




Marc_G2
Members
-
Joined
-
Last visited
Everything posted by Marc_G2
-
Any Linux experts here? I suspect the problem with the Sleep plugin's disk activity checker is with this function. If so, it may be an easy fix to just modify the plugin file and then repackage it as a txz. HDD_activity() { result= if [[ $checkHDD == yes ]]; then [[ -f /dev/shm/2 ]] && cp -f /dev/shm/2 /dev/shm/1 || touch /dev/shm/1 awk '/(sd[a-z]*|nvme[0-9]n1) /{print $3,$6+$10}' /proc/diskstats >/dev/shm/2 for dev in ${array[@]}; do [[ $monitor -ne 2 ]] && active=$(sdspin /dev/$dev) || active= [[ $monitor -ne 1 ]] && diskio=($(grep -Pho "^$dev \K\d+" /dev/shm/1 /dev/shm/2)) || diskio= if [[ -n $active || ${diskio[0]} != ${diskio[1]} ]]; then result=1 break; fi done fi if [[ -n $result ]]; then log "Disk activity on going: $dev" echo $result fi }
-
You've confirmed disk activity detection specifically still works? Then I guess it still works some folks on version 6.12.X. So far there's about 5 people in this thread who's found it to be broken.
-
Disk activity detection is broken on 6.12 for everyone as far as I can tell. The dev has made no comment about when or if it will get fixed.
-
I changed the file system of my BX500 SSD to btrfs instead of ZFS. I then tested the performance by transferring a 50GB file. There were fluctuations in the transfer speed but it never completely halted like it did when was formatted as ZFS. The total transfer time was probably about cut in half. So I'm going to assume the issue has been mitigated. My advice to anyone else to only use drives with good sustained write performance if using ZFS. Though I haven't confirmed yet whether that would also fix the issue on my system.
-
Yeah reboots like that are usually either due to either power or overheating issues. If your psu is spec'd plenty high, then I would double check all your connections.
-
I'm writing to the SSD at only 100 MB/s. Under normal desktop usage, the BX500 write speed will drop to 40 MB/s when it runs out of cache (which is 48GB). It's not normal for it to completely halt. I have other SSDs so I'll try a different one. I'll also see if there's any difference between btrfs and zfs.
-
That doesn't explain why there's frequent pauses during large sequential writes. This write performance isn't normal for any SSD. Is it due to ZFS overhead?
-
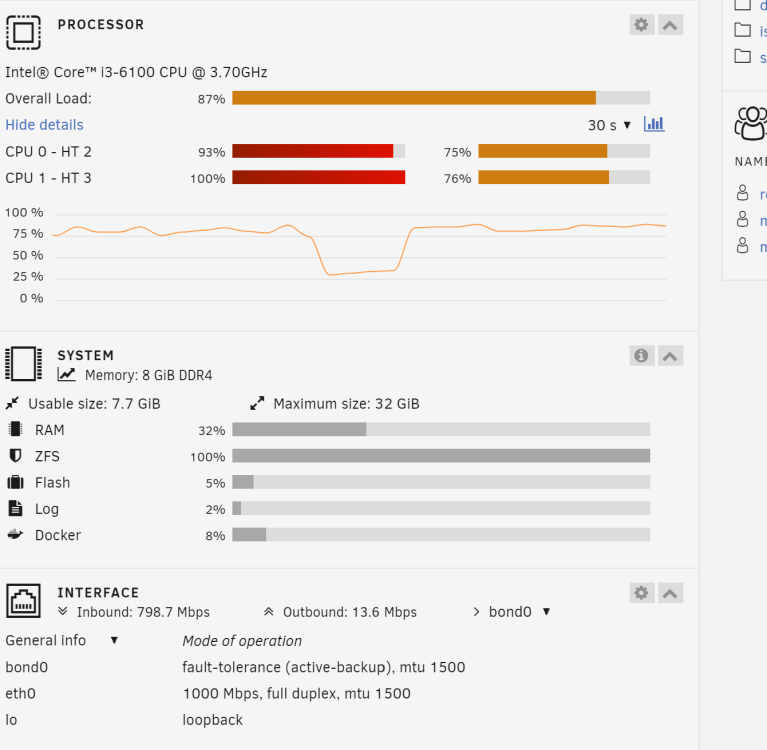
Is this what you're looking for? Interestingly when the system pauses, this graphs shows no cpu activity unlike the one on the dash
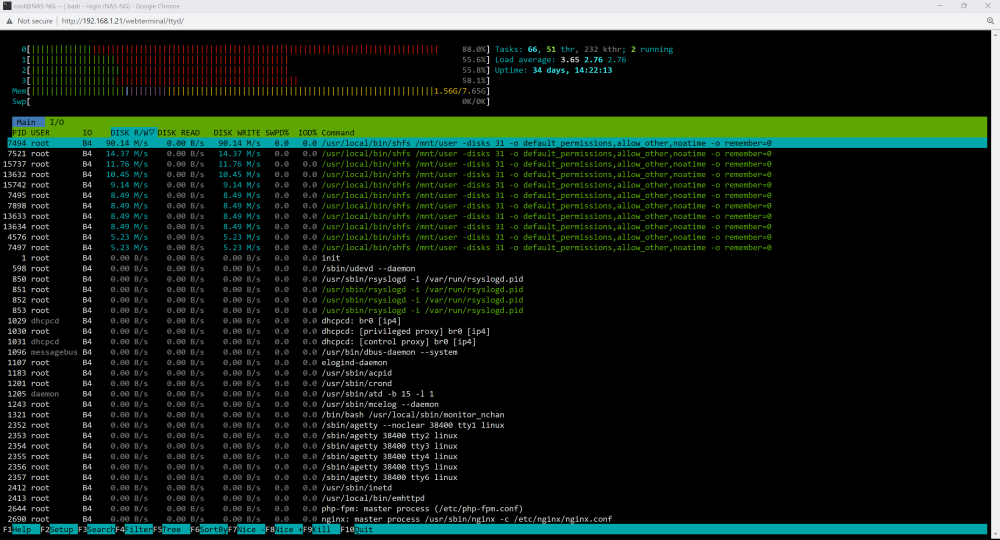
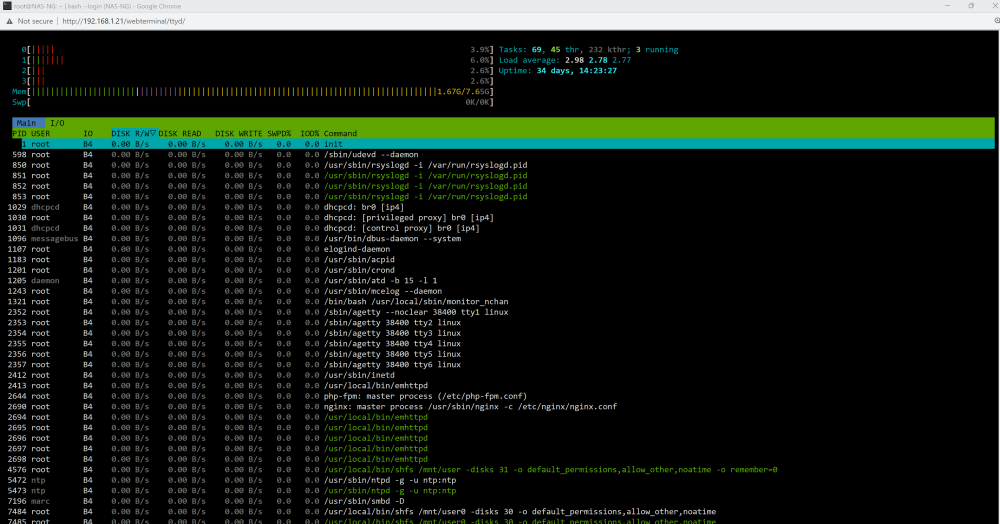
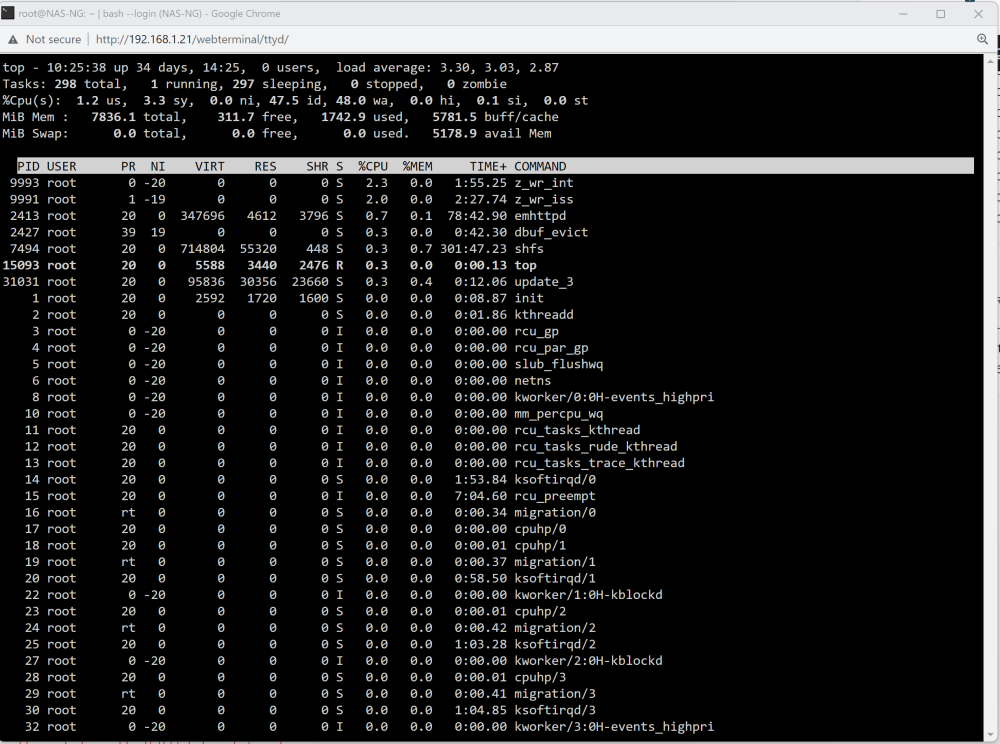
-
I'm not sure graph you're referring to. I did some more tests and found the issue only happens after around 25GB of continuous transfer. Here's a graph of the network activity (1 large file transfer). During those periods of zero activity, there's 100% cpu usage. So there appears to be some computations happening that's causing the delays
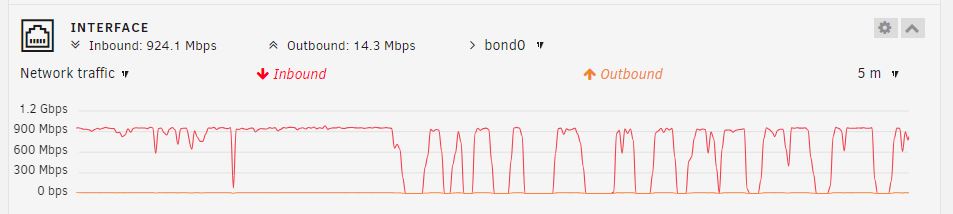
-
I've had same problem with it going to sleep as well. Did you confirm it to only be a problem when the parity check is running?
-
Dynamix Sleep's Array activity detection is completely broken for me right now. I set to monitor activity and counters. But my system keeps going to sleep during a parity scan. I'm not sure, but I think it may have started after updating to 16.12.2. Does anyone have any ideas??? Edit: just noticed the same issue being reported above.
-
Diagnostics attached in case that helps any nas-ng-diagnostics-20230808-1921.zip
-
I set up a new separate cache for one of my shares and went with ZFS. It's a single drive cache. Is relatively high CPU usage normal when writing to a ZFS cache? Apparently, my CPU can't keep up to the point where my large file transfers regularly halt for 5-10 seconds every 30 seconds or so. My other cache is setup as 2 drive BTRFS. I haven't had this issue with it.
-
I had to generate a new bot since I didn't realize none of my Telegram history would carry over after getting a new phone. If changing to a different bot, you have to manually delete the chatid file (located at flash\config\plugins\dynamix\telegram\chatid) in addition to inputting the new bot token. It won't work if you leave the old file in place. unRAID will automatically generate a new chatid when it sends a message.
-
The DAC was purely for outputting audio. So I didn't try ASIO drivers. I stopped running Windows VM's before I was ever able to find a solution. The only thing I can suggest is running your devices in exclusive mode to see if it helps any.
-
I have got an issue with the sleep plugin. If I set it to monitor disk status, it ends up monitoring my ssd cache (which never goes into a spun down state), and so it never goes to sleep. Is there a work around for this?
-
It turns out my issue was caused by something completely different. But I will keep that in mind going forward.
-
At the moment it's set to 35 min after disks are spun down. I'll create a new thread if I can't figure it out in the next day or so.
-
That's a good theory, but it looks like changing that setting didn't make a difference. I did recently change my default spin down time from 60 to 30 mins. But increasing it to 45 min didn't fix it either. For now I'll try a reboot to see if a setting isn't properly getting applied immediately or something. This was never a problem when prior to updating to 6.9.2. I only made a handful of small changes since that update. But I can't think of anything else that would cause this.
-
So I was hoping this plugin could help me determine what was pinging my Cache SSD every 30 minutes (almost on the dot) which was preventing my system from going to sleep. But sadly the plugin doesn't detect anything. Do you have any advice? I already posted on the Dynamix thread. nas-ng-diagnostics-20210428-1559.zip
-
So did it only work for you after you tried a third USB stick? Did you ever try booting in safe mode?
-
I've just encountered this for the first time today. Still trying to deal with it. Could there be an issue with 6.9.2? It was working for me a while though.
-
My server is set to go to sleep after an hour of inactivity. But for some reason the S3 plugin is detecting activity on one of my cache drives every 30 minutes like clockwork. This is a recent development so I though it may have been caused by a docker program after I moved the docker.img file to my cache. But disabling the docker service didn't fix the issue. Does anyone have an idea about what keeps pinging my cache drive? nas-ng-diagnostics-20210428-1559.zip
-
I do have that checked. When it's checked, the options for 'preserve ownership, times' and 'preserve permissions' options become grayed out. You can toggle those two options if switch off NTFS mode first. But doing that didn't make a difference.
-
I think I've fixed the spindown issues I was having. Updating unRAID to 6.9 fixed the unassigned drive and moving the docker Vdisk to the cache allowed the array to spin down. Anyway I'm backing up to an External NTFS drive and I'm getting a huge number of errors saying "failed to set times....... operation not permitted". Is there a way to fix this? Enabling the "attempt super-user activities" option didn't change anything.







