




faulty_lamp
Members
-
Joined
-
Last visited
-
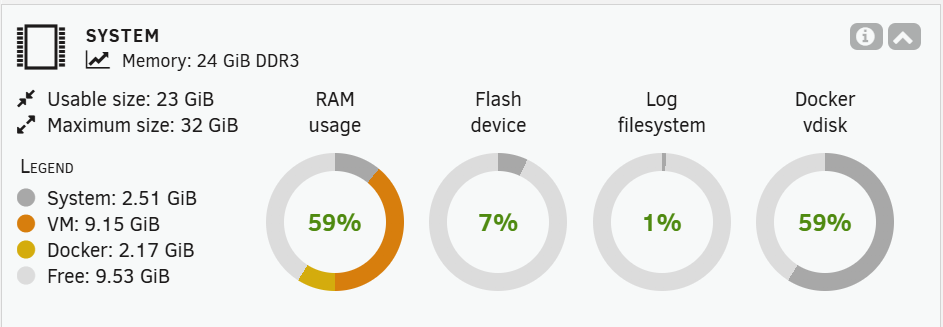
Over the past week or so I've started having trouble accessing the unraid UI. Today I noticed that some containers were also unresponsive whenever trying to connect to their UI. Things seem to somewhat start working again upon reboot. However, some containers are still having issues such as my unifi controller which is now reporting space errors. "2025-10-11 10:08:21,315 main ERROR Unable to create file logs/server.log java.io.IOException: No space left on device" I've checked the space in my docker image and it doesn't seem to be full. root@Tower:~# df -h /var/lib/docker/ Filesystem Size Used Avail Use% Mounted on /dev/loop2 60G 34G 24G 59% /var/lib/docker I've attached my latest diagnostics. Any suggestions on what may be causing this? tower-diagnostics-20251011-1007.zip
-
I've backed the drive up, but have not formatted yet. Went ahead and started memtest and it does look like there are some errors already. I'm assuming I'll just need to remove all memory sticks and place one at a time and test again to see which one has errors? After removing the erroring stick should I still format the drive?
-
Actually, now it looks like the cache is mounted as read-only (Drive mounted read-only or completely full). The drive is less than 50% full. I've attached the newest diagnostics, is there anything in that or would the next step be to run a memtest? tower-diagnostics-20231024-1150.zip
-
That worked, thank you!
-
My cache drive became unmountable overnight, showing Unmountable: Unsupported or no file system. I tried rebooting but that didn't make a difference. Following the manual I was going to try to scrub the drive as it is BTRFS but it says Scrub is only available when array is Started even though the array is started. Any thoughts on the next steps that I should try to remount the cache drive? I've attached my most recent diagnostics. tower-diagnostics-20231024-1017.zip
-
The log window shows the following when trying to install it. Oct 2 17:43:19 Tower root: plugin: running: anonymous Oct 2 17:43:19 Tower root: plugin: checking: /boot/config/plugins/appdata.backup/appdata.backup-2023.09.27.tgz - SHA256 Oct 2 17:43:19 Tower root: plugin: skipping: /boot/config/plugins/appdata.backup/appdata.backup-2023.09.27.tgz already exists Oct 2 17:43:19 Tower root: plugin: running: anonymous Oct 2 17:43:19 Tower root: plugin: running: anonymous I also tried deleting that file and then reinstalling it and get the following. Oct 2 17:44:20 Tower root: plugin: running: anonymous Oct 2 17:44:20 Tower root: plugin: creating: /boot/config/plugins/appdata.backup/appdata.backup-2023.09.27.tgz - downloading from URL https://github.com/Commifreak/unraid-appdata.backup/releases/download/2023.09.27/appdata.backup-2023.09.27.tgz Oct 2 17:44:20 Tower root: plugin: checking: /boot/config/plugins/appdata.backup/appdata.backup-2023.09.27.tgz - SHA256 Oct 2 17:44:20 Tower root: plugin: running: anonymous Oct 2 17:44:20 Tower root: plugin: running: anonymous With both instances I still see the same error (plugin: run failed: '/bin/bash' returned 255) in the install window.
-
I don't recall what time I attempted, but here is a fresh diagnostics. I attempted to install it right before downloading these diagnostics at 6:03pm CST on 9/29. tower-diagnostics-20230929-1804.zip
-
6.12.3, I've been working through a few things before updating to 6.12.4. Here are the plugins that I have installed, as well as diagnostics. tower-diagnostics-20230928-2049.zip
-
Still seeing the same I think plugin: installing: appdata.backup.plg Executing hook script: pre_plugin_checks plugin: downloading: appdata.backup.plg ... done Executing hook script: pre_plugin_checks No cleanup of old plugin archive needed! Removing plugin files... Creating plugin files directory... Extracting plugin files... Checking cron. plugin: run failed: '/bin/bash' returned 255 Executing hook script: gui_search_post_hook.sh Executing hook script: post_plugin_checks
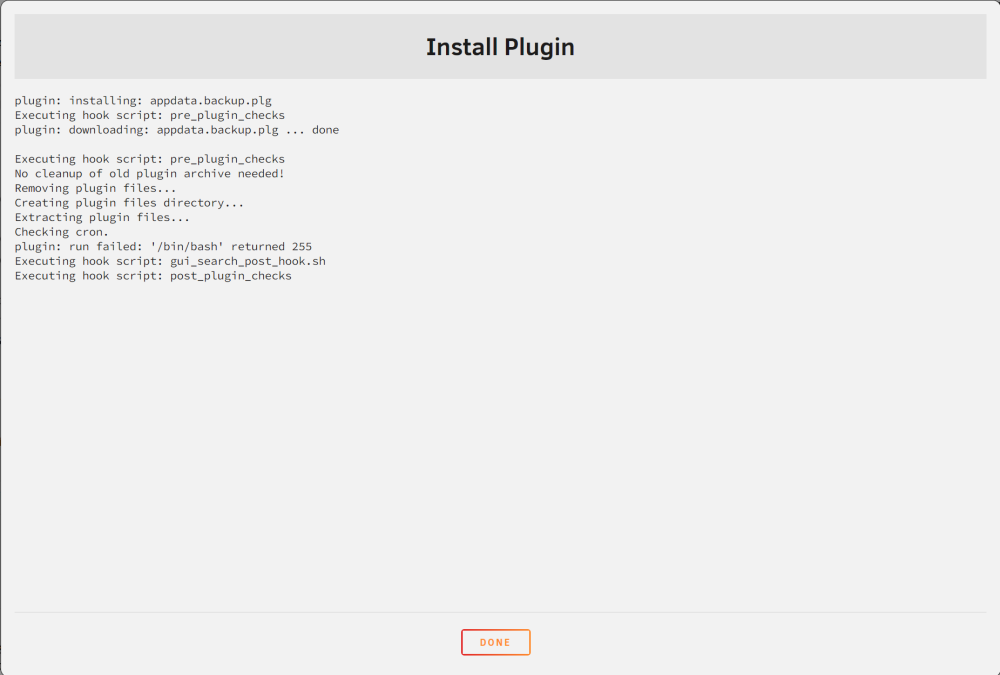
-
I have been trying to update to this plugin from the previous but can't seem to get it installed. When I attempt to install it I see the following error: plugin: installing: appdata.backup.plg Executing hook script: pre_plugin_checks plugin: downloading: appdata.backup.plg ... done Executing hook script: pre_plugin_checks No cleanup of old plugin archive needed! Removing plugin files... plugin: downloading: appdata.backup-2023.09.12.tgz ... done Extracting plugin files... Checking cron. plugin: run failed: '/bin/bash' returned 255 Executing hook script: gui_search_post_hook.sh Executing hook script: post_plugin_checks I've tried rebooting Unraid as well but always end up seeing the run failed '/bin/bash' error when attempting to install it. Any thoughts?
-
Unraid because unresponsive sometime overnight. I was unable to access the web ui or ping the machine. I physically shut the server down, but now I receive a boot device not found error. I am unable to see the flash drive in the bios, or boot menu. I was able to plug the flash drive into a windows machine and could see it, I also ran chkdisk on it but no errors were found. I've tried plugging the flash drive into a few different ports but that did not make a difference. Oddly enough, I can still use a keyboard with the dongle plugged into the same ports that I've tried the flash drive in. Am I able to plug the unraid flash drive into a different machine to see if it allows me to boot from it? I wasn't sure if the flash drive was linked specifically to this machine and if it would cause any problems if I attempted to boot from it on another machine. I'm just trying to rule out if this is an issue with the flash drive or the motherboard at this point.
-
The long test finally finished. I went ahead and ordered a drive to replace it but wanted to share the final diagnostics in case there was anything else that could be identified from the completed test. tower-diagnostics-20230902-0813.zip
-
The scrub of the cache showed 3 corrupted files, I've deleted those and it appears to be ok now. The long SMART test ran for ~24 hours but has been stuck at 100% for a few hours now. I've attached a new diagnostics output. tower-diagnostics-20230901-1051.zip
-
Hello, I was hoping to have someone take a look at my diagnostics to see what I need to do with a disk that entered an error state. I was running a parity check and around 70% complete when I received an alert that Disk 1 is in error state. I checked the smart error log and it shows 1 delayed ECC and 8 rereads/rewrites errors corrected, but no uncorrected errors. In addition, I have two disks that I was planning on removing after the parity check completed. Dev1 which is already unassigned, and Disk2 which will need to be cleared and removed. tower-diagnostics-20230831-0735.zip
-
That looks like that worked, thank you for all of the assistance!




