

civic95man
-
Posts
224 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Report Comments posted by civic95man
-
-
9 hours ago, TechGeek01 said:
For reference, X10 is based on the ASPEED AST 2400 controller. Seems like this same latest driver is required for almost all X10 motherboards, so if you could confirm that a Supermicro X10 board with IPMI firmware 3.80 or later can successfully boot into GUI mode, that would be amazing.
That's good to know, and good to point out. I don't boot into the GUI mode but it is a nice option if required so I'd like to have that option. I run a X10SRA-F and remember seeing a note that a new VGA driver was required when updating the BMC to 3.80 or later (I'm on 3.88 now)
-
 1
1
-
-
Try recreating the flash drive
-
4 minutes ago, bonienl said:
While doing the implementation for Unraid, I ran into multiple
issueslimitations of Docker. I don't know if they have these all documented.Okay, good to know.
4 minutes ago, bonienl said:If your router allows adding a "secondary address" to its LAN interface, then you are good to go.
Or perhaps your router supports multiple LAN ports, each with their own network assignment.
I'll have to look at the options that my router supports and proceed from there.
6 minutes ago, bonienl said:Remember that more complex network setups on Unraid does require network equipment (your switch / router) to support that.
Yeah, I'm seeing that as I proceed, just not only with networks but hardware as well. Its definately a learning curve and I'm trying to build things up as funds allow. Looks like my network will be the next to receive an upgrade.
Thanks @bonienl
-
10 hours ago, bonienl said:
Your problem happens because both eth0 (br0) and eth1 (br1) use the same IPv6 subnet and gateway.
10 hours ago, bonienl said:See if my answer above applies to your situation too.
I believe this is my case as well. I was simply trying to dedicate eth1 to my plex container and keep eth0 (a member of br0) for everything else, including unraid.
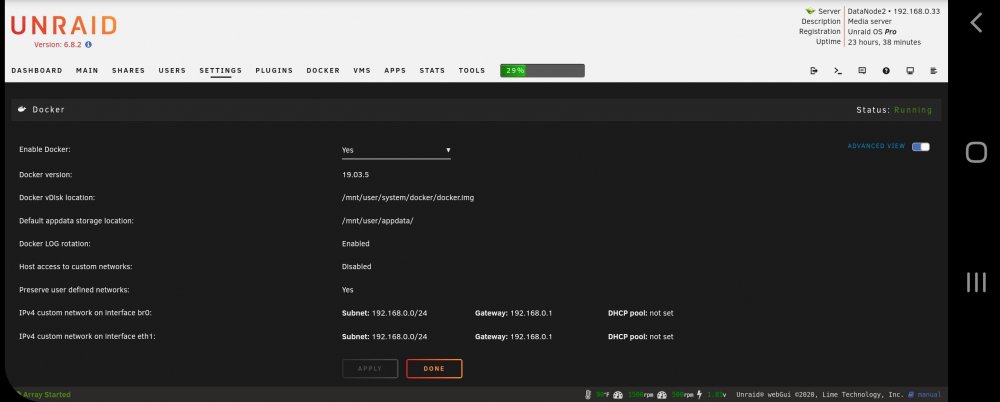
As it shows, both br0 and eth1 occupy the same subnet and gateway. Thats a bummer. Now is this just common knowledge passed from person to person, or is it documented somewhere. I've been searching through the docker forum/manual for any information but came up empty.
So it seems my only solution would be to change the subnet for eth1 (dont think my router would like that), or switch eth1 to IPv6. Is this correct?
Thanks!
-
I noticed this same issue (custom:br1/custom:eth1) not showing up in the drop down under network in my container. I assumed I was making a stupid mistake but maybe its something else. I can post diagnostics later if its relevant to this case (don't want to steal the thread), otherwise I was going to open a topic under docker.
-
Thats funny because I swear 6.7.2 had Thunderbolt support in some way. At that time, I was trying to use a 7th gen intel NUC with an external Thunderbolt to PCIe enclosure (for an HBA card). With the stock unraid kernel/build it sorta worked (initially worked) but it proved to be too unstable in the long run. I've since gone in the opposite direction and built a full server. I assumed the thunderbolt to PCIe function required a driver of some sort to manage/enable but maybe it was transparent to the OS. I never truly found an answer to that on google. At the time, I never saw any thunderbolt modules loading and just assumed it was part of the kernel.
-
my linux-fu is lacking but I *believe* you could add an "&" to the end of your command in the go file which should send the wget to the background and allow the rest of the system to come up.
wget --user=user--password='pw' ftp://adr:port/file -O /root/keyfile &
-
1
-
-
This release seems to have fixed my issue with:
QuoteFixed md/unraid crash resulting when bringing cleared array device online (bug introduced in multi-stream support)
added my 2 disks without issue!
Thanks for the quick fix as always! Also, thanks for explaining the reason/cause of the failure. I always find it interesting.
-
 1
1
-
-
@limetech, all seems good now. Much appreciated! I take it that reflink=1 is the new default for xfs?
-
2
-
-
7 hours ago, johnnie.black said:
It wasn't used on the command but it was used for the format, so possibly it's the default now
Interesting... Is this an option to enable as default at compile time? Its my understanding that reflink is similar to cow on btrfs? Is this accurate?
Thanks for testing the previous versions. I guess that helps put my mind at ease.
Correct, the xfs free space doesn't directly affect this bug report. I was thinking of @je82's original post mentioning this issue along side the preclear/format issue.
-
21 minutes ago, limetech said:
Where do you see 'reflink=1'?
I don't. I was questioning if it was set. I already removed the 2 drives I had formatted otherwise I would have checked for myself. This was merely a suggested cause of the increased "used" space after formatting, and a quick google search pulled up this: https://serverfault.com/questions/983907/newly-created-xfs-filesystem-shows-78-gb-used
I guess I'm nervous about formatting and beginning to fill up a drive that *possibly* would become invalid in the future.
-
Regarding the additional used space after the format (in my case, after rebooting the server after the initial format resulted in a freeze):
I found mention of
reflink=1during mkfs.xfs time resulting in the extra metadata creation/reservation (such as 78G for a 12TB drive), whereas
reflink=0resulted in the standard 1GB per TB we were used to. @johnnie.black, do you still have your cleared xfs drive and if so, could you format it and see what if reflink=1 was used? Just an idea as to solve the mystery of the increase in initial "used" space after format.
Edit: Would this mean that any disks formatted with this option (i.e. in 6.8 series) would be incompatible with older versions of unraid (6.7.2 and older)?
-
2 hours ago, bonienl said:
Preclearing is not needed
As stated, formatting on an already pre-cleared drive works (I tried formatting after my server came back up after the crash).
-
9 minutes ago, je82 said:
The other guy who posted in this thread that this happened to used XFS but not encrypted as far as i know so probably no
Correct, array is not encrypted.
Original array was created with 6.7 series.
22 minutes ago, je82 said:Don't know, the two times it happened for me was:
1. I have an already working array, with 2x cache btrfs drives and 2x parity drives.
2. I add a totally new drive
3. Start array, preclear starts..
4. Click format, that's when it starts to crash. Webgui will respond in the beginning but the longer it goes the less things are responding and it seems to be stuck formating, the format never completes it just says "Formating...".
5. You eventually try to do a graceful shutdown, it wont work.
I used the exact process when this happened, only I have 1 parity and I was adding 2 drives to the array at the same time. And I had the exact same result
-
I can enable logging to flash and *try* adding the drive to the pool again this evening (preclearing and formatting) to see what happens but I'm hesitant since I just got my parity rebuilt. I'm actually leaning towards finding an old 1TB drive to test with so I'm not waiting to preclear an entire 4TB drive just for testing. Any thoughts?
-
2 minutes ago, bonienl said:
With or without encryption?
Sorry forgot to mention that - without encryption.
I'm not hurting for storage space right now so I can remove those 2 drives and start the process over with logging to get some diagnostics. I'm at work now so it'll have to wait until this evening
-
Its funny that you noticed this behavior as I had the same issue happen to me last night. I had just received 2 new drives and threw them into the server and started a preclear on both. After the preclear finished, I went to format the two drives and all hell broke loose.
I first noticed that the format operation was taking too long, but walked away and came back maybe 15 minutes later and saw it was still formatting (according the the GUI via web). tried refreshing the page and the server wasn't responding. I then noticed that some open shares on another computer disconnected. Check the console (it runs semi-headless) and saw a massive amount of text flying through the screen - too much/fast to read any of it.
I rebooted the server, and has since formatted the drives and they are part of the pool.... but I remember the "used" capacity after formatting being more than usual as well (~4gb for a 4TB drive if i remember right, dont remember what these 2 show now).
I'm running RC5 right now but have no diagnostics [yet] as i thought it was possibly a hardware failure (lost some sleep over this) so didn't think to grab anything. I just wanted to throw my hat in and say its not just you



6.9.0/6.9.1 - Kernel Panic due to netfilter (nf_nat_setup_info) - Docker Static IP (macvlan)
in Stable Releases
Posted
I'm not sure how true this is, but I was under the impression that it was broadcast traffic, in conjunction with static IPs that was causing macvlan to s*** the bed and cause kernel panics. Now I'm not sure if this is true with every vendor, but Ubiquiti switches/routers do not route broadcast packets between networks (so I was told/read), which was the idea behind creating vlans for docker containers with static IPs.
I also think it was thrown out there that certain network adapters may be more prone to this than others.
This is a very good point since it could be an external device on the network that is hammering docker and therefore the macvlan interface, which isn't present in a "test lab".
Just my $0.02