

TIE Fighter
-
Posts
54 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by TIE Fighter
-
-
On 3/23/2023 at 8:26 AM, daTroll said:
On my side, the status says “Running” in green. On your suggestion, because the Sleep plugin is no longer working also in my system, I changed the first setting to Disabled. This changed the status to “Stopped” in orange, and like you I seem to recall this is what it said in the past (before the most recent update) as well. I changed the setting back to Sleep, but going to sleep it does not. 🤷♂️ I’m sure I haven’t touched any configuration since it was working, except for installing a few updates including the latest Sleep plugin.Same for me aswell s3 sleep plugin do not put the server to sleep.
So this is a new setup, Unraid 6.11.5, just installed all the plugins i normaly use and put settings for sleep in the plugin but just realised last night that it doesent go to sleep.
Any fix for this?
-
-
-
+1 i am in the same situation.
my gigabyte X570 AORUS master is lacking support for the fan and temp sensors in unraid and I am looking for a solution to control them in the unraid ui.
Can you try and see if you can control them with the plugin and report back?
-
21 hours ago, workermaster said:
You mention that you have 4 pieces of the GPU passed through. I thought that there only were 3.
Here is a screenshot of my VM. I hope that it helps.
there are 4 on my Radeon RX 6800xt on the bus 10.x.x all passed
 21 hours ago, workermaster said:
21 hours ago, workermaster said:by the AMD driver. I am also running 21.8.2 and do not have that issue.
atleast it is was not a driver issue.
infact i found the issue was caused by the S3 sleep plugin. when the plugin didnt pick up any disk activity a sleep command was issued trying to put the server asleep this made the VM crash and sleep was put on hault. my second vm was restarted so that made me think it could also be related to the host, i thought the S3 Sleep plugin would know if any Vms were infact running but it looks like it didnt.
to find the ip adress for the VMs i Open unraid terminal and type:
arp -a | grep br0
the Vms ip adress to be put to "wait for host inactivity"
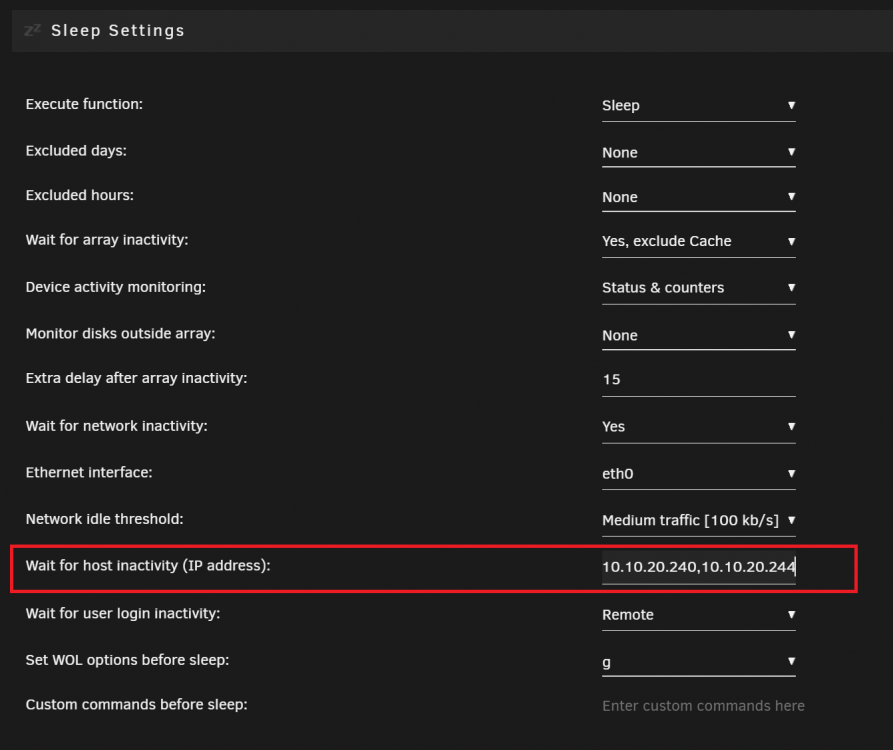
this made all the issues dissapear 🙂
cheers
-
2 hours ago, dlandon said:
You can filter the log messages by installing the Enhanced Log plugin and filtering these messages in the log 'Syslog Filter' tab of Enhanced Log.
thank you very much for the advice and for another great plugin 🙂
12 minutes ago, dlandon said:UD does not spin down disks. Those messages come from Unraid spinning down the disk. Where is the disk passed through to? Check there.
passed to a vm as a virtual disk, i'll have a look.
cheers.
-
1 hour ago, dlandon said:
You rebooted, so the log doesn't show the spin downs for /dev/sda like you posted. Looks like you have the spin down set for every 15 minutes.
/dev/sda is a WD hard drive (WD60EFRX), so Unraid will spin it down. It doesn't appear to be a nvme SSD, but the sdX designation can change on reboot so that might not be right.
This is not really a UD issue.
You can filter the log messages by installing the Enhanced Log plugin and filtering these messages in the log 'Syslog Filter' tab of Enhanced Log.
correct the server was rebooted after my first post did not notice the sdX deignation was changed sorry for confusion.
see below

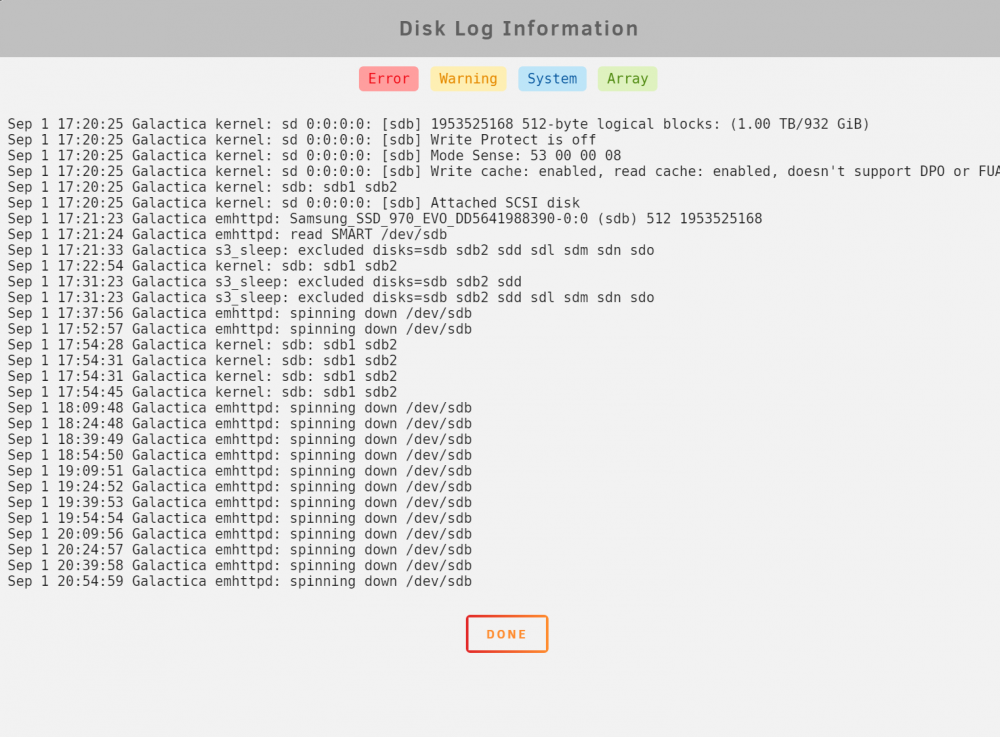
the timer spin down timer set for 15min.
so thats why the disk log is filling up for that particular drive.
so unassigned devices do not exclude ssd/nvme drives like unraid is excluding cache drives from spin down?
-
23 minutes ago, dlandon said:
That's not enough information. Please post the diagnostics.
please find attached diagnostics.
-
parity rebuild completed manually stopped the vms and dockers.
one docker was not possible to stop and forced the array to not be put offline.
for future knowledge it was a docker that i added from github rep that manage the HBA Card Adaptec 71605.
i only use this to monitor the temp of the card.
hard rebooted and stopped the docker from autostart.
now been trying a cuple of shutdown and reboot attempts and everything seems ok.
cheers
-
just want to report some feedback on this awesome plugin.
have one usb to nvme disk attached and the disk log fills up with spinning down commands.
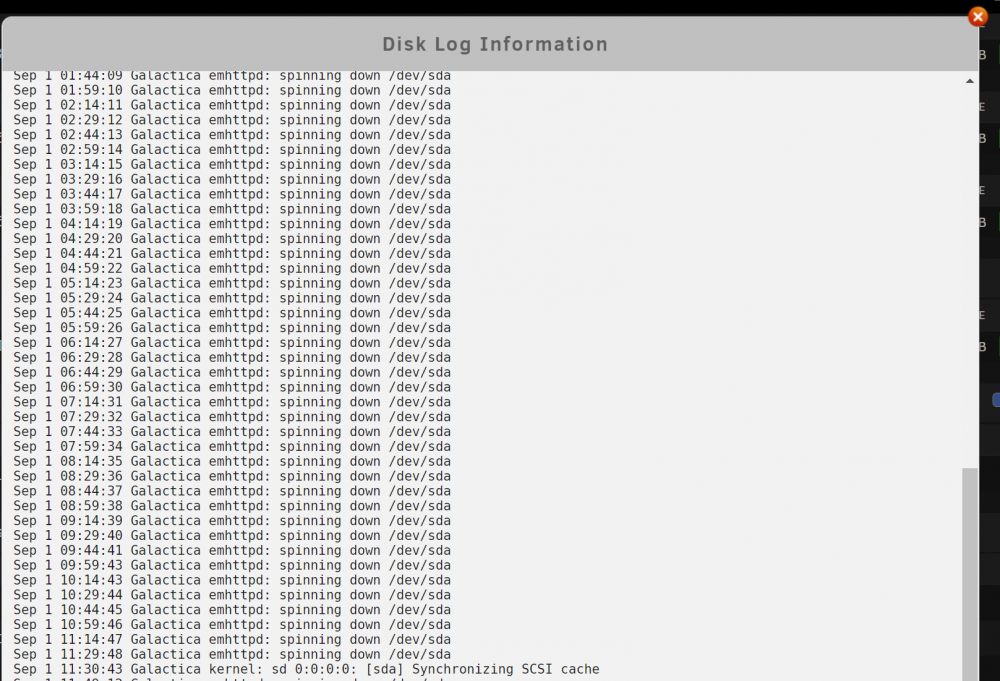
-
having somewhat similiar problems with my Radeon rx 6800xt.
Unraid 6.9.2
All 4 components for the gpu are passed trough to the Win10 Vm.
Win 10 VM boots up, running some games and performance tests works.
but then randomly from 1 day to 1 hrs running the VM the amd software reports driver crash, the gpu fans ramps up to maximum the monitor switches to windows basic adapter and the Win 10 VM freezes only possible to stop the VM in unraid gui.
tested drivers: Adrenalin 21.8.2 and Adrenalin 21.6.1
machine type: q35 -5.0 and q35 -5.1
VM logs show no warnings or error but the system logs does.
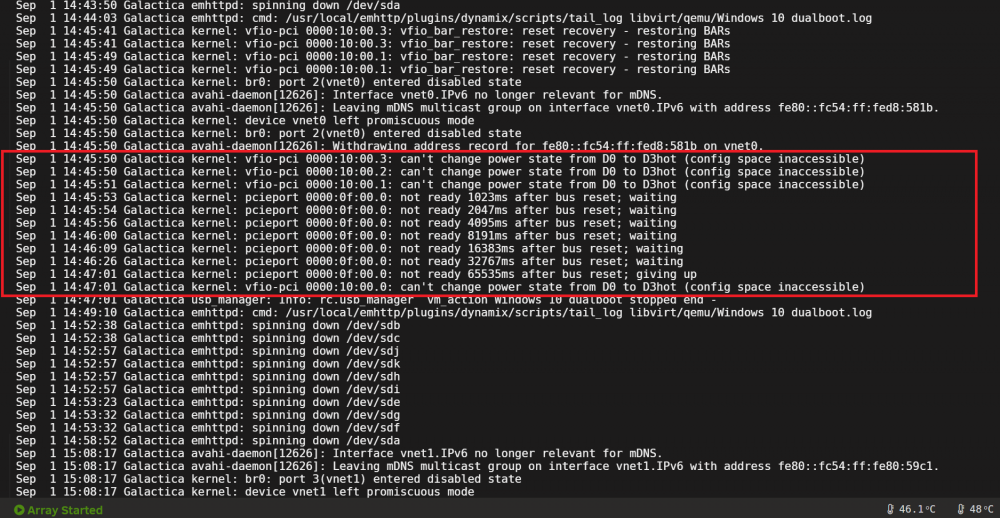
is there something i should include in the XML as per this post setting a vendor id?
or as @ich777 mention in this post upgrading to 6.10 rc1 and install amd vendor reset?
the big Navi cars should not be affected by the reset bug so i am strugling at this moment to pin point the cause.
-
On 8/31/2021 at 3:51 PM, trurl said:
What have you already tried that was discussed in this thread you have posted in?
at this moment manually before soft reboot the server
- stopped the two VM:s before rebooting.
- rebooting with external nvme to usb drive attached and unplugged
- unmount smb shares
- stopped dockers
- increased the timer in Settings->Disk Settings->Shutdown time-out to: 420s
- increased VM shutdown time-out: 300s
at the moment i am doing a Parity-Sync / data rebuild from this morning when i have to replace an old data drive so i am unable to try to reboot at the moment.
-
Hello there
i have some major problem with my new server setup.
server in GUI mode and successfully setup two win10 vms with gpu passtrough.
3 external USB to NVME drives out of two is on the same controller and passtrough to Win10 vm #1 and one ext drive is showed in unraid as unassigned device with the "pass" option enabled and used as a vitrual drive on the Win10 VM #2.
at rebooting first the reboot splash screen appears time counting until localhost is losing the connecting then nothing happends.
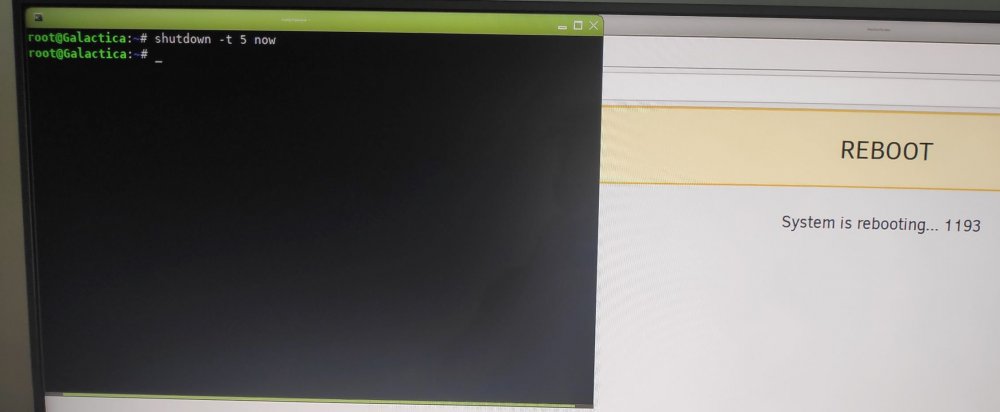
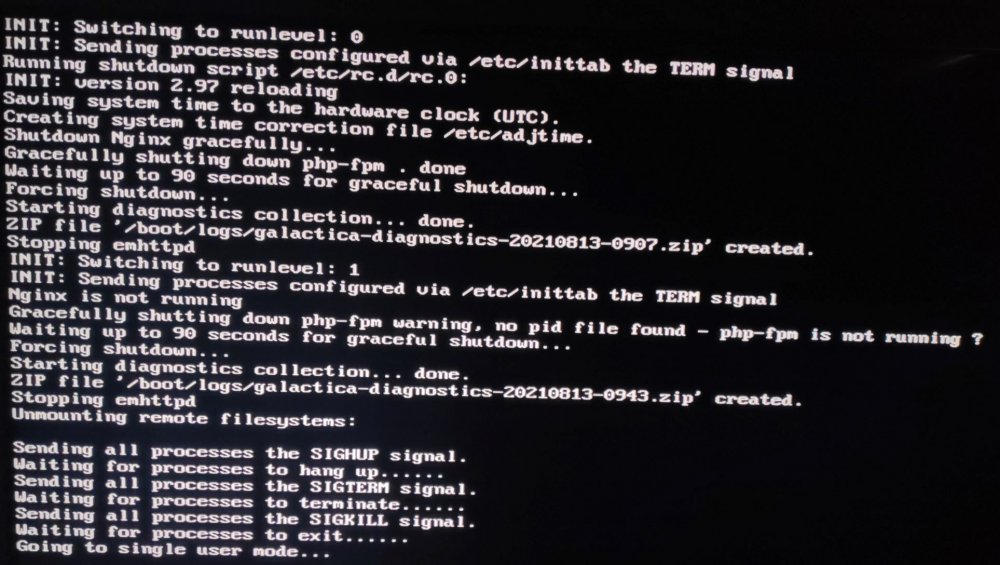
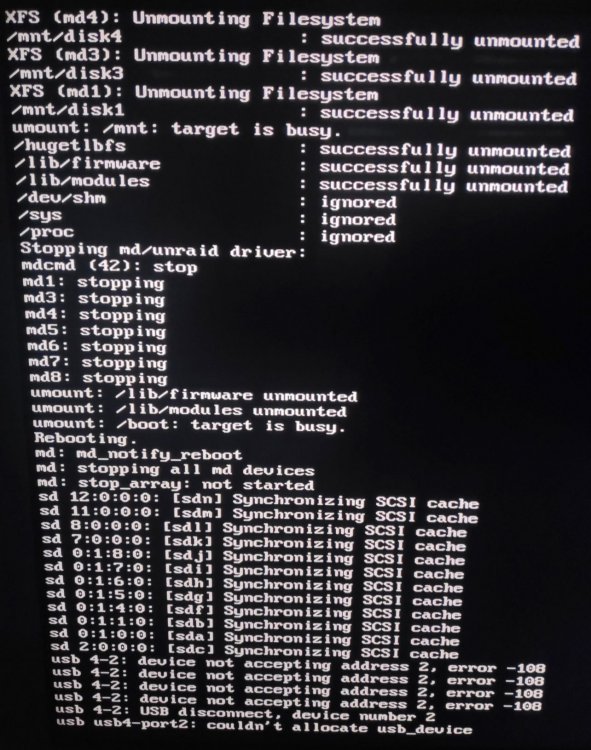
i can still access the terminal window and using command "shutdown -t 5 now" forces the server to action but only until its trying to allocate the unraid usb flash drive and then nothing, forceing me to hard reset the server everytime.
can the problem be with the external drive on the controller managed by unraid as rebooting the server with that drive disconnected works?
issue also posted for support in the unnassigned devices plugin forum
very much apprecietad if someone can have a look at the diagnostic file
-
-
On 8/17/2021 at 5:57 PM, trurl said:
USB may disconnect and so is not recommended for array or pool.
understand it is not recommended but as described i tried different ways but the whole server just ends in a state where it is not responding at all for reboot or shutdown commands.
maybe it is a plugin or unraid limit thus why the diags attached for the creater or someone to pinpoin the cause.
i am more than happy for a reply regarding root cause
-
hello there.
i have some major issues with my external usb 3.2 gen 2 to nvme disk.
https://www.orico.me/product/nvme-m-2-ssd-enclosure-10gbps-tcm2-c3/
connected to the server as standalone unassigned device or as a part of the cache pool stops the server from clean reboot/shutdown.
using gui mode and rebooting first the reboot splash screen appears counting time until localhost is losing the connecting and reboot starting to initialise and then nothing happens.
i can still access the terminal window using command "shutdown -t 5 now" forces the server to action but only until its trying to allocate the unraid usb flash drive and then nothing forceing me to hard reset the server everytime.
putting the external disk on a usb controller and then passtrough to a win10 vm, reboot server works, as long as unraid is not using the external disk as cache or unassigned device
i tried with a different external drive enclosure using the Realtek rtl9210
https://www.orico.cc/us/product/detail/7214.html
same issues.
pls see att diag. #1
happened again today when trying to reboot server remotely diag#2
galactica-diagnostics-20210813-0907.zip galactica-diagnostics-20210817-0838.zip
-
some more info.
""Further work ...
The 8688 can be made to work using the --force_id=0x8688 flag when inserting the module but this will also identify the 8792E as an 8688 leaving you with two chips with the same name which is confusing.
To get the IT8688E working with the IT8792E sensor chips and correctly identified first edit the it87.c file replacing all instances of "8686" with "8688" as the chips appear to be identical then make the module.""
""This should work: just paste it into a file in /etc/sensors.d"
source:
https://linustechtips.com/topic/1095169-x570-aorus-pro-wifi-with-3900x-and-32gig-of-ram/
anyone??
-
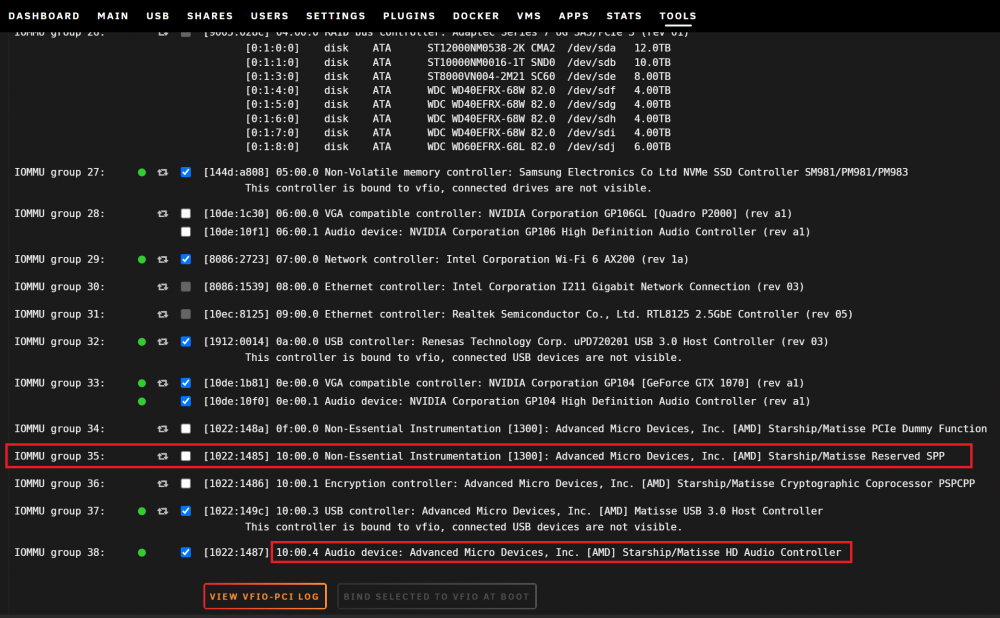
36 minutes ago, ghost82 said:
Try to passthrough also iommu 35 and 36, all 10:00.x devices
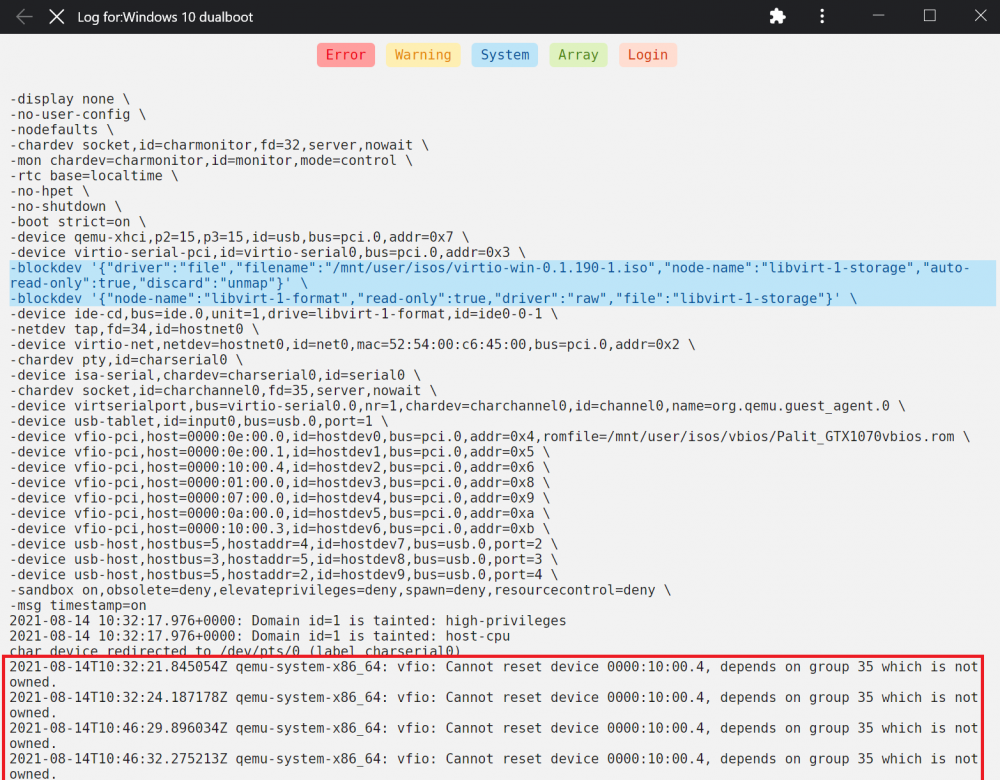
when i tried to passtrough IOMMU group 35 and IOMMU group 36 and start the VM the monitor loose signal to the VM and the server stutters/ freeze only way is to hard reset the server.
binding works but passtrough those groups and start the VM freeze the server.
-
23 hours ago, gray squirrel said:
Have you got overrides enabled, was that device in another group?
you might have luck removing overrides and passing the non essential instrumentation part as well.
also, did you try “VFIO allow unsafe interrupts” in the VM manager.
PCIe ACS override = disabled
i tried to vfio bind the IMMOU group #35 and passtrough to the VM aswell thinking that it might be related to the sound stutters but no success so far the VM did not boot and the server froze forceing me to hard reset. and revert back the changes. *see att screenschots
VFIO allow unsafe interrupts = enabled
again amd controller IOMMU group #37 vfio bind and passtrough to the VM
IOMMU group 32 pcie x1 usb 3.0 card controller vfio bind and passtrough to the VM
test
RND4K Q32T1 = still the same issues with both amd usb controller and the pcie x1 usb 3.0 card controller
-
1 hour ago, gray squirrel said:
Also, are you able to boot your VM as a native machine. It might be worth checking you don't get the same behaviour in a non virtualized environment
edit: just re-read your OP, did you benchmark on the same hardwhere
the vm is configured as a dual boot so i can restart the machine in baremetal win10, se first post.
in baremetal win10 everything works as expected and the performance is close to win10 vm except the last to tests
RND4K Q32T1
RND4K Q1T1
where the issues starts in the vitrual enviroment.
-
1 hour ago, gray squirrel said:
So I’m still a little suspicious of the amd controller, can you try unbind it? And retest.
I notice on your template you have the USB emulation set to 3.0 (qemu XHCI). This is different from the default is 2.0 EHCI.
with a sata SSD in a USB caddy this made no difference to the speed. I don’t know but might be something to test.
I don’t have an NVME in a external drive to try and replicate unfortunately.
Are you seeing anything in unraid or VM logs, maybe try enabling allow unsafe interupts
unbinded to usb controller intergrated to the cpu.
restart the VM & server
using only the pcie x1 usb 3.0 card controller and the two external drives attached and 2.0 EHCI usb emulation, same results
i did noticed demonic sound aswell using the 2.0 EHCI usb emulation.
reverted back to 3.0 QEMU no demonic sound but still usb disconnects during performance tests.
i did noticed something in the wm log however it did not shows up as a warning so maybe its not related.
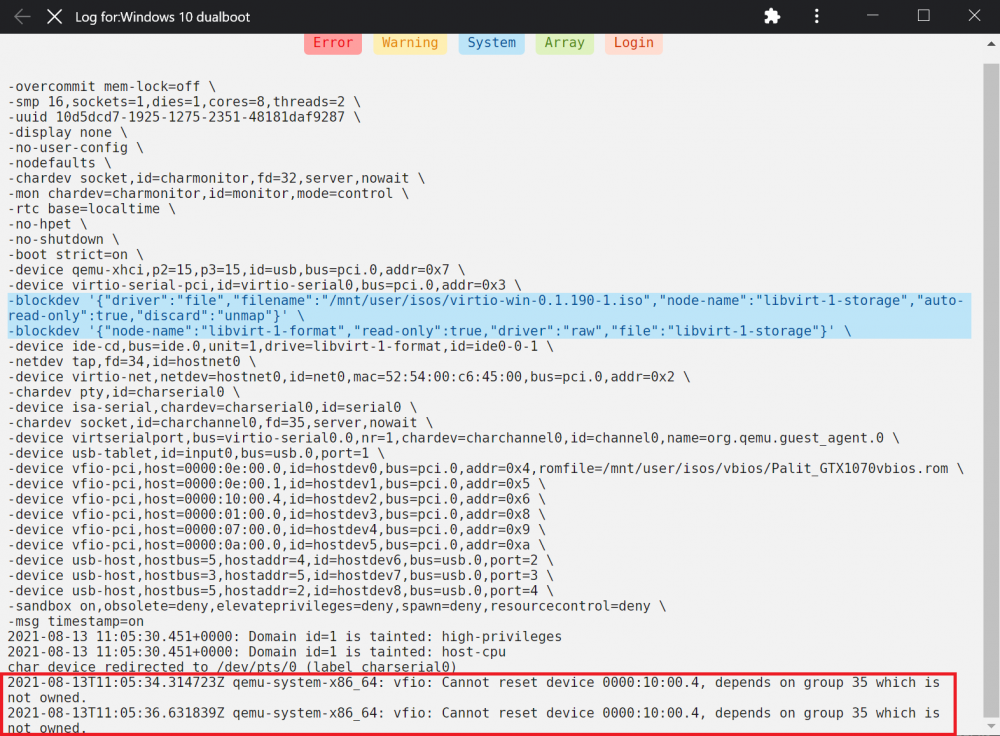
-
On 8/13/2021 at 8:09 AM, gray squirrel said:
So I think that is the usb controller from the cpu. If I remember correctly it sometimes struggles with passthough. On my Systems it locks the server up if I try to use it.
I notice you have another usb controller isolated. As a trouble shooting step can you try testing on that one and seeing if you get the same results?
edit, can as n you post you complete vfio settings.
correct this controller is integrated in the cpu.
the other usb controller is a usb 3.0 gen 1x pcie expansion card attached to the pcie 1x slot and this slot is intergrated to the chipset controller on the motherboard according to the manual.
anyway i did followed your advice and made the same test through this usb 3.0 controller expansion card, speed is only 5gbit but the results were the same last two test.
RND4K Q32T1
RND4K Q1T1
made the win10 vm freeze up a few sec and the external drives was disconnected and reconnected like previous.
-
40 minutes ago, gray squirrel said:
Are you passing the drives or a whole USB controller. Can you show the rest of you template please.
both two external usb 3.2 gen 2 nvme drives are connected to the usb ports for the same controller, passtrough to the vm as per below attached screenshot
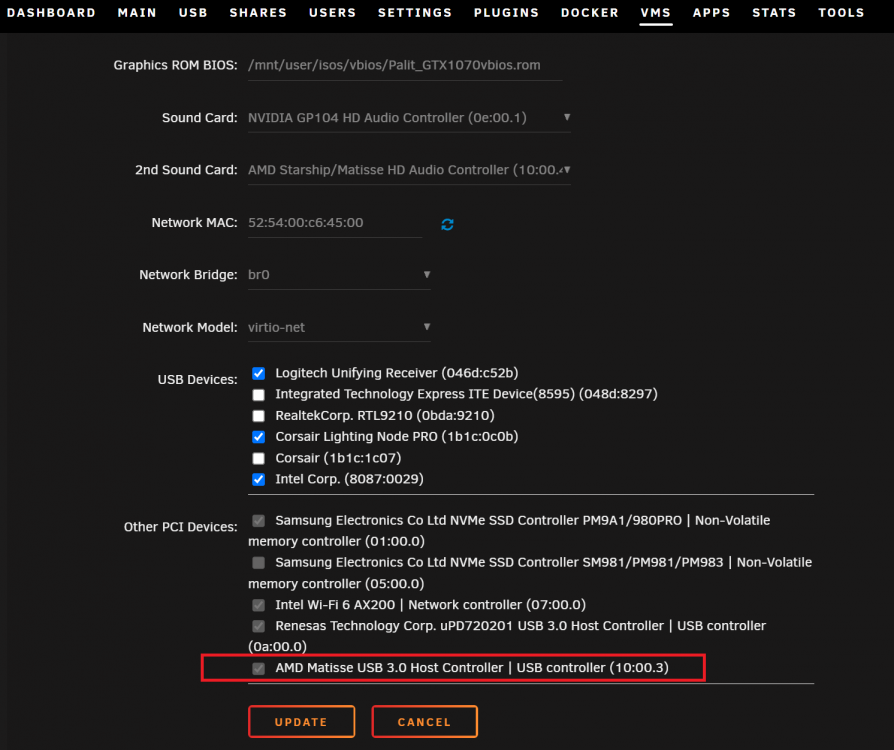
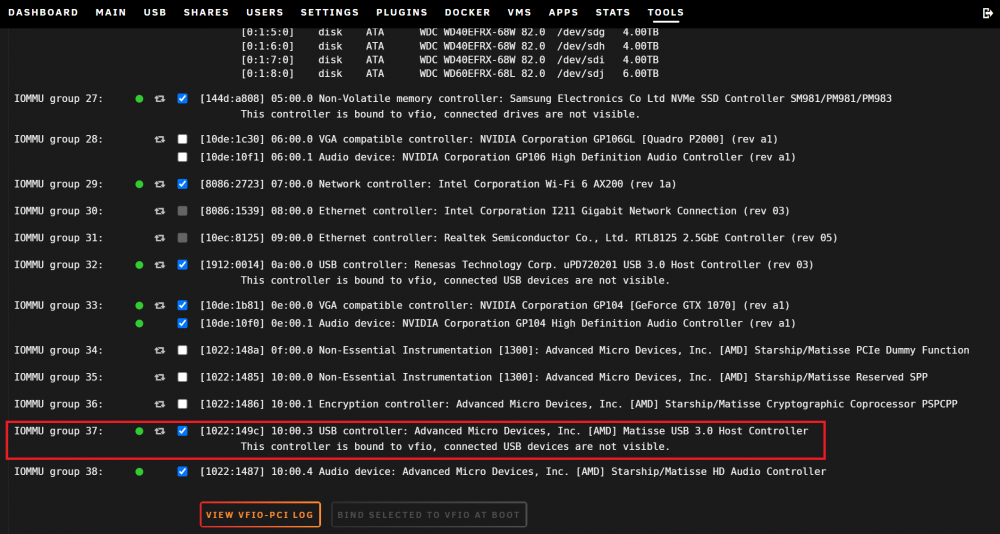
-
42 minutes ago, jbartlett said:
Can you share the error screen? From the list of actions being taken to the error message - no need to include the long java stack, just the error message and where it occurred.
interesting, it looks like i am unable to replicate the error message.
i restarted the docker and the server and now everything is working again.
if it happens again i will post the error message
thx for your reply
-
 1
1
-















2x USB NVMe External Drives, Cache Pool only sees 1x, OS sees both.
in General Support
Posted
It is possible but like @JorgeB replied u will need 2 different usb controllers.
i went the long road and bought 3 pcs of "ORICO-TCM2-C3" https://www.orico.cc/us/product/detail/4039.html"
and then by using the firmware update tool
https://www.station-drivers.com/index.php/en/component/remository/Drivers/Jmicron/JMS583-NVMe-USB-3.1-Controller/Jmicron-JMS-583-NVMe-USB-3.1-Controller-firmware-Version-0.2.0.9/lang,en-gb/
updated the firmware and changed the serial no on each controller, this way all 3 devices was detected in unraid.
you can read more in this thread.
https://forums.anandtech.com/threads/stable-nvme-usb-adapter.2572973/