




Marc_G2
Members
-
Joined
-
Last visited
Everything posted by Marc_G2
-
I've continued to have occasional issues with CPU 1. I'm thinking lessoning my undervolt might fix the issue. But does CPU 1 correspond to Core 1? Or does it correspond to the second thread of Core 0?
-
So it's no longer possible to write the syslog to an unassigned device? Does anyone know how I can read the data from my cache share by mounting the drives in windows in the event of a system failure? (Since they advised against constantly writing to flash.)
-
I'm sorry but how do I change the folder logs are saved to?
-
That's the problem. I don't know how to copy them to a share. Or transfer them directly to another computer.
-
Is there any easy way to retrieve the files from the tmp directory? Or can I make it save them to a share? Also I had to reboot my server—in case that matters any.
-
The standard unRAID diagnostics? Or can I generate a debug file for the plugin? nas-ng-diagnostics-20251104-1715.zip
-
This is the config for a particular share with its own dedicated cache. Recently the cache filled up and the mover engaged. It moved everything to the array and I don't understand why. It's set to only move files greater than 300 days old. (And there was plenty of recent files)
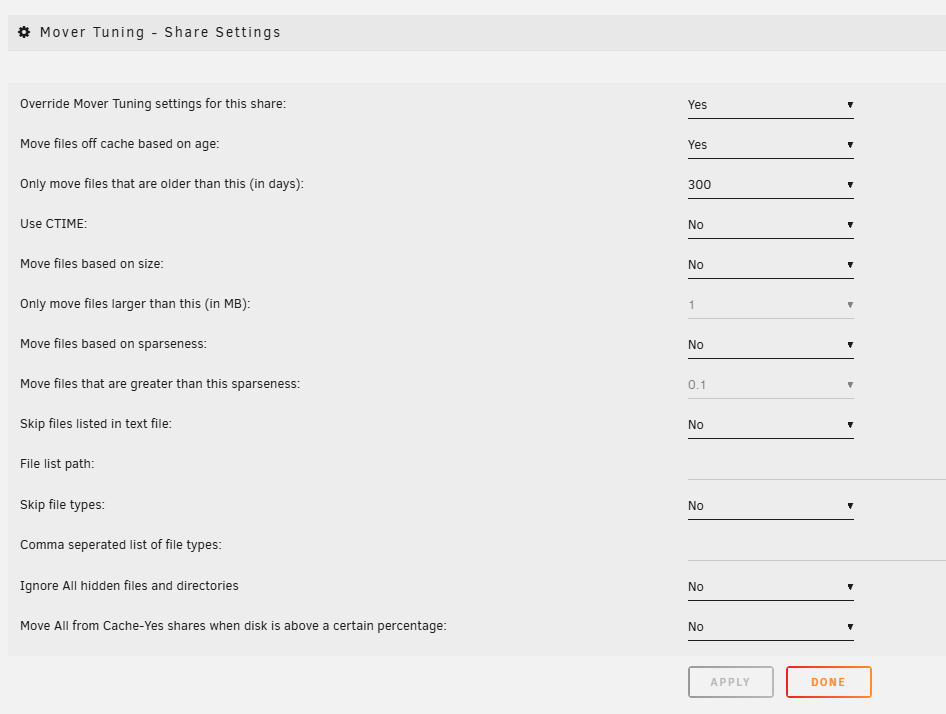
-
Let's say I set Only move at this threshold of used cache space: to 50%. And also Move files that are greater than this many days old: to 150 days. If my cache exceeds 50% but all files are less than 150 days old. Will the mover run but simply not move any files? If I enable Test Mode, where does it output to? The system log? I clicked Move Now with test mode enabled and the mover has been running for the past 20 minutes with zero cache and hard drive activity. Did something go wrong with that operation? Never mind. I suspect what happened is there was a huge number of affected files which made the mover very slow to start.
-
Ok so it was that plugin. I thought the one there was literally the one I just removed since the name didn't change
-
When running "fix common problems" it mentioned I should switch to a fork of the Cache directories plugin due compatibility issues with current unRAID. Is it in the store? I didn't see it.
-
The activity checker is broken and the dev is MIA. I don't think the "monitor disks outside array" setting fixes it. But try and see. If it doesn't, someone has created a fork of the sleep add on that should work. I haven't tested it. https://forums.unraid.net/topic/34889-dynamix-v6-plugins/page/159/#findComment-1364337
-
Ok I'm going to keep an eye out for future errors. Is there a simple way to get unRAID to give notifications when a mce occurs?
-
My system is overdue for an update. And in preparation I was running fix common problems and saw this. This is the first I've ever seen this in the few years I've run this config. What's the most likely cause for this? Could it be a CPU stability problem? CPU 1 is pinned to a Windows VM that stays running 24/7. nas-ng-diagnostics-20241213-1234.zip

-
Keep in mind, the plug-in is just a front end for executing sleep commands on a schedule. If you initiate sleep via the terminal, I strongly suspect you'll have the same issues waking up. My old system had major problems with its HBA card after waking from S3 sleep. The issue was fixed after updating my motherboard to the newest BIOS. So I suggest seeing if updating all your firmware fixes the issue.
-
I double checked the firmware on the LSI card and it's 20.00.07.00. Which is the newest as far as I know. (see image of boot screen below). So who knows. Maybe it's a motherboard issue. The one other thing I should've tried is checking the unRAID error log to see if gave any hints. I've crammed the drive into a shucked WD enclosure. And it's not worth the hassle the remove and check it at this point.
.thumb.png.35f80ed28c3b8a33acd4da6073462a44.png)
-
I'm having trouble excluding directories from an unassigned device share. Is this the correct input field format for excluding two folders? 'Aux SSD/Priority Share/Folder1', 'Aux SSD/Priority Share/Folder2'
-
The drive is HUH728080ALE604. The HBA card is SAS 9211-8i.
-
Before connecting it to the system, I tested the drive over usb and formatted it to NTFS with default parameters. I've put data on it now. So I can't try it unformatted.
-
Yes I was using the same power connection each time. I also tried a different connector which provides the 3.3V. That didn't help. Also all the disks are sata. I'm using mini sas to sata breakout cables.
-
The LSI card is powered by the PCIe slot. It's one ATX power supply powering everything. If the firmware version from 2016 is the newest, then I'm on the latest. I couldn't locate anything newer. I decided to use the hard drive as USB backup drive instead of putting in the array. So the issue is largely moot now. I guess I'll avoid enterprise drives for now.
-
I picked up a used HGST Ultrastar HE8. unRAID doesn't detect it when it's connected via the LSI HBA card. It is detected when it's connected directly via motherboard SATA. Does anyone have an idea why? I tried two different sata connectors coming off the LSI card. One of the 4 connectors was already in use. So I doubt it's the cable. Side note: This drive has a very slow spin-up time. So I don't recommend it for anyone who's set their drives to spin down frequently.
-
I think you'd need to go back to 6.11.X. But that's not recommended. I would try to make use of the network activity monitor or time of day exclusions.
-
The disk activity checker function is broken in the current unRAID version. No one knows when or if it will get fixed.
-
In case anyone's interested, SpaceInvader One did a new video on the topic of sleep/wake with the S3 sleep plugin. Sadly, he did not have any suggestions regarding the disk activity function not working. I'm not sure if he's wasn't affected or he didn't test it thoroughly enough to notice. https://www.youtube.com/watch?v=lBxQcU1MPY0
-
I plan to upgrade most of my stuff to 2.5 gigabit in the next few months. My server cpu is currently a dual-core i3-6100. That's so low spec, I'm wondering if it will (or currently is) slowing down any kind user or backend NAS functions like parity calculations. Or that it might slow down my network transfer speeds on certain kinds of SSD storage pools. Thoughts on this? I'm currently upgrading another gaming desktop. So I have to choose between selling the old hardware or using it to upgrade my server.


.png.72a2ee704fa70b7c2b543180cb841499.png)