TIE Fighter
Members
-
Joined
-
Last visited
-
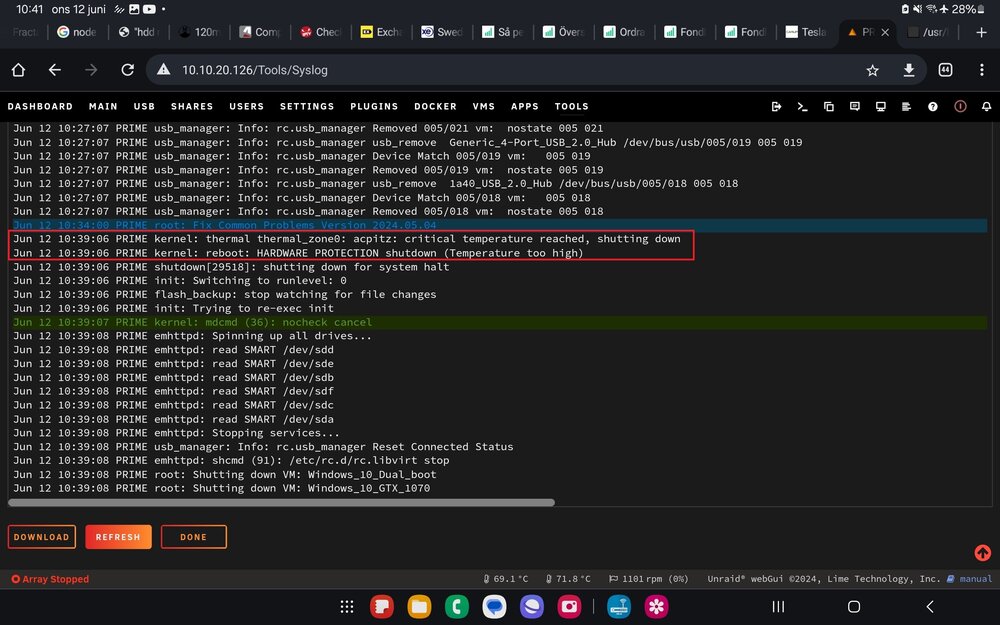
Did some more test gaming and yet again the server auto shutdown due to critical temp reached, this was again after about 40min of gameplay. where do you suggest the "thermal.nocrt=1" ? in terminal, command not found.
-
no "parity check tuning" plugin installed as i do no have a parity drive in the array yet. I disabled the plugin "corefreq" deamon and uninstall the plugin. gamed on both Vm:s for about one hour and no force shutdown yet. however one Vm was crashing with " vfio-pci 0000:4a:00.0: vfio_bar_restore: reset recovery - restoring BARs" in syslog, i did some more readings in the forums and added "pcie_aspm=off" to flash syslinux config file and that seems to solve it. i'll return if critical temp issue persist after more testing.
-
no high temp warnings from any of the drives in a well ventilated game case.
-
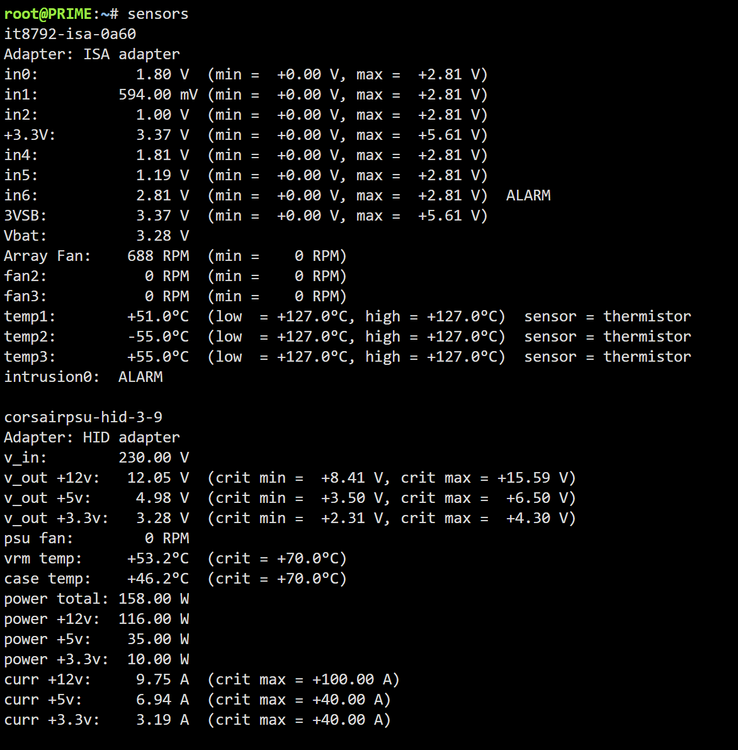
hi all My unraid server with two win 10 vms running is force shutting down and syslog shows warning "critical temperature reached, shutting down" after abt 40min of gameplay testing. cinebench testing on each vm goes without problems. the server was updated recently but i cant remember having this problems before. I'm not sure what the correct way to find the device associated with the thermal_zone0 name is. something in /sys/class/thermal/thermal_zone0 folder? sensors att i have searched for why this is happening but to no avail. any help would be much appreciated syslog att syslog-previous
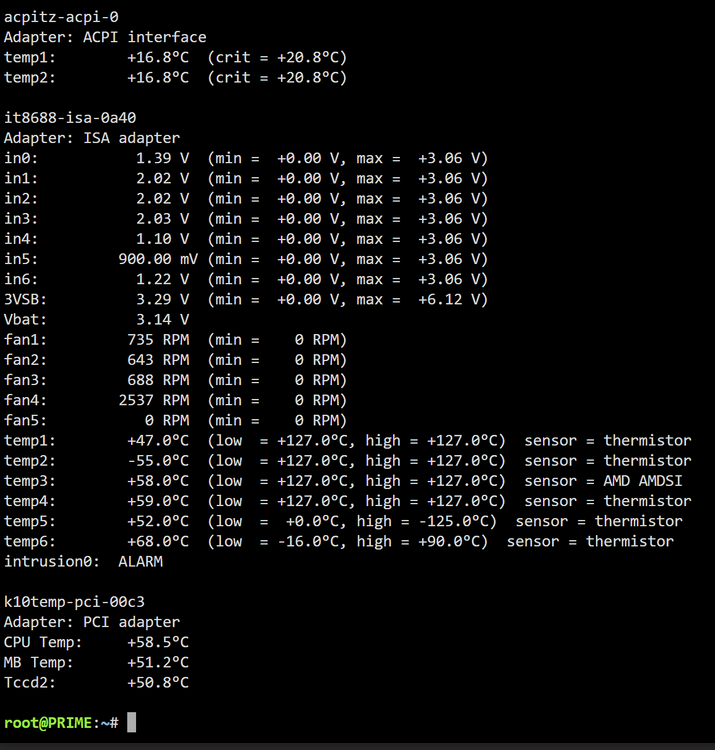
-
It is possible but like @JorgeB replied u will need 2 different usb controllers. i went the long road and bought 3 pcs of "ORICO-TCM2-C3" https://www.orico.cc/us/product/detail/4039.html" and then by using the firmware update tool https://www.station-drivers.com/index.php/en/component/remository/Drivers/Jmicron/JMS583-NVMe-USB-3.1-Controller/Jmicron-JMS-583-NVMe-USB-3.1-Controller-firmware-Version-0.2.0.9/lang,en-gb/ updated the firmware and changed the serial no on each controller, this way all 3 devices was detected in unraid. you can read more in this thread. https://forums.anandtech.com/threads/stable-nvme-usb-adapter.2572973/
-
Same for me aswell s3 sleep plugin do not put the server to sleep. So this is a new setup, Unraid 6.11.5, just installed all the plugins i normaly use and put settings for sleep in the plugin but just realised last night that it doesent go to sleep. Any fix for this? @bonienl megatron-diagnostics-20230410-1659.zip
-
@Flippo +1
-
-
+1 i am in the same situation. my gigabyte X570 AORUS master is lacking support for the fan and temp sensors in unraid and I am looking for a solution to control them in the unraid ui. Can you try and see if you can control them with the plugin and report back?
-
there are 4 on my Radeon RX 6800xt on the bus 10.x.x all passed atleast it is was not a driver issue. infact i found the issue was caused by the S3 sleep plugin. when the plugin didnt pick up any disk activity a sleep command was issued trying to put the server asleep this made the VM crash and sleep was put on hault. my second vm was restarted so that made me think it could also be related to the host, i thought the S3 Sleep plugin would know if any Vms were infact running but it looks like it didnt. to find the ip adress for the VMs i Open unraid terminal and type: arp -a | grep br0 the Vms ip adress to be put to "wait for host inactivity" this made all the issues dissapear 🙂 cheers

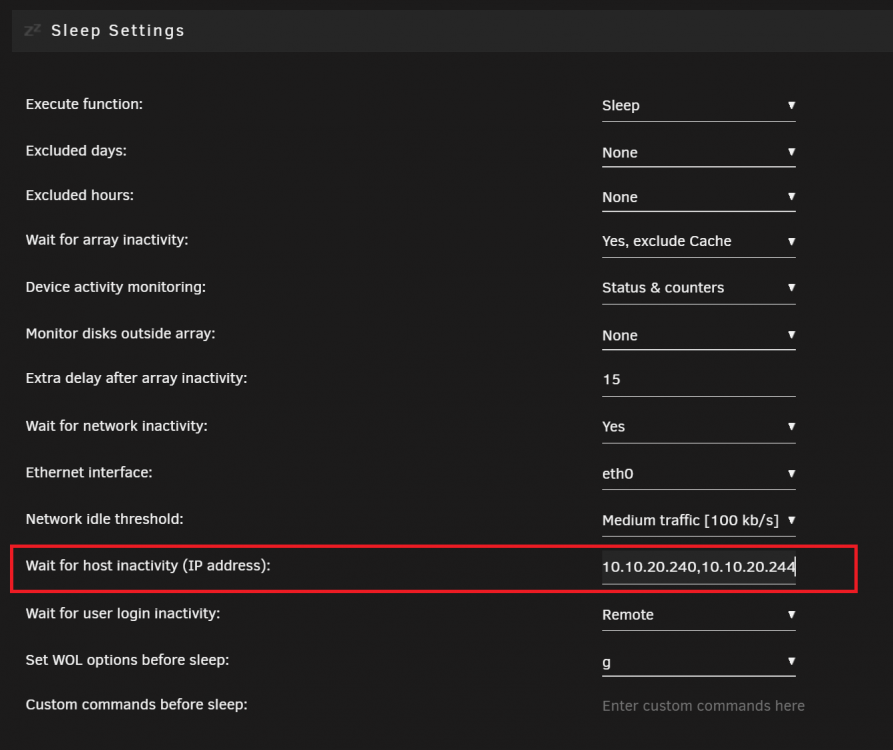
-
thank you very much for the advice and for another great plugin 🙂 passed to a vm as a virtual disk, i'll have a look. cheers.
-
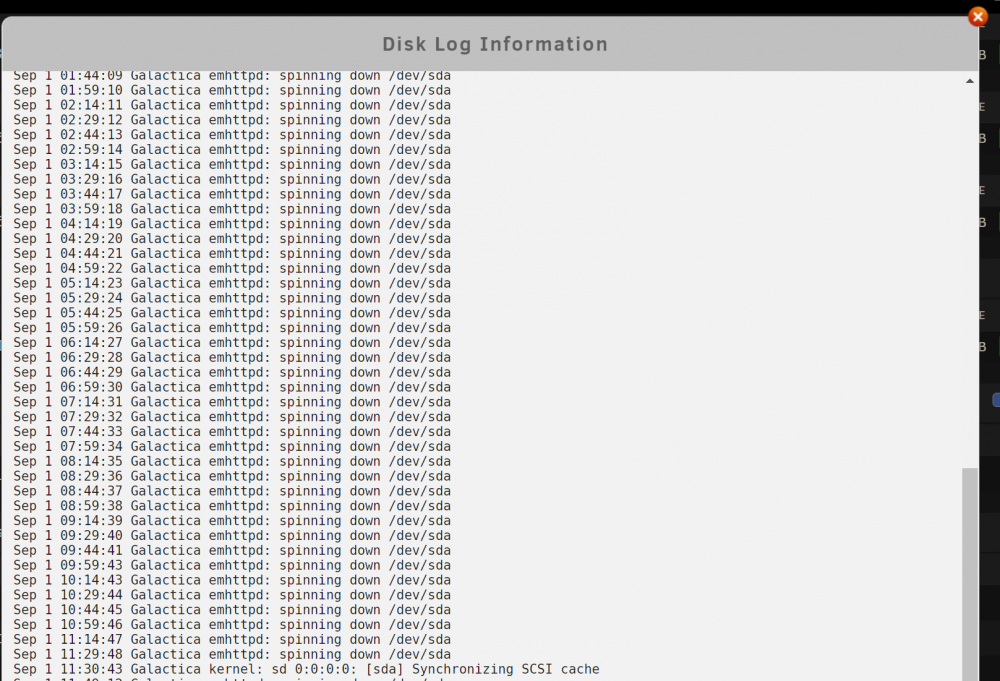
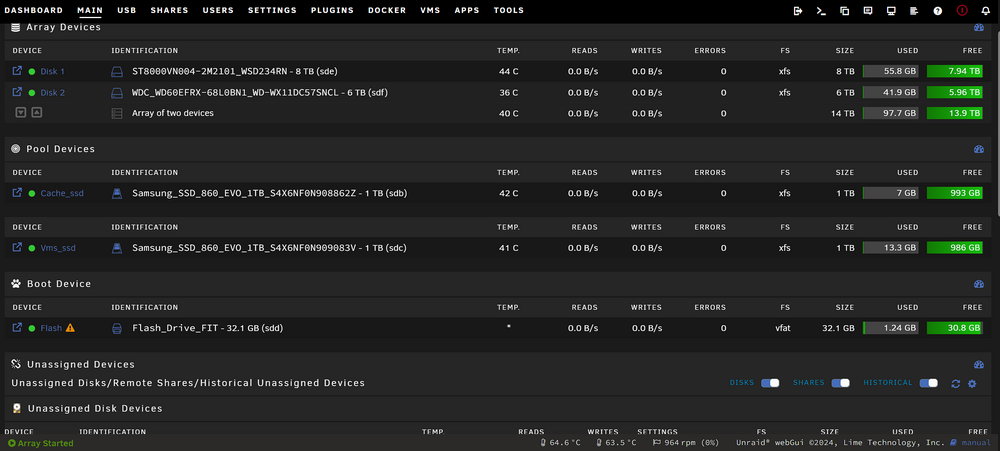
correct the server was rebooted after my first post did not notice the sdX deignation was changed sorry for confusion. see below the timer spin down timer set for 15min. so thats why the disk log is filling up for that particular drive. so unassigned devices do not exclude ssd/nvme drives like unraid is excluding cache drives from spin down? galactica-diagnostics-20210901-2107.zip

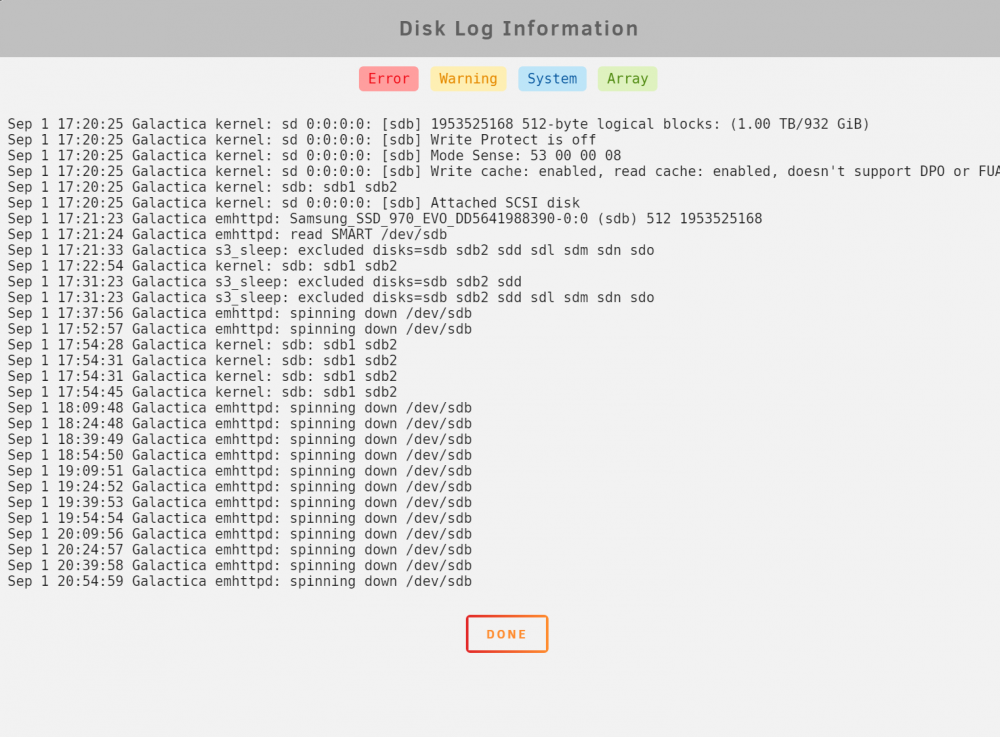
-
please find attached diagnostics. galactica-diagnostics-20210901-1855.zip
-
@trurl parity rebuild completed manually stopped the vms and dockers. one docker was not possible to stop and forced the array to not be put offline. for future knowledge it was a docker that i added from github rep that manage the HBA Card Adaptec 71605. i only use this to monitor the temp of the card. hard rebooted and stopped the docker from autostart. now been trying a cuple of shutdown and reboot attempts and everything seems ok. cheers
-
just want to report some feedback on this awesome plugin. have one usb to nvme disk attached and the disk log fills up with spinning down commands.