




DontWorryScro
Members
-
Joined
-
Last visited
Everything posted by DontWorryScro
-
Same. Did I read that a recent Plex version broke GAPS and we're supposed to revert? Which version should we revert to in the meantime and how to go abouty doing this for first time GAPS installs? Edit: Nevermind, i just needed to make sure it was strictly my ip number. no "http://" and no ":32400" added to the end of the ip
-
updating the port worked. though i had to go into advanced to manually update on the upper webui field. too thanks!
-
this still working? I updated to Unraid 6.9.0-beta22 and I see Deemix "green" an showing as running. But when I try to go to webui it's now "Unable to connect". Tried changing port number to no avail. Something change or break on the Unraid version change?
-
diagnostics-20200610-2034.zip
-
Decided to add an old SSD to my UD's to use as a Plex appdata drive for the metadata. Precleared it. Formatted it xfs but when it finished there is no filesystem on it and Mount is greyed out. What am I doing wrong? When trying different things I try to remove the plex_appdata partition just to start fresh but I get a "Fail" message as a result. My UA Settings for good measure:

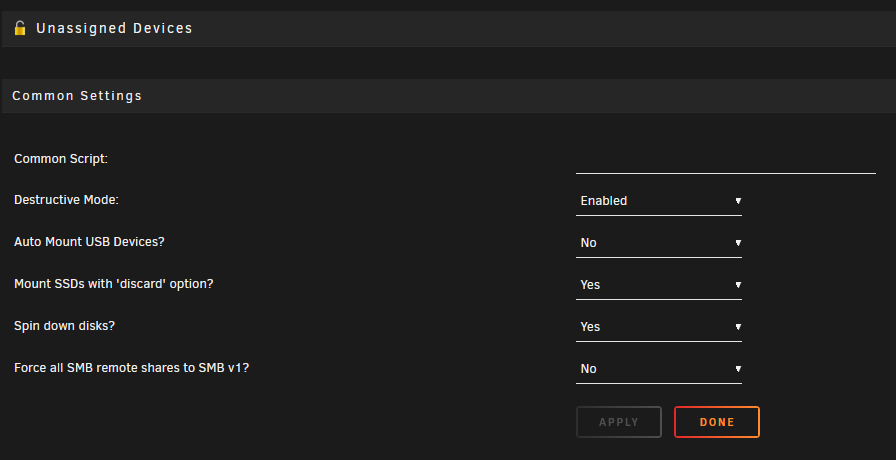
-
I updated to the new repository the other day but started noticing that it was showing up as "not available" in the status column of the docker list. It still launches the webui fine and i can run searches and complete downloads. I'm just not sure why it's not available. I imagine this means I am no longer able to get any sort of update?

-
Yup it seems to be in a holding pattern at the moment.

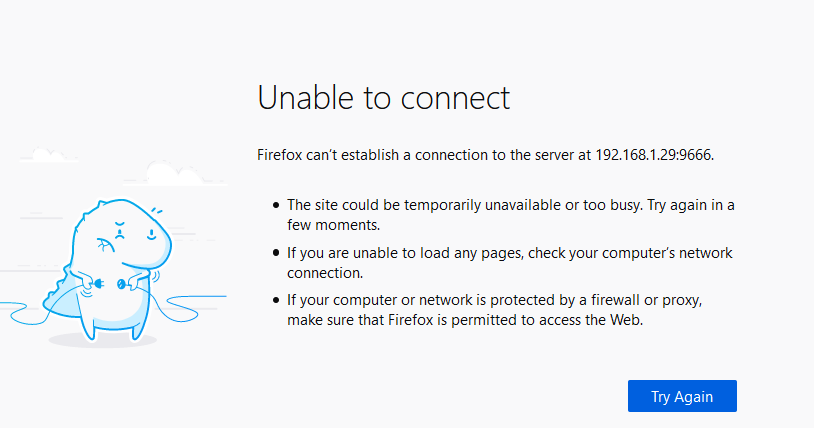
-
bingo. that was it. thank you
-
I seem to have it up and running but it looks like i need to reset up the sharing folders and all the options... essentially it resets back to default every time i restart the container. is there any way for it to retain its settings? what am i doing wrong?
-
much appreciated!
-
is there a step by step guide for the newbiest of newbs to get soulseek up and running on an unraid docker container?
-
How do we update to v3 when using the binhex container? will binhex/arch-sonarr:preview work?
-
I checked for updates on all my docker containers and updated all before realizing I should have confirmed I wasn’t updating deluge prematurely. Now I’m erroring out everywhere because it’s too new and not whitelisted anywhere. Can I get a step by step guide on how to roll this back?
-
Is there some version of Deluge that is at "2.0.3-2"? I've got a certain tracker allowing 2.0.3-2 but apparently not 2.0.3 Color me confused.
-
i didnt scour this thread since page one. i can tell you though that the info i posted was not in the video like you claimed.
-
right but not the <os> section.
-
for people who booted up fine the first time around, decided to give more cores or ram and went back to find the apple logo upper left and weird graphical anomalies try restoring the <os> section of the xml with what was originally there when you first installed. You're welcome. <os> <type arch='x86_64' machine='pc-q35-3.1'>hvm</type> <loader readonly='yes' type='pflash'>/mnt/user/domains/MacinaboxCatalina/ovmf/OVMF_CODE.fd</loader> <nvram>/mnt/user/domains/MacinaboxCatalina/ovmf/OVMF_VARS.fd</nvram> </os>
-
I have a Supermicro x9scm-f motherboard and I'm trying to figure out how to get Fan 2 to react to CPU temp. In the IPMI tool I've been able to connect to the ip and have all the sensors read but I'm only getting the Temp sensor option in Fan Control for Auto, System Temp, Peripheral Temp and HDD Temperature. How do I go about getting Fan 2 which is my CPU fan to ramp up based on CPU temp?
-
The initial install goes great. Editing the VM afterwards to add CPU cores and RAM makes it boot to some display anomaly with distorted loading bars. Looks like some sort of resolution glitch using VNC.
-
I had Sonarr and Radarr stop communicating with binhex-delugevpn sometime in the past 48 hours. Could not for the life of me figure it out. I could not add or search for shows and movies without getting an error. And testing Deluge as the download client failed. Then I realized I had both Sonarr and Radarr using the proxy provided by Deluge, Privoxy. I selected Use Proxy "No" and all the errors went away and Sonarr and Radarr are once again working. Is the problem with the Privoxy function or is it with PIA? Edit: Also I just now realized all the trackers residing in Jackett were also all erroring out. Removed proxy info from Jackett and all is well again. Is something currently wrong with the privoxy function? 2nd Edit: Restoring Privoxy appdata from a backup got me functionality back. Disregard the post. Seems I may have had some corrupt files.
-
It was the one you had linked me. itConfig for Deluge v2
-
Thank you. Dropping it in to the plugins folder for deluge in appdata did the trick.
-
Ok ya that's a different version than the one I just linked but still the same end result. Am I wrong to be saving the file to my local PC and attempting to apply through the thin client? Frankly I don't know any other way to do it. Is the [object FileList] message normal after selecting the file?
-
Got it. Makes sense. I was misunderstanding. So yea I did find the link to the updated plugin that supposedly works here: https://github.com/ratanakvlun/deluge-ltconfig/issues/17#issuecomment-509252150 But I'm still getting that [object FileList] text inside the install browser window when I add it which in turns remains to install. Not sure what I'm doing wrong.
-
I am a bit confused with some of the answers I am seeing and wonder if the confusion lies with which version Deluge people are using. I am trying to install the Itconfig plugin but it won't install. I hear it's because Deluge v2 can't support the older plugins? (Weird, I'd assume all plugins would be backwards compatible) When I try to install the egg file I just get a bracketed message inside the "browse to" window that shows [object FileList] and pressing Install seems to load something for a split second by the plugin does not get installed. I do have the correct versions of python and the python setuptools installed as well as pip via the Nerd Pack. I'm assuming this is a known issue? Is there any work around for this? Or am I doing something wrong? As an aside, am I correct in assuming applying this plugin would be ok and not harm any of the VPN functionality of the client/container?







