




AinzOolGown
Members
-
Joined
-
Last visited
Everything posted by AinzOolGown
-
Hi there Since some days (i'm running solid since 4 years), my dockers stops gradually and it's very hard to make all the systems run again fine (and it shortly redo the same errors :/) When i try to restart them, unraid show an Execution Error so dead end I've searched and found some post talking about bad RAMs and i ran 2 (paralleled and unparalleled) MEMTEST86, which PASSed fine Also found ie this topic that talk about a full cache but it doesn't seem to be the case for me either, so i'm a little lost root@Tower:~# btrfs dev stats /mnt/cache [/dev/mapper/sdk1].write_io_errs 192912 [/dev/mapper/sdk1].read_io_errs 145891 [/dev/mapper/sdk1].flush_io_errs 1086 [/dev/mapper/sdk1].corruption_errs 628 [/dev/mapper/sdk1].generation_errs 0 [/dev/mapper/sdj1].write_io_errs 0 [/dev/mapper/sdj1].read_io_errs 0 [/dev/mapper/sdj1].flush_io_errs 0 [/dev/mapper/sdj1].corruption_errs 0 [/dev/mapper/sdj1].generation_errs 0 [/dev/mapper/sdl1].write_io_errs 0 [/dev/mapper/sdl1].read_io_errs 0 [/dev/mapper/sdl1].flush_io_errs 0 [/dev/mapper/sdl1].corruption_errs 0 [/dev/mapper/sdl1].generation_errs 0 I'm attaching diagnostics and some logs if anyone can point me where i can head next to fix this issue please Thank you very much in advance ! logs.txt tower-diagnostics-20230924-1631.zip
-
Hi ! I just installed Netbox with PostGres15 and got the exact same errors&logs I don't saw any response to this post but maybe i missed it ? Do someone now how to fix this please ? Thank you very much in advance ! EDIT : So, switched to another Netbox docker repo and all's fine with this one Thanks nonetheless
-
Hi You can actualy have access to /var/www/nextcloud by clicking on "console" in the docker's icon menu In my case, this folder's content are pretty much totally gone so i can't use these commands Edit : So, i re-thought all this and decided to let go of Nextcloud. It's been pretty much 10 years i run this and the maintenance time is just too high It broke itself too often, the DB crash, the software do what it please, in short it's not suited in production, in my case at least. At side, i also run Synology NAS for some years, both personnaly and professionnaly, and it it so much more rock solid, never had any trouble ! And it possess the same functions as Nextcloud, can do webdav, auto file-upload (pictures/videos/you name it), sharing etc, so much better choice. Goodby high maintenance time and welcome just enjoy a working synchro/server/services without doing much. Thank nonetheless for the help and good luck
-
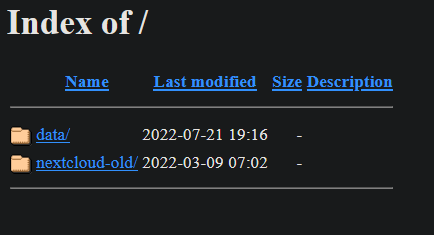
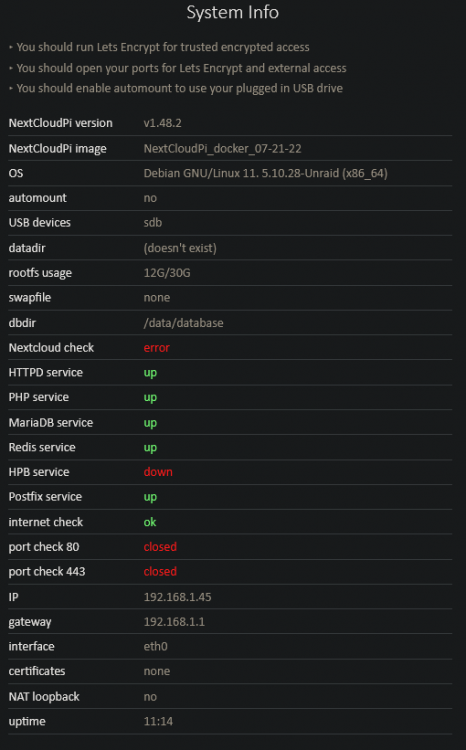
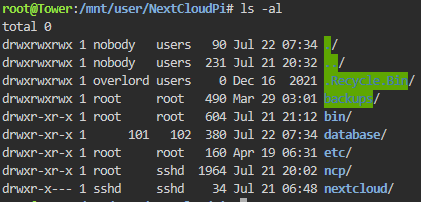
Hi ! Yesterday my NCP made seppuku, that is so strange 8AM, i'm heading to work like always In the middle of my way, i received notif about some connection problems. It happends from time to time if the synchro runs when i have a poor mobile network, so i just discarded it. It persisted for some hours, so i tried to connect to my Nextcloud instance via the mobile app, and it gave me "No files". Thought my server just froze so decided to wait 'till i'm home. 7PM, home, server is all good, all service running except Nextcloud and i can't connect to it (but i can connect to NCP's admin) I don't understand what's going on, i haven't changed anything in config, there was just a parity check running Bellow the logs & informations - When i click on "WebUI" in Unraid NCP docker's menu, i now have this in place of Nextcloud's login screen : - There, if i correctly understand, it tells that the last DB operation was 22 Jul at 07:34 - NCP's System Info : Do someone ever saw this ? O_o Thank you in advance P.S.: Made this morning the latest NCP docker's update but no change Already rebooted the server and tried to reinstall docker /data/nextcloud.log is empty tower-syslog-20220721-1732.zip NCP docker's log.txt NCP -data- tree.txt
-
Thank you very much ! That solved the issue ^^
-
Hi there ! I just shuked a new WD 12Tb drive and wanted to preclear it with this new plugin First, there was no way to have the preclear option show, then i read that the disk must not contain any partition, so i deleted it by the cli. Now the little preclear icon show on unassigned partition but the preclear fail everytime And if i go on the plugin UI, it doesn't list the WD 12Tb at all P.S.: i Tried to use the wipefs -a /dev/sdl cli (for my case) but fail again Do you have any idea please ? Thank you !
-
Hi It would be fabulous to have the "simple" option to disable a certain wireguard peer like this : https://github.com/WeeJeWel/wg-easy (just by unticking the peer line) without to delete it (actual behavior), please ! (i have Dynamix wireguard) Thank you very much
-
Hi Sickdove, Like potjoe said some post above : My logs looks like this : Starting PHP-fpm Starting Apache Starting mariaDB 2021-12-07 17:05:33 0 [Note] mysqld (mysqld 10.3.31-MariaDB-0+deb10u1) starting as process 214 ... Starting Redis Starting Cron Starting Postfix So i think your problem lie in between your db and cache And, if you could try to remember what you changed before it stoped (an update ? a change in the config ? ), that will help others to help you Oh, and, do you have a db backup ? (you could set this automatically in admin panel / Backups / nc-backup-auto)
-
Hi Guys ! After the latest update, my GitLab-ce won't boot anymore 😭 It launch, take it's time like always and progressively take memory, but never it is accessible again by the WebUI/DNS It respond to ping but that's all... Please, help ! I'm developping a website+app for my own brand new company and all the projects are on it 😱 I'll gladly share any more log you'll need, but it seems to have a lot, just tell me the one that can help please 😇 Attached is a copy/paste of the log windows in unraid GUI. Thank you very much ! P.S. : If it's more convenient to redo a docker and import the DB (is it even possible ? My projects are not totally lost ?), no problem ^^ GitLab-ce logs.txt Edit SOLVED : Back online again ! Phew~~ 😌 That was a problem with external_url param. With some little changes and a downgrade/upgrade, all working again, thanks nonetheless
-
Sorry to hear that
-
Thank you potjoe ! Rebuilding the container does'nt change nothing alas Here is the log's content : [Warning] The parameter innodb_file_format is deprecated and has no effect. It may be removed in future releases. See https://mariadb.com/kb/en/library/xtradbinnodb-file-format/ 2021-10-16 10:23:28 0 [Note] InnoDB: Using Linux native AIO 2021-10-16 10:23:28 0 [Note] InnoDB: Mutexes and rw_locks use GCC atomic builtins 2021-10-16 10:23:28 0 [Note] InnoDB: Uses event mutexes 2021-10-16 10:23:28 0 [Note] InnoDB: Compressed tables use zlib 1.2.11 2021-10-16 10:23:28 0 [Note] InnoDB: Number of pools: 1 2021-10-16 10:23:28 0 [Note] InnoDB: Using SSE2 crc32 instructions 2021-10-16 10:23:28 0 [Note] InnoDB: Initializing buffer pool, total size = 256M, instances = 1, chunk size = 128M 2021-10-16 10:23:28 0 [Note] InnoDB: Completed initialization of buffer pool 2021-10-16 10:23:28 0 [Note] InnoDB: If the mysqld execution user is authorized, page cleaner thread priority can be changed. See the man page of setpriority(). 2021-10-16 10:23:28 0 [Note] InnoDB: Starting crash recovery from checkpoint LSN=14054915147 2021-10-16 10:23:28 0 [Note] InnoDB: 128 out of 128 rollback segments are active. 2021-10-16 10:23:28 0 [Note] InnoDB: Removed temporary tablespace data file: "ibtmp1" 2021-10-16 10:23:28 0 [Note] InnoDB: Creating shared tablespace for temporary tables 2021-10-16 10:23:28 0 [Note] InnoDB: Setting file './ibtmp1' size to 12 MB. Physically writing the file full; Please wait ... 2021-10-16 10:23:28 0 [Note] InnoDB: File './ibtmp1' size is now 12 MB. 2021-10-16 10:23:28 0x1525cac94700 InnoDB: Assertion failure in file /build/mariadb-10.3-XTU5dn/mariadb-10.3-10.3.29/storage/innobase/include/fut0lst.ic line 85 InnoDB: Failing assertion: addr.page == FIL_NULL || addr.boffset >= FIL_PAGE_DATA InnoDB: We intentionally generate a memory trap. InnoDB: Submit a detailed bug report to https://jira.mariadb.org/ InnoDB: If you get repeated assertion failures or crashes, even InnoDB: immediately after the mysqld startup, there may be InnoDB: corruption in the InnoDB tablespace. Please refer to InnoDB: https://mariadb.com/kb/en/library/innodb-recovery-modes/ InnoDB: about forcing recovery. 211016 10:23:28 [ERROR] mysqld got signal 6 ; This could be because you hit a bug. It is also possible that this binary or one of the libraries it was linked against is corrupt, improperly built, or misconfigured. This error can also be caused by malfunctioning hardware. 2021-10-16 10:23:28 0 [Note] InnoDB: 10.3.29 started; log sequence number 14054915200; transaction id 26904017 To report this bug, see https://mariadb.com/kb/en/reporting-bugs We will try our best to scrape up some info that will hopefully help diagnose the problem, but since we have already crashed, something is definitely wrong and this may fail. Server version: 10.3.29-MariaDB-0+deb10u1 key_buffer_size=134217728 read_buffer_size=131072 max_used_connections=0 max_threads=153 thread_count=1 It is possible that mysqld could use up to key_buffer_size + (read_buffer_size + sort_buffer_size)*max_threads = 467429 K bytes of memory Hope that's ok; if not, decrease some variables in the equation. Thread pointer: 0x1525b4000c08 Attempting backtrace. You can use the following information to find out where mysqld died. If you see no messages after this, something went terribly wrong... stack_bottom = 0x1525cac93d58 thread_stack 0x49000 2021-10-16 10:23:28 0 [Note] Plugin 'FEEDBACK' is disabled. 2021-10-16 10:23:28 0 [Note] Recovering after a crash using tc.log 2021-10-16 10:23:28 0 [Note] InnoDB: Loading buffer pool(s) from /data/database/ib_buffer_pool 2021-10-16 10:23:28 0 [Note] Starting crash recovery... 2021-10-16 10:23:28 0 [Note] Crash recovery finished. mysqld(my_print_stacktrace+0x2e)[0x559fc83ad31e] mysqld(handle_fatal_signal+0x54d)[0x559fc7ed857d] /lib/x86_64-linux-gnu/libpthread.so.0(+0x12730)[0x1525fa84e730] /lib/x86_64-linux-gnu/libc.so.6(gsignal+0x10b)[0x1525fa6b27bb] /lib/x86_64-linux-gnu/libc.so.6(abort+0x121)[0x1525fa69d535] 2021-10-16 10:23:28 0 [Note] Server socket created on IP: '127.0.0.1'. mysqld(+0x4e92f9)[0x559fc7c1a2f9] mysqld(+0x4e5ffa)[0x559fc7c16ffa] mysqld(+0xa15865)[0x559fc8146865] mysqld(+0xa162f4)[0x559fc81472f4] mysqld(+0xa022d8)[0x559fc81332d8] /lib/x86_64-linux-gnu/libpthread.so.0(+0x7fa3)[0x1525fa843fa3] /lib/x86_64-linux-gnu/libc.so.6(clone+0x3f)[0x1525fa7744cf] Trying to get some variables. Some pointers may be invalid and cause the dump to abort. Query (0x0): (null) Connection ID (thread ID): 1 Status: NOT_KILLED Optimizer switch: index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,index_merge_sort_intersection=off,engine_condition_pushdown=off,index_condition_pushdown=on,derived_merge=on,derived_with_keys=on,firstmatch=on,loosescan=on,materialization=on,in_to_exists=on,semijoin=on,partial_match_rowid_merge=on,partial_match_table_scan=on,subquery_cache=on,mrr=off,mrr_cost_based=off,mrr_sort_keys=off,outer_join_with_cache=on,semijoin_with_cache=on,join_cache_incremental=on,join_cache_hashed=on,join_cache_bka=on,optimize_join_buffer_size=off,table_elimination=on,extended_keys=on,exists_to_in=on,orderby_uses_equalities=on,condition_pushdown_for_derived=on,split_materialized=on The manual page at https://mariadb.com/kb/en/how-to-produce-a-full-stack-trace-for-mysqld/ contains information that should help you find out what is causing the crash. We think the query pointer is invalid, but we will try to print it anyway. Query: Writing a core file... Working directory at /data/database Resource Limits: Limit Soft Limit Hard Limit Units Max cpu time unlimited unlimited seconds Max file size unlimited unlimited bytes Max data size unlimited unlimited bytes Max stack size unlimited unlimited bytes Max core file size 0 0 bytes Max resident set unlimited unlimited bytes Max processes 256163 256163 processes Max open files 40960 40960 files Max locked memory unlimited unlimited bytes Max address space unlimited unlimited bytes Max file locks unlimited unlimited locks Max pending signals 256163 256163 signals Max msgqueue size 819200 819200 bytes Max nice priority 0 0 Max realtime priority 0 0 Max realtime timeout unlimited unlimited us Core pattern: core # So, it is a corrupted library problem, if i understand correctly ? If the container's rebuild is not enough, i maybe have to delete the image as well, and build it again ? But, will i lose my data/NC config doing so ? (i have backups, but for an unknown reason, i just realized that automatic backups (set within NCP) have stoped near a month ago without changing nothing to the config) Edit : Deleted the image as well but that does'nt resolved my problem neither Tried to build another container, different name/ip and point datadir to the same as the first container, no success Edit2 : Do someone know where, exactly, is stored Nextcloud's DB please ? In the datadir, but what's the exact path please ? i'll try to copy into a new NCP docker and see if i can run like this without any lose Thanks ! Edit3 : Tried to copy the nextcloud folder and successfully recovered Nextcloud's settings (with littles exceptions, like MFA), but no success with the db recovery atm Edit4 : Okay, too much time passed on this to recover the actual db, so restored a backup from one month ago and "kind of" resolved. Thanks anyway
-
Hi Yoshiiaki, I maybe wrong but i think it tells you that you need to install the said library (pdlib) before installing the face recognition app In exemple : https://help.nextcloud.com/t/app-face-recognition-cannot-be-installed-pdlib-is-not-available/108803/4
-
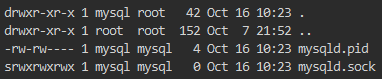
Hi guys ! My server frozed this night and i have to reboot it manually. All is up and running except Nextcloud (admin interface is ok) Here's the log : Starting Redis Starting Cron Starting Postfix ERROR 2002 (HY000): Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock' (111) /run-parts.sh: line 47: /etc/services-enabled.d/services-enabled.d: Is a directory e /run-parts.sh: line 6: /etc/services-enabled.d/services-enabled.d: Is a directory stopping Cron... stopping Redis... stopping Postfix... stopping HPB... notify_push: no process found Stopping apache Stopping PHP-fpm Stopping mariaDB stopping Cron... stopping Redis... stopping Postfix... stopping HPB... notify_push: no process found Stopping apache Stopping PHP-fpm Stopping mariaDB mysqladmin: connect to server at 'localhost' failed error: 'Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock' (111)' Check that mysqld is running and that the socket: '/var/run/mysqld/mysqld.sock' exists! I checked, and the file mysqld.sock do exist Concerning the MySQL server, it auto-launch itself, right ? I never had to launch it manually, so there's a problem with it but i don't know where to look to have further detail and debug this. Can anyone point me to the right direction please ? P.S.: Already restarted the docker multiple times, no change. Even with a docker's update, that does'nt correct this error
-
No problem, don't worry Glad i've made the right choice, that was just guessing and asking for help ^^ Thank you nonetheless Primeval
-
Oh, maybe you wanted to say "install python within whatever docker container you have" more than "set a python only docker container that you can broke all you want without having to worry about the main purpose of the said container" ? 😁 EDIT: All up and working ^^ Asked a dev friend for the docker's part and after some tries, have a python docker scheduled with user script ! Thank you very much EDIT2: For other newbs like me, if you want a python docker : I'll take as exemple the python script i wanted to use (dyn-gandi), so download it and don't forget to copy config.ini-dist to config.ini, then add your Gandi info and save. 1- You need to add a file named "Dockerfile" in the folder with similar content : FROM python:3.9.7-alpine3.14 WORKDIR /app COPY . /app RUN python setup.py develop CMD ["python", "dyn_gandi.py"] 2- Move this folder (dyn-gandi-1.***) somewhere in unRAID (i personnaly placed it in /mnt/user/appdata, with other dockers) 3- cd into this folder 4- type this command : docker build -t dyn-gandi . (this will build the docker's image) 5- When the process is over, type : docker run dyn-gandi (this will build the docker's container, based on the image) If all this ran well, you should see a line with your current IP 6- In unRAID's docker tab, you should see 2 more lines, the python alpine one and a new docker. Mine looks like this : (copy the container's ID, here d224bb535b10) 7- Install "User Script" plugin if you don't already have it (use the Apps tab and search function) 8- Go in the plugins tab, User Script 9- "Add new script" button and paste this: #!/bin/bash docker start d224bb535b10 Don't forget to replace d224bb535b10 by your container's ID And "save change" button You can set a description and a name for this script too if you want Set a schedule that please you Click on Apply 10- done !

-
Thanks Primeval Could you recommand me a good one please ? (Searched on Apps, but no luck apparently)
-
Hi everyone ! My ISP do not offer static IP, so regularly i need to update my Gandi DNS with the new IP. To automate this task, i found a promising script here : https://github.com/Danamir/dyn-gandi It work on my Windows VM i used for testing it but unRAID seems to handle this differently (of course i enabled Nerd Tools's Python/pip/setuptools) But i can't get it to work Maybe there is some magic ? Followed some posts saying to use "user scripts" but this script contains multiple files and i don't know how to bring them together Also, i need to CRON this too ^^ Can any kind soul lend me an hand, please ? Thanks in advance !
-
Oh ok, thank you ^^
-
Hi There I made a mistake and now my NCP is no longer accessible, can you help me please ? First, i made an minor update, from 21.0.3 to 21.0.4.1 if i recall correctly, but i don't think that's the problem (the process made a backup during it, too) Secondly, after setup Nginx Proxy Manager, i thought to deactivate letsencrypt on the NCP panel to just have NPM take care of the ssl cert After a reboot, bam, dark page, connexion error I can ping the NCP container's IP fine though Here's the log Starting PHP-fpm Starting Apache AH00526: Syntax error on line 5 of /etc/apache2/sites-enabled/ncp.conf: SSLCertificateFile: file '/etc/letsencrypt/live/website.abc/fullchain.pem' does not exist or is empty Action 'start' failed. The Apache error log may have more information. Starting Redis Starting Cron Starting Postfix ERROR 2002 (HY000): Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock' (2) /run-parts.sh: line 47: /etc/services-enabled.d/services-enabled.d: Is a directory Init done And, in fact, there is no file in the /etc/letsencrypt/live/website.abc/ directory I have backups from last Saturday, but if it is possible to repair this instance and not lose the change made since, that will be wonderfull ^^ Do you have some idea, please ? Do not hesitate if you need more informations Thank you very much ! EDIT: Have found a folder "Nextcloud/etc/letsencrypt/archive/" with the certs backups So, copied the latest under /etc/letsencrypt/live/website.abc/ and recovered access to NCP and my files hoooray 🎉 Strange fact : My NCP version is now 1.34.7 (it was almost the latest one before this incident, or so i think ?) I'm trying to update it but that does'nt seems to work for the time EDIT2: Let the update on his own and after coming back, bam, 1.38.5 ^^ So problem solved, thank you nonetheless
-
Ok, thank you very much for your incredible support ! Belive me or not guys, that was "my" fault (so so so so so sorry😢) The culprit was found, it seems that there was an *unknow* rule set on my ISP box (i cannot access all its settings 😡) and i discovered it when i tried to set a fixed IP on ferdi-client's container. So i just changed IP and all went fine... So sorry ich777 to have spoiled so much of your time on this 😢 But, thank you so much !
-
Hum, ok, sorry ^^ Checked Docker's gateway : Unraid network's : And Added parameter in Ferdi conf : But no success Do you see something wrong in my config ? (192.168.1.1 is my router)



-
Nope : # wget https://raw.githubusercontent.com/ich777/versions/master/FerdiClient --2020-11-08 11:07:04-- https://raw.githubusercontent.com/ich777/versions/master/FerdiClient Resolving raw.githubusercontent.com (raw.githubusercontent.com)... failed: Temporary failure in name resolution. wget: unable to resolve host address ‘raw.githubusercontent.com’
-
It's saying : LATEST=5.5.0 UPDATED=2020-11-08T09:05Z Yes i have, PiHole's blocking the connection ? Will investigate ^^ Thanks Edit : No blocking from PiHole Edit2 : Just tried your Chrome's docker and all is fine
-
Hi there ! I have a little problem with the Ferdi-client's docker : It's launching good but it's not reachable. Here's the log : ---Checking if UID: 99 matches user--- ---Checking if GID: 100 matches user--- ---Setting umask to 000--- ---Checking for optional scripts--- ---No optional script found, continuing--- ---Starting...--- ---Can't get latest version of Ferdi-Client, putting container into sleep mode!--- Session terminated, killing shell... ...killed. ---Checking if UID: 99 matches user--- usermod: no changes ---Checking if GID: 100 matches user--- usermod: no changes ---Setting umask to 000--- ---Checking for optional scripts--- ---No optional script found, continuing--- ---Starting...--- ---Can't get latest version of Ferdi-Client, putting container into sleep mode!--- I tried to manually pull the docker's image but same error Thank you ^^
-
No problem, it's done Thank you !









