to same Intel system) with Virtual GPU etc, and that seems to be fine. I'm at a loss investigating on what might be the problem... Does anyone have an idea?
-
Hi, This is a post to notify I'm VERY soon (in the next few weeks) selling major parts from my homelab and main 2 Unraid systems (In my Signature). Mods please, I ask that I can list here for visibility and put more topics later. Mods please let me know if I'm doing this wrong, please don't delete my topic. Selling is due to family emergency requiring me to internationally relocate to help family. So... I'm looking for a good home for these items. Everything is functioning in what I would consider great condition, no issues, once I've taken everything apart I'll post pics. I can try and ship if it is worth it, but pickup is preferred, from area of The Hague/Delft/Rotterdam in Netherlands. Buyer would pay shipping. Items soon to be for sale: [4Sale] 3x APC 1000XL UPS, each with APC AP9631 Network Interface Card and original APC RBC7 Battery (Installed 2022-09-20). 200€ each [4Sale] Cooler Master Stacker 810 case, original from 2006, unmodified in excellent condition, all fans, with all accessories and original box. 80€ [4Sale] Rackmountable 4U Black Case, space for 6x 5.25" bays & 4x 2.5" bays, all fans, not sure the exact model but will find and provide pics, no box. 50€ [4Sale] CoolerMaster MasterBox Lite 5 Black Case with window, unused, no box. 40€ [4Sale] 2x IcyBox RAID Caddy 5.25" to 5x 3.5" (looks like this) with SATA cables and all parts. 40€ each [4Sale] 2x SATA SAS HDD Cage 5.25" to 5x 3.5" (looks like this) with SATA cables, SATA Power cables and all parts like drive fitters. 20€ each [4Sale] AMD Ryzen 3600 CPU, excellent condition with cooler. 60€ I will possibly have more for sale, I will add if relevant items.
-
Also, does switching between parity write methods require rebooting, or can I test this by just adjusting the setting?
-
I've been considering turning this on for a while. Just asking, is there a timeline or idea for when the auto option will be implemented?
-
Thanks, I totally forgot about docker interactive console. I'm trying to resolve a problem where I think the webserver files are wrong permissions. In particular I think the followind dirs: - /var/www/html/ - /var/www/html/config - /var/www/html/data Do you know the correct permissions and owners for these dirs?
-
Thanks, that helps with docker exec. However, I still cannot su within the container console, and its annoying because my container has stopped working and I have no su/sudo access. How can I get the root password?
-
Hi, I've been trying to get this to work for some time and I'm unable. When I run the command, I get: Console has to be executed with the user that owns the file config/config.php Current user id: 33 Owner id of config.php: 99 I'm trying to get cron running using the mentioned 2nd method. When I check the /etc/passwd file, there is no user 99. Any ideas? Also, whenever I try to su within the container, I get a password prompt, but what is the password? Additionally, when I try to sudo I get an error that sudo is not found. Any help would be appreciated?
-
I know this is an old thread, but nothing here worked for me. What worked for me on unraid 6.12.3: Check nginx processes (should return process list): netstat -tulpn | grep nginx netstat should return something like (show nginx running on 80 and 443): Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 512 0 192.168.22.18:80 0.0.0.0:* LISTEN 8803/nginx: master tcp 0 0 127.0.0.1:443 0.0.0.0:* LISTEN 8803/nginx: master tcp 0 0 127.0.0.1:80 0.0.0.0:* LISTEN 8803/nginx: master kill nginx proxesses (actually is kill process on 80 and 443): sudo fuser -k 80/tcp sudo fuser -k 443/tcp Check nginx processes again (should be blank): netstat -tulpn | grep nginx start nginx processes: /etc/rc.d/rc.nginx start Maybe this helps someone.
-
To everyone responding in this thread, READ THE THREAD, all of it. Read the instructions I left and the responses. Read the linked Reddit post. The latest unraid 6.12.x DOES NOT REQUIRE THE CUSTOM BIOS in the first few comments. I left an updated summary just a little bit back, that definitely works on both my systems. A few extra pointers: -make sure your VM works without REBAR enabled first, mine did. -make sure to use the unraid VM REBAR bios, without checking, ita not rhe SeaBIOS, the other one. Make sure to use the UEFI-enabled VM BIOS. -make sure you are passing through both the gfx card AND the cards sound device. I would suggest no other audio devices in the VM. -read other threads about passthrough FIRST and get that working, this thread isn't diagnosing basic passthrough issues like code 43. -these instructions REQUIRE manual XML editing, if you then go to update the VM in GUI mode, the custom REQUIRED XML edits will be lost. Be aware.
-
Some responses I've seen so far: # zpool import /dev/sda cannot import '/dev/sda': no such pool available # zpool import no pools available to import # zfs mount sys_sync2 /mnt/disks/sys_sync2 # zfs list NAME USED AVAIL REFER MOUNTPOINT sys_sync 14.4T 128M 14.4T /mnt/disks/sys_sync1 sys_sync2 12.5T 1.95T 12.5T /mnt/disks/sys_sync2 I also tried: # zfs mount sys_sync but this appears to hang and do nothing.
-
Hi all, apparently its my luck that this happens a day before I go travelling. I have 2 new 16TB Western Digital "My Book" that I have connected to my unraid. I decided about a week ago to format them both with ZFS (To try out ZFS), so I did and filled them with data. Today, I shut down both servers and moved the disks to the second server, so I could back them up. Upon starting up, the first disk will not mount, but the second appears to mount fine, both were formatted the same way without errors. Checking the disk log I see this: text error warn system array login Jul 29 23:13:14 soundwave kernel: sd 1:0:0:0: [sda] Very big device. Trying to use READ CAPACITY(16). Jul 29 23:13:14 soundwave kernel: sd 1:0:0:0: [sda] 31251759104 512-byte logical blocks: (16.0 TB/14.6 TiB) Jul 29 23:13:14 soundwave kernel: sd 1:0:0:0: [sda] 4096-byte physical blocks Jul 29 23:13:14 soundwave kernel: sd 1:0:0:0: [sda] Write Protect is off Jul 29 23:13:14 soundwave kernel: sd 1:0:0:0: [sda] Mode Sense: 47 00 10 08 Jul 29 23:13:14 soundwave kernel: sd 1:0:0:0: [sda] No Caching mode page found Jul 29 23:13:14 soundwave kernel: sd 1:0:0:0: [sda] Assuming drive cache: write through Jul 29 23:13:14 soundwave kernel: sda: sda1 Jul 29 23:13:14 soundwave kernel: sd 1:0:0:0: [sda] Attached SCSI disk Jul 29 23:13:57 soundwave emhttpd: WD_My_Book_25ED_32504A353237474A-0:0 (sda) 512 31251759104 Jul 29 23:13:57 soundwave emhttpd: read SMART /dev/sda Jul 29 23:14:03 soundwave unassigned.devices: Disk with ID 'WD_My_Book_25ED_32504A353237474A-0:0 (sda)' is not set to auto mount. Jul 29 23:29:00 soundwave unassigned.devices: Mounting partition 'sda1' at mountpoint '/mnt/disks/sys_sync2'... Jul 29 23:29:03 soundwave unassigned.devices: Successfully mounted 'sda1' on '/mnt/disks/sys_sync2'. Jul 29 23:29:03 soundwave unassigned.devices: Device '/dev/sda1' is not set to be shared. Jul 29 23:30:01 soundwave unassigned.devices: Unmounting partition 'sda1' at mountpoint '/mnt/disks/sys_sync2'... Jul 29 23:30:13 soundwave unassigned.devices: Successfully unmounted 'sda1' Jul 29 23:38:38 soundwave kernel: sd 1:0:0:0: [sda] Spinning up disk... Jul 29 23:38:57 soundwave kernel: sd 1:0:0:0: [sda] Very big device. Trying to use READ CAPACITY(16). Jul 29 23:38:57 soundwave kernel: sd 1:0:0:0: [sda] 31251759104 512-byte logical blocks: (16.0 TB/14.6 TiB) Jul 29 23:38:57 soundwave kernel: sd 1:0:0:0: [sda] 4096-byte physical blocks Jul 29 23:38:57 soundwave kernel: sd 1:0:0:0: [sda] Write Protect is off Jul 29 23:38:57 soundwave kernel: sd 1:0:0:0: [sda] Mode Sense: 47 00 10 08 Jul 29 23:38:57 soundwave kernel: sd 1:0:0:0: [sda] No Caching mode page found Jul 29 23:38:57 soundwave kernel: sd 1:0:0:0: [sda] Assuming drive cache: write through Jul 29 23:38:57 soundwave kernel: sda: sda1 Jul 29 23:38:57 soundwave kernel: sd 1:0:0:0: [sda] Attached SCSI disk Jul 29 23:38:58 soundwave unassigned.devices: Disk with ID 'WD_My_Book_25ED_3348475A58554C4E-0:0 (sda)' is not set to auto mount. Jul 29 23:39:01 soundwave emhttpd: read SMART /dev/sda Jul 29 23:40:04 soundwave unassigned.devices: Mounting partition 'sda1' at mountpoint '/mnt/disks/sys_sync1'... Jul 29 23:40:06 soundwave unassigned.devices: Mount of 'sda1' failed: 'Cannot determine Pool Name of '/dev/sda1'' Jul 29 23:40:30 soundwave unassigned.devices: Mounting partition 'sda1' at mountpoint '/mnt/disks/sys_sync1'... Jul 29 23:40:33 soundwave unassigned.devices: Mount of 'sda1' failed: 'Cannot determine Pool Name of '/dev/sda1'' Jul 29 23:40:43 soundwave unassigned.devices: Mounting partition 'sda1' at mountpoint '/mnt/disks/sys_sync'... Jul 29 23:40:45 soundwave unassigned.devices: Mount of 'sda1' failed: 'Cannot determine Pool Name of '/dev/sda1'' Jul 29 23:41:32 soundwave unassigned.devices: Mounting partition 'sda1' at mountpoint '/mnt/disks/sys_sync'... Jul 29 23:41:35 soundwave unassigned.devices: Mount of 'sda1' failed: 'Cannot determine Pool Name of '/dev/sda1'' Jul 29 23:42:49 soundwave unassigned.devices: Mounting partition 'sda1' at mountpoint '/mnt/disks/sys_sync'... Jul 29 23:42:52 soundwave unassigned.devices: Mount of 'sda1' failed: 'Cannot determine Pool Name of '/dev/sda1'' Jul 29 23:43:08 soundwave unassigned.devices: Mounting partition 'sda1' at mountpoint '/mnt/disks/sys_sync1'... Jul 29 23:43:11 soundwave unassigned.devices: Mount of 'sda1' failed: 'Cannot determine Pool Name of '/dev/sda1'' Jul 29 23:43:22 soundwave ool www[19861]: /usr/local/emhttp/plugins/unassigned.devices/scripts/rc.unassigned 'detach' 'sda' 'true' Jul 29 23:43:24 soundwave unassigned.devices: Device 'sda' has been detached. Jul 29 23:45:44 soundwave kernel: sd 1:0:0:0: [sda] Very big device. Trying to use READ CAPACITY(16). Jul 29 23:45:44 soundwave kernel: sd 1:0:0:0: [sda] 31251759104 512-byte logical blocks: (16.0 TB/14.6 TiB) Jul 29 23:45:44 soundwave kernel: sd 1:0:0:0: [sda] 4096-byte physical blocks Jul 29 23:45:44 soundwave kernel: sd 1:0:0:0: [sda] Write Protect is off Jul 29 23:45:44 soundwave kernel: sd 1:0:0:0: [sda] Mode Sense: 47 00 10 08 Jul 29 23:45:44 soundwave kernel: sd 1:0:0:0: [sda] No Caching mode page found Jul 29 23:45:44 soundwave kernel: sd 1:0:0:0: [sda] Assuming drive cache: write through Jul 29 23:45:44 soundwave kernel: sda: sda1 Jul 29 23:45:44 soundwave kernel: sd 1:0:0:0: [sda] Attached SCSI disk Jul 29 23:45:45 soundwave unassigned.devices: Mounting partition 'sda1' at mountpoint '/mnt/disks/sys_sync1'... Jul 29 23:45:48 soundwave unassigned.devices: Mount of 'sda1' failed: 'Cannot determine Pool Name of '/dev/sda1'' Jul 29 23:45:57 soundwave unassigned.devices: Mounting partition 'sda1' at mountpoint '/mnt/disks/sys_sync1'... Jul 29 23:45:59 soundwave unassigned.devices: Mount of 'sda1' failed: 'Cannot determine Pool Name of '/dev/sda1'' Jul 29 23:46:04 soundwave unassigned.devices: Mounting partition 'sda1' at mountpoint '/mnt/disks/sys_sync1'... Jul 29 23:46:07 soundwave unassigned.devices: Mount of 'sda1' failed: 'Cannot determine Pool Name of '/dev/sda1'' Jul 29 23:51:02 soundwave unassigned.devices: Mounting partition 'sda1' at mountpoint '/mnt/disks/sys_sync1'... Jul 29 23:51:04 soundwave unassigned.devices: Mount of 'sda1' failed: 'Cannot determine Pool Name of '/dev/sda1'' Jul 29 23:51:34 soundwave unassigned.devices: Mounting partition 'sda1' at mountpoint '/mnt/disks/sys_sync1'... Jul 29 23:51:37 soundwave unassigned.devices: Mount of 'sda1' failed: 'Cannot determine Pool Name of '/dev/sda1'' Jul 29 23:52:02 soundwave unassigned.devices: Mounting partition 'sda1' at mountpoint '/mnt/disks/sys_sync1'... Jul 29 23:52:05 soundwave unassigned.devices: Mount of 'sda1' failed: 'Cannot determine Pool Name of '/dev/sda1'' Jul 29 23:57:53 soundwave unassigned.devices: Mounting partition 'sda1' at mountpoint '/mnt/disks/sys_sync1'... Jul 29 23:57:56 soundwave unassigned.devices: Mount of 'sda1' failed: 'Cannot determine Pool Name of '/dev/sda1'' Jul 30 00:00:49 soundwave unassigned.devices: Mounting partition 'sda1' at mountpoint '/mnt/disks/sys_sync1'... Jul 30 00:00:52 soundwave unassigned.devices: Mount of 'sda1' failed: 'Cannot determine Pool Name of '/dev/sda1'' Jul 30 00:01:20 soundwave unassigned.devices: Mounting partition 'sda1' at mountpoint '/mnt/disks/sys_sync1'... Jul 30 00:01:22 soundwave unassigned.devices: Mount of 'sda1' failed: 'Cannot determine Pool Name of '/dev/sda1'' ** Press ANY KEY to close this window ** In the UI, I can see the disk mount button but it just fails every time I try to mount it. I can't see any other obvious errors, I tried detatching and disconnecting both disks, then reconnecting and same scenario (disk 1 fails to mount). This is the fist time I'm using ZFS, and I'm not sure where to start. I can't find any other details in the Ui, there are no SMART errors showing, its a new disk a week old. Can anyone help?

-
Hi all, I'm looking for some advice or experiences with running Unraid on QNAP/Synology/Other dedicated hardware. Hopefully someone out there can provide some general or specific recommendations for this? I'm a pretty happy user of unraid, and I'm looking to expand with a dedicated NAS system for array network storage. At the moment, I have 2 Unraid systems on AMD Ryzen that I use daily, but I'm looking to reduce my electricity usage by moving storage and essential storage to a centralised NAS unit, and leave my primary/secondary as compute nodes that I can switch off when not in use. The idea is to be able to offload tasks from my more hungry systems and make a NAS unit my always-on 24/7 system. I've been looking into specs and videos of QNAP and Synology NAS boxes, and I have been reading that Unraid runs on these without too much difficulty, but I've read mixed reports about how much. In a perfect world I'd love to get something like a Synology DS2422+ with 12 bays and just expand as I go, but I'm not sure if this will run Unraid at all. Realistically, I've tried to break it down to a definite set of requirements that I think will work for my background needs/workloads (NAS, plex, sonarr/radarr, wordpress, nextcloud). My requirements: - 8+ 3.5" bays for array - m.2 NVME port(s) - 10Gbit Networking - Preferably under 1k euros/dollars for unit - Preferably new Nice to have: - GPU for Plex hardware acceleration - Enough oomph for VMs Units I've looked at: - Synology DS1821+ (8 bay, m.2 slots) - QNAP TS-832PX-4G (8 bay, 10Gbit onboard) - Synology DS2422+ (12 bay
-
Just upgraded both my main production systems from 6.11.5 direct to 6.12.1. Everything works great, I can't complain. Well done guys, another perfect release (for me at least). Main specs, as a snapshot in case this changes: UnRAID1 (6.12.1 Pro) Primary: Ryzen 9 5950x, ASUS TUF GAMING X570-PLUS (WI-FI), 128GB (4x32GB) Kingston Unbuffered ECC PC4-25600 DDR4-3200, Gigabyte RTX3090 Turbo 24G UnRAID2 (6.12.1 Pro) Backup: Ryzen 5 3600, ASUS TUF GAMING X570-PRO (WI-FI), 128GB (4x32GB) Micron Unbuffered ECC PC4-25600 DDR4-3200, EVGA GTX1080Ti FTW3 GAMING
-
@Skitals and @jonathanselye, I just upgraded from 6.11.5 direct to 6.12.1. I can confirm that everything works on the Unraid 6.12.1 stock kernel 6.1.34. My daily VM has ReBar enabled. I can report any issues encountered, but everything seems to work as of right now.
-
You will need to determine that yourself, using the provided scales in the script they are written out, but essentially you need to pick one that your card memory fits in (and is supported). You haven't stated if your Arc A770 is 8GB or 16GB so I would suggest starting there for a hint. You can also try listing the compatible Bar sizes with with this command: lspci -vvvs {YOUR_GPU_ID_HERE} | grep "BAR" You should see something like this: root@unraid1:~# lspci -vvvs 0b:00.0 | grep "BAR" Capabilities: [bb0 v1] Physical Resizable BAR BAR 0: current size: 16MB, supported: 16MB BAR 1: current size: 32GB, supported: 64MB 128MB 256MB 512MB 1GB 2GB 4GB 8GB 16GB 32GB BAR 3: current size: 32MB, supported: 32MB I might be wrong, but I don't think you need to unbind it. That is what the script is for, I believe, running at Array Startup. I'm not sure what you mean, if you have </devices> then you will certainly have <devices> somewhere, or you've got bigger problems. Follow the instructions, and read your XML config carefully, line by line. Read upwards from each line beginning to find the opening <devices>. Doing a quick google search led to this reddit post which indicates this device is an RGB controller on the Arc card. This is nothing to do with virtio drivers, its something on your card. Depending on the manufacturer, download their drivers or accompanying config application for their RGB control.













