




xMaverickx
Members
-
Joined
-
Last visited
Everything posted by xMaverickx
-
Do you mean the port in the wg0.conf file? I changed that and I couldn't get qbit to start. There was no error, but in the logs it referenced the old port number just before it hung.
-
I'm wondering if someone can help me diagnose and solve a problem. I've been using this container for a while with no major issues, but in the last few days speeds have dropped considerably, as if I'm saturating the network fully. I recently upgraded to a 1000/50Mbps capable plan (typical down ~350Mbps), and was getting down speeds of ~28MB/s and up of ~6MB/s which I was happy with. This is through VPN Unlimited, which I've been using for a while on one of their torrent capable servers. The other night, the connection seemed to stop for a few hours and restarting etc made no difference and then came back much slower onm it's own. Now I'm getting 1MB/s down and 1MB/s up consistently, despite healthy torrents, private tracker torrents and official ubuntu torrents which should all be quite fast normally. Adding more healthy torrents makes no difference as if saturated, the new ones run at 25kb/s. Here's what I've tried so far, all of which haven't changed anything: -Restart container -Change protocol from wireguard to openVPN -Change server to other torrent server -Change to non-torrent server (failed) -Changed VPN provider I then speedtested within unraid using speedtest docker, ~400Mbps/40Mbps I then speedtested within console as per SpaceInvader 1. With all torrents paused, 4Mbit/s down, 5.85Mbit/s up With torrents running, I get about 0.1Mbit/s down, indicating the bandwidth is full I then speedtested within console for binhex-deluge (nonVPN) and got 309 and 44.5Mbit/s So it seems the connection is newly being throttled through the VPN, but it isn't specific to that VPN provider. Any ideas what to do next?
-
I downloaded a new wireguard config file from the VPN and now it works. Must have been something that changed on their end. Sorry to waste your time, and thanks for the help.
-
Thanks for the reply, but this didn't work for me, bearing in mind I'm not using PIA if that matters. Same error.
-
Seems to be a wireguard issue. Same thing was happening with delugevpn, and so I changed them both back to openvpn and they are now working.
-
I think I'm having a similar issue to leeroyjenks. Everything was fine when I went to bed, torrents running normally and I didn't change any settings. In the morning I could still access the webui and all torrents were still in the seeding or downloading state, but no data transfer. I restarted and it took a while to load the webui but after 10 minutes or so could log in, same thing. I use VPN unlimited, through wireguard. All worked fine before. It now says I'm firewalled and I get this in the logs: Any ideas? 2021-11-24 12:51:02,395 DEBG 'watchdog-script' stdout output: [info] DNS failure, creating file '/tmp/dnsfailure' to indicate failure... 2021-11-24 12:52:25,685 DEBG 'start-script' stdout output: [info] DNS failure, creating file '/tmp/dnsfailure' to indicate failure... 2021-11-24 12:52:25,687 DEBG 'start-script' stdout output: [info] Attempting to get external IP using 'http://checkip.amazonaws.com'... 2021-11-24 12:52:35,727 DEBG 'start-script' stdout output: [info] Failed on last attempt, attempting to get external IP using 'http://whatismyip.akamai.com'... 2021-11-24 12:52:45,744 DEBG 'start-script' stdout output: [info] Failed on last attempt, attempting to get external IP using 'https://ifconfig.co/ip'... 2021-11-24 12:52:55,762 DEBG 'start-script' stdout output: [info] Failed on last attempt, attempting to get external IP using 'https://showextip.azurewebsites.net'... 2021-11-24 12:53:05,776 DEBG 'start-script' stdout output: [warn] Cannot determine external IP address, performing tests before setting to '127.0.0.1'... [info] Show name servers defined for container 2021-11-24 12:53:05,776 DEBG 'start-script' stdout output: # Generated by resolvconf nameserver 10.100.0.1 2021-11-24 12:53:05,776 DEBG 'start-script' stdout output: [info] Show contents of hosts file 2021-11-24 12:53:05,777 DEBG 'start-script' stdout output: 127.0.0.1 localhost ::1 localhost ip6-localhost ip6-loopback fe00::0 ip6-localnet ff00::0 ip6-mcastprefix ff02::1 ip6-allnodes ff02::2 ip6-allrouters 172.17.0.11 6c1935f9be50 2021-11-24 12:53:05,778 DEBG 'start-script' stdout output: [info] Application does not require port forwarding or VPN provider is != pia, skipping incoming port assignment 2021-11-24 12:53:05,779 DEBG 'start-script' stdout output: [info] WireGuard interface 'up' 2021-11-24 12:53:35,780 DEBG 'start-script' stdout output: [info] Sending 'down' command to WireGuard due to dns failure... 2021-11-24 12:53:35,780 DEBG 'start-script' stdout output: [info] Attempting to bring WireGuard interface 'down'... 2021-11-24 12:53:35,789 DEBG 'start-script' stderr output: Warning: `/config/wireguard/wg0.conf' is world accessible 2021-11-24 12:53:35,798 DEBG 'start-script' stderr output: [#] ip -4 rule delete table 51820 2021-11-24 12:53:35,802 DEBG 'start-script' stderr output: [#] ip -4 rule delete table main suppress_prefixlength 0 2021-11-24 12:53:35,806 DEBG 'start-script' stderr output: [#] ip link delete dev wg0 2021-11-24 12:53:35,861 DEBG 'start-script' stderr output: [#] resolvconf -d wg0 -f 2021-11-24 12:53:35,865 DEBG 'start-script' stderr output: could not detect a useable init system
-
Thanks for replying. I think we are on the right track but it happened again overnight and I got a fix common problems warning this time (OOM), so DLNA not the issue. Always happens at 3am so I think it must be when Plex runs it's scheduled tasks? unRAID Mover runs at 2200. As a bit more background I only have 8Gb RAM (just ordered 8 more), but my system is pretty slim. No VMs, and 12 containers (the usual stuff; Plex, the arrs, duckdns, krusader, delugeVPN, etc). Nothing CURRENTLY using more than 0.03% of RAM. I do have plex hardware transcoding set up to /dev/dri, but I don't believe that would have been running at 3am. I've copied the warnings and errors from overnight below and attached my diagnostics file if that helps. Again, the plex log says it was trying to generate the same thumbnails for 2 old episodes. I wonder if there is an error with this. I've moved the episodes out of the library for now. Do I just need more RAM? Would have thought 8Gb would be adequate, though not beefy. Do I limit the amount of RAM plex can access or does this make it worse? Thank you! Jun 1 02:20:44 BlackBox kernel: CPU: 6 PID: 29792 Comm: unraid-api Not tainted 5.10.28-Unraid #1 Jun 1 02:20:44 BlackBox kernel: Call Trace: Jun 1 02:20:44 BlackBox kernel: out_of_memory+0x3dd/0x410 Jun 1 02:20:44 BlackBox kernel: oom-kill:constraint=CONSTRAINT_NONE,nodemask=(null),cpuset=/,mems_allowed=0,global_oom,task_memcg=/docker/7e8e5c060ae6100a95183b3624127cca31f52022f073c4fcd95231f9cb60bcd9,task=Plex Media Serv,pid=6112,uid=99 Jun 1 02:20:44 BlackBox kernel: Out of memory: Killed process 6112 (Plex Media Serv) total-vm:6483760kB, anon-rss:3703864kB, file-rss:0kB, shmem-rss:4kB, UID:99 pgtables:7528kB oom_score_adj:0 Jun 1 02:41:49 BlackBox kernel: CPU: 5 PID: 29792 Comm: unraid-api Not tainted 5.10.28-Unraid #1 Jun 1 02:41:49 BlackBox kernel: Call Trace: Jun 1 02:41:49 BlackBox kernel: out_of_memory+0x3dd/0x410 Jun 1 02:41:49 BlackBox kernel: oom-kill:constraint=CONSTRAINT_NONE,nodemask=(null),cpuset=/,mems_allowed=0,global_oom,task_memcg=/docker/7e8e5c060ae6100a95183b3624127cca31f52022f073c4fcd95231f9cb60bcd9,task=Plex Media Serv,pid=7547,uid=99 Jun 1 02:41:49 BlackBox kernel: Out of memory: Killed process 7547 (Plex Media Serv) total-vm:6427644kB, anon-rss:3788660kB, file-rss:0kB, shmem-rss:4kB, UID:99 pgtables:7644kB oom_score_adj:0 Jun 1 03:02:51 BlackBox kernel: CPU: 3 PID: 20694 Comm: Plex Media Serv Not tainted 5.10.28-Unraid #1 Jun 1 03:02:51 BlackBox kernel: Call Trace: Jun 1 03:02:51 BlackBox kernel: out_of_memory+0x3dd/0x410 Jun 1 03:02:51 BlackBox kernel: oom-kill:constraint=CONSTRAINT_NONE,nodemask=(null),cpuset=7e8e5c060ae6100a95183b3624127cca31f52022f073c4fcd95231f9cb60bcd9,mems_allowed=0,global_oom,task_memcg=/docker/7e8e5c060ae6100a95183b3624127cca31f52022f073c4fcd95231f9cb60bcd9,task=Plex Media Serv,pid=22324,uid=99 Jun 1 03:02:51 BlackBox kernel: Out of memory: Killed process 22324 (Plex Media Serv) total-vm:6420672kB, anon-rss:3782076kB, file-rss:0kB, shmem-rss:4kB, UID:99 pgtables:7700kB oom_score_adj:0 Jun 1 04:21:03 BlackBox root: Fix Common Problems: Error: Out Of Memory errors detected on your server blackbox-diagnostics-20210601-0902.zip
-
Hi all, I'm having an issue where overnight sometimes plex will become unresponsive in the morning, i.e. TV, phone won't connect to server and webUI won't load (Error Connection time out). It fixes itself temporarily with a restart of the container. In the container log, this repeats a few times, so it seems to be trying to repeatedly get thumbnails for 2 old show episodes I've had for a long time: --- 2021-05-29 02:26:35,175 DEBG 'plexmediaserver' stdout output: Generated new chapter thumbnails for Wicks. 2021-05-29 02:26:35,586 DEBG 'plexmediaserver' stdout output: Generated new chapter thumbnails for Behold a Pale Rider. 2021-05-29 02:41:23,123 DEBG fd 8 closed, stopped monitoring <POutputDispatcher at 22907605937744 for <Subprocess at 22907605937648 with name plexmediaserver in state RUNNING> (stdout)> 2021-05-29 02:41:23,177 DEBG fd 12 closed, stopped monitoring <POutputDispatcher at 22907605709968 for <Subprocess at 22907605937648 with name plexmediaserver in state RUNNING> (stderr)> 2021-05-29 02:41:23,177 INFO exited: plexmediaserver (terminated by SIGKILL; not expected) 2021-05-29 02:41:23,178 DEBG received SIGCHLD indicating a child quit 2021-05-29 02:41:23,426 INFO spawned: 'plexmediaserver' with pid 9091 2021-05-29 02:41:24,427 INFO success: plexmediaserver entered RUNNING state, process has stayed up for > than 1 seconds (startsecs) 2021-05-29 02:41:42,244 DEBG 'plexmediaserver' stdout output: Critical: libusb_init failed --- But this didn't seem critical to me so I looked at the Plex Media Server.log and the only Errors are below: --- May 30, 2021 03:05:38.306 [0x152fe9715b38] ERROR - Error issuing curl_easy_perform(handle): 28 May 30, 2021 03:06:31.309 [0x152fe906cb38] ERROR - Error issuing curl_easy_perform(handle): 28 May 30, 2021 03:06:31.309 [0x152fe906cb38] ERROR - SSDP: Error parsing device schema for http://192.168.0.16:9080 May 30, 2021 04:05:38.672 [0x152fe9a0fb38] ERROR - Error issuing curl_easy_perform(handle): 28 May 30, 2021 04:40:11.641 [0x152fe906cb38] ERROR - Network Service: Error in browser handle read: 125 (Operation canceled) socket=-1 May 30, 2021 04:40:11.741 [0x152fe906cb38] ERROR - Network Service: Error in browser handle read: 125 (Operation canceled) socket=-1 May 30, 2021 04:40:11.841 [0x152fe906cb38] ERROR - Network Service: Error in browser handle read: 125 (Operation canceled) socket=-1 May 30, 2021 04:40:11.941 [0x152fe906cb38] ERROR - Network Service: Error in browser handle read: 125 (Operation canceled) socket=-1 May 30, 2021 04:40:12.041 [0x152fe906cb38] ERROR - Network Service: Error in browser handle read: 125 (Operation canceled) socket=-1 May 30, 2021 04:40:12.141 [0x152fe906cb38] ERROR - Network Service: Error in browser handle read: 125 (Operation canceled) socket=-1 May 30, 2021 04:40:12.242 [0x152fe906cb38] ERROR - Network Service: Error in browser handle read: 125 (Operation canceled) socket=-1 May 30, 2021 04:40:13.625 [0x152fe906cb38] ERROR - Network Service: Error in browser handle read: 125 (Operation canceled) socket=-1 May 30, 2021 04:40:13.725 [0x152fe906cb38] ERROR - Network Service: Error in browser handle read: 125 (Operation canceled) socket=-1 May 30, 2021 04:40:13.826 [0x152fe906cb38] ERROR - Network Service: Error in browser handle read: 125 (Operation canceled) socket=-1 May 30, 2021 04:40:13.926 [0x152fe906cb38] ERROR - Network Service: Error in browser handle read: 125 (Operation canceled) socket=-1 May 30, 2021 04:40:14.026 [0x152fe906cb38] ERROR - Network Service: Error in browser handle read: 125 (Operation canceled) socket=-1 May 30, 2021 04:40:14.126 [0x152fe906cb38] ERROR - Network Service: Error in browser handle read: 125 (Operation canceled) socket=-1 May 30, 2021 04:40:14.227 [0x152fe906cb38] ERROR - Network Service: Error in browser handle read: 125 (Operation canceled) socket=-1 May 30, 2021 04:40:18.811 [0x152fe9643b38] ERROR - Error issuing curl_easy_perform(handle): 28 May 30, 2021 05:05:38.833 [0x152fe9a0fb38] ERROR - Error issuing curl_easy_perform(handle): 28 May 30, 2021 06:05:38.979 [0x152fe9643b38] ERROR - Error issuing curl_easy_perform(handle): 28 May 30, 2021 07:05:39.190 [0x152fe9a0fb38] ERROR - Error issuing curl_easy_perform(handle): 28 May 30, 2021 08:05:39.488 [0x152fe9a0fb38] ERROR - Error issuing curl_easy_perform(handle): 28 May 30, 2021 08:48:39.895 [0x152fe906cb38] ERROR - Error issuing curl_easy_perform(handle): 28 May 30, 2021 08:48:39.895 [0x152fe906cb38] ERROR - SSDP: Error parsing device schema for http://192.168.0.3:2870/dmr.xml --- Nothing jumping out at me as an obvious problem. Not getting database corruption notifications on my plex phone app as I have had in the past but fixed. Any ideas? Edit: Found this in the unRAID log: May 30 03:05:27 BlackBox kernel: Call Trace: May 30 03:05:27 BlackBox kernel: out_of_memory+0x3dd/0x410 May 30 03:05:27 BlackBox kernel: Out of memory: Killed process 9564 (Plex Media Serv) total-vm:6431820kB, anon-rss:3845312kB, file-rss:0kB, shmem-rss:4kB, UID:99 pgtables:7788kB oom_score_adj:0 Is this the culprit? I recently turned DLNA on for no good reason, which apparently can cause memory leak. I've turned it off now.
-
Tried both of those things and no change.
-
Would someone be able to help me install 3rd party plugins? Or are they just still broken as I have read previously? I have the latest unRAID and container. Installing from the plugin menu is broken, never had that working. So I tried dropping the egg in to the plugin folder (specifically LabelPlus and AutoRemovePlus), both py2.6 and py2.7 versions. They weren't recognized by the plugin menu, even after a restart. Clicking install creates a [File ObjectList] file in the plugin folder which does nothing. So I did some reading, and figured the python versions were out of sync, and I read that someone recompiled it from the plugin source, so I did that and now I have new egg files with py3.9. Getting closer, these can now be recognized in the plugin menu. When I try to check them, they tick, and then I click apply and/or OK, but nothing happens, and I go immediately back into the menu and they are unticked. Won't stay put. I tried adding them to the conf manually, but this does nothing. Any other ideas? Thanks in advance.
-
No worries, thanks for trying. For the time being, in case anyone else has a similar issue, I've set up a custom user script using the user scripts plugin that just says "docker restart qbittorrentvpn" and have it set to run daily.
-
So it just happened again for the first time since your post. I tested connectivity with your idea and it seems to be fine, same as it says when it is working. I'm not sure Rebuild-DNDC will fix it because as far as I can tell that rebuild dependencies between different containers, but this is all within one. I may be misunderstanding it though. I've left it broken in case anyone has any ideas for testing. Does it have to do with this line in the qb container log? [info] qBittorrent listening interface IP x.x.x.x and VPN provider IP x.x.x.y different, marking for reconfigure or this one? Sat Jul 25 02:17:58 2020 [openvpn2.vpnunlimitedapp.com] Inactivity timeout (--ping-exit), exiting
-
Hi all, I'm having an issue with qbittorrentvpn where after a couple of days of running fine, new torrents will add to the list (for example automatically added via sonarr, but can be manual as well) but won't start downloading or even download the metadata. If I restart the docker container, it then starts normally. I'm pretty sure existing seeds will continue to periodically upload. The logs mention an inactivity timeout, and I wonder whether this is related. So my questions are, does anyone else have this problem, and is anyone aware of a solution? Or, if not, could someone help me with a script that restarts qbittorentvpn every 24 hours or so? Thanks!
-
That did it. Thanks for the help!
-
Ok, great. I use NPM as well, so in theory this should work for me as well, but I edited the proxy host in NPM and copy and pasted exactly what you wrote above in the custom configuration and nothing seemed to change. I checked the config file directly as well and the code is there. Not sure why. Any ideas? Many thanks for helping.
-
A reverse proxy file doesn't sound familiar, so we probably have it set up differently. Would you be able to elaborate further on how you did that?
-
I had the exact same issue. I tried creating a new path /theme/ in the container template pointing to a theme folder and had the same outcome. Has anyone got this to work?
-
Is there any way to change the serial number of a drive in the array or unassigned drives? I have an 8 bay USB-C enclosure with 4 drives in array and 4 free drives in unassigned that I want to preclear and have ready to add. Unfortunately the drivers of the enclosure or something override the drive serial numbers and the drive identification so the ID for each drive is JMicron_Generic_DISK00_0123456789ABCDEF-0:0 - 10 TB (sda), then DISK01, etc. I can preclear one of the unassigned drives, but if I try to do a second one it tries to do the first again because the serial numbers are doctored and the same for all the drives even though the other details are different, for example: Model Family: Seagate Desktop HDD.15 Device Model: ST4000DM000-1F2168 Serial Number: 0123456789ABCDEF Firmware Version: CC54 Size: 4 TB Can anyone think of a way around it? Otherwise I'll just wait until I add the precleared one, then I'll start preclearing the next one. Thanks!
-
Yep, I bit the bullet and cancelled the parity build that had been going for 2 days (that was hard) and plugged in the old USB-C to USB-A 3.0 cable and it's going 10x faster. Thanks a lot for your help. How can I send you some beer money?
-
It's a USB-C to USB-C cable, but I can't remember where I got it from, so maybe it's a cheap one... We may be on the right track because when it was working better with the old computer it was a different USB-C to USB-A cable. I just assumed a USB-C to USB-C cable would automatically be USB 3.1 and better. When my new cable comes I'll report back. I don't know why the drives all are JMicron. They were like that on windows as well and I guess it's a product of the enclosure. If I move the same drives to a different 2 bay dock they show up as their proper serials. It's annoying because I can't initiate a SMART test on them, since it says they aren't spun up, but they work and do self tests periodically.
-
Very close, it's the NS800C3 (http://my.orico.cc/goods.php?id=6531), basically the same but USB C instead of B. The NUC has Thunderbolt capability, so I thought in theory it should get decent speeds, 5Gbps for both ends. Again, I'm aware USB isn't the most stable, but I've protected the ports as much as possible now, and I had been using it with Windows and Drivepool for a while with no major issues, and can't afford to change all my hardware. Also, it worked well on the old Acer, so I'm not sure if it is something to do with the NUC or something to do with the cable. I'm not certain of the capability of the cable, so I ordered a Thunderbolt 3 cable with 40Gbps capability to eliminate that as a factor. Sorry for the confusion about the rebuilds. I've tried a few different things in the last couple of weeks. Initially, just a repair of the disabled drive from parity, but that was taking days to complete and when it was almost done got knocked again (I've since sorted that out). When I tried again it estimated 44 days to rebuild, so I cancelled thinking the drive was screwed, copied the emulated data to another external drive outside the array and did a new config without that drive and another empty 2Tb drive which had increasing errors, and am now rebuilding the parity with 5 hopefully healthy data drives. I'll attach a screenshot of my main page. The drives all seem to be independent with individual bare metal access. The total array Read Speed stays fairly constant between 30-35Mbps, but the individual disks Read Speed can change depending on how many are being used to calculate parity, i.e. if the 2Tbs aren't used, the remaining 3 drives will be 9-10Mbs and if the 4Tbs are out the 10Tb will do 30-35Mbps. The write speed on the parity will be the same as any individual drive. I don't blame you for struggling to get your head around it, since I still can't either. Is it possible something about the NUC isn't playing well with unRAID since the Acer used to work? Thanks so much for looking at this, I'll definitely buy you a beer if you can solve it (or even if you give it a crack!)
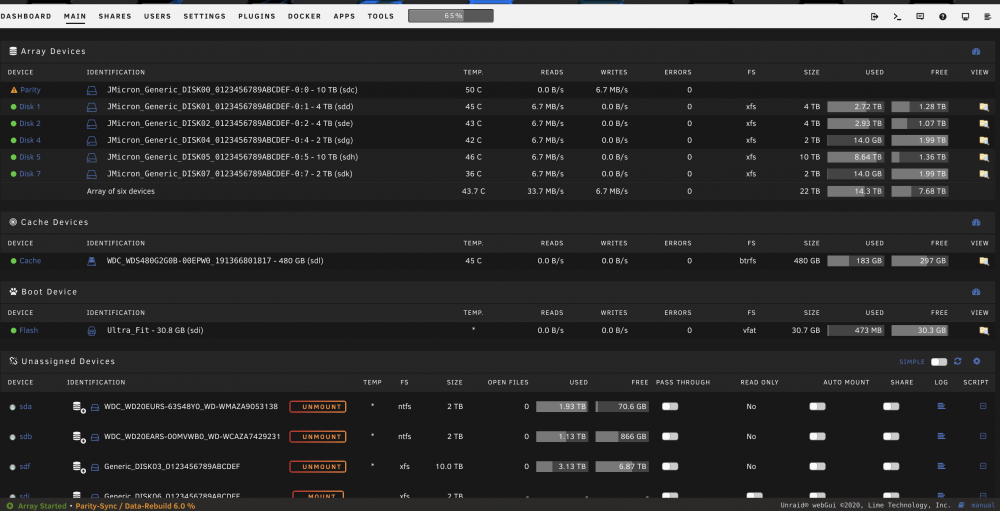
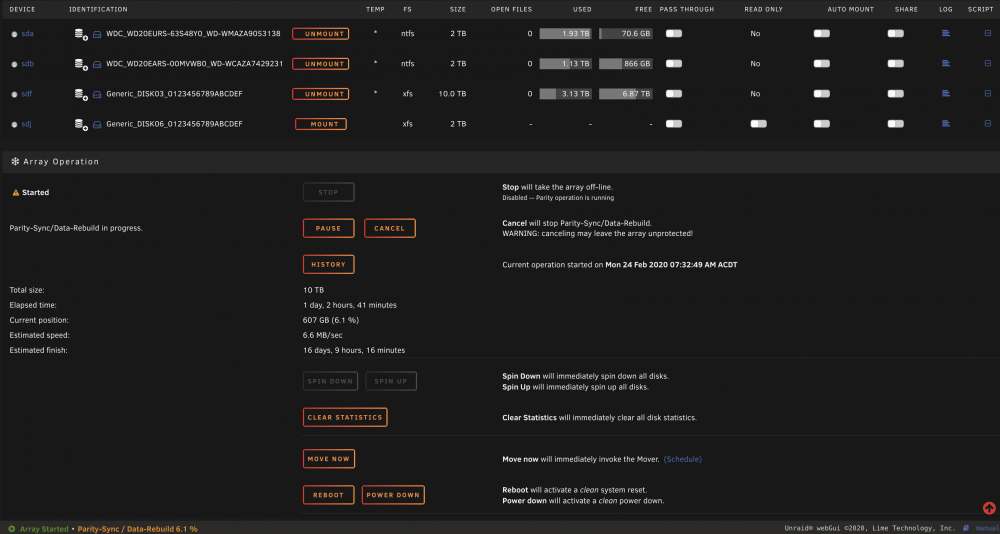
-
Hi All, Sorry if this is stupid or obvious, but I'm having some trouble figuring it out. I'm pretty new to unRAID. I've had a series of issues, but the main current issue is that my parity build is going really slowly. Hardware: Recently changed from an old 2013 Revo Aspire PC connected to an 8 bay Orico drive with a USB-C to USB-A cable to an 8th gen Intel NUC i5 with USB-C to USB-C cable hoping to make everything run a bit snappier since the CPU was always maxed out. (I know external enclosures are not recommended, but that's what I had). I had a set of drives including 1x 10Tb parity, and 2x 10Tb, 2x 4Tb and 3x 2Tb data drives. With the NUC I bought a 480Gb SSD to use as cache, was cacheless before that. Initially things were fine, then the enclosure was unplugged during a data write and a 10Tb drive was disabled. I was reasonably convinced that it wasn't damaged, so I unassigned it and reassigned it for a rebuild. This was taking forever. It seemed the total read speed of the array stays constant at about 30-35Mb/s, so each drive will read at about 6Mb/s and the data drive would write at 6Mb/s. Once the 2Tbs are out of the way the remaining drives go up to 8-9Mb/s and once the 4Tbs are done the 10Tbs go at 18-19Mb/s. It got to 99.6% complete and my son threw a toy behind the TV and it unplugged again Hence why external enclosures aren't recommended. I then tried to do a SMART test on the drive, but even though the drives are active and working, none of the drives in the Orico enclosure appear spun up so they won't test. I think because they all get listed as JMicron Generic 0-7 instead of their actual model WD__ etc. So I copied the emulated data off disk3 (10Tb disabled drive) and did a new config and am now rebuilding the parity, thinking that maybe that drive was faulty and slowing things down, but am getting the same thing. Currently, the rebuild has been active for 16 hours, is 3.7% complete and has about 16 days to go. Oddly on the old Revo with the same drives, I would build parity in around 22 hours or so, which seemed normal. Why would the new system be slower? It's all a bit of a mess. Can anyone help clarify where the bottleneck in this system is? I've attached my diagnostics file. I'm sure I've left out some crucial information, so just let me know what I can do to help. Thanks! blackbox-diagnostics-20200224-2248.zip
-
Well, that was easy. Next time I'll just follow the directions on the box! Thanks for your help!
-
Sorry for my ignorance, I'm new to unraid and have only minor Linux experience in general. I saw that line and googled it but couldn't find anything useful so I thought I'd ask before I effed anything up. Do I just type /sbin/modprobe iptable_mangle into the terminal?
-
I'm newly having this issue as well, while trying to access your qbittorrentvpn container outside of my LAN (I know this is the wrong thread, but it seems like the same issue). Not exactly sure when it started, in the last few days though. Seems ok in-house. I deleted the container and the config for a fresh install and same thing. Any help would be greatly appreciated. Here is the log with UN and PW deleted. ErrorWarningSystemArrayLogin Created by... ___. .__ .__ \_ |__ |__| ____ | |__ ____ ___ ___ | __ \| |/ \| | \_/ __ \\ \/ / | \_\ \ | | \ Y \ ___/ > < |___ /__|___| /___| /\___ >__/\_ \ \/ \/ \/ \/ \/ https://hub.docker.com/u/binhex/ 2020-01-24 18:31:49.453085 [info] System information Linux e96e13216ead 4.19.94-Unraid #1 SMP Thu Jan 9 08:20:36 PST 2020 x86_64 GNU/Linux 2020-01-24 18:31:49.539095 [info] PUID defined as '99' 2020-01-24 18:31:49.863142 [info] PGID defined as '100' 2020-01-24 18:31:50.269281 [info] UMASK defined as '000' 2020-01-24 18:31:50.317676 [info] Setting permissions recursively on volume mappings... 2020-01-24 18:31:50.959110 [info] VPN_ENABLED defined as 'yes' 2020-01-24 18:31:51.077181 [crit] No OpenVPN config file located in /config/openvpn/ (ovpn extension), please download from your VPN provider and then restart this container, exiting... Created by... ___. .__ .__ \_ |__ |__| ____ | |__ ____ ___ ___ | __ \| |/ \| | \_/ __ \\ \/ / | \_\ \ | | \ Y \ ___/ > < |___ /__|___| /___| /\___ >__/\_ \ \/ \/ \/ \/ \/ https://hub.docker.com/u/binhex/ 2020-01-24 18:34:41.613955 [info] System information Linux e96e13216ead 4.19.94-Unraid #1 SMP Thu Jan 9 08:20:36 PST 2020 x86_64 GNU/Linux 2020-01-24 18:34:41.663126 [info] PUID defined as '99' 2020-01-24 18:34:41.715391 [info] PGID defined as '100' 2020-01-24 18:34:41.873169 [info] UMASK defined as '000' 2020-01-24 18:34:41.921989 [info] Permissions already set for volume mappings 2020-01-24 18:34:41.990786 [info] VPN_ENABLED defined as 'yes' 2020-01-24 18:34:42.049963 [info] OpenVPN config file (ovpn extension) is located at /config/openvpn/0C0F5FC9-9A21-4E8F-ADF4-78C22D53E726_us-sf_openvpn.ovpn 2020-01-24 18:34:42.157148 [info] VPN remote line defined as 'remote us-sf.vpnunlimitedapp.com 1194' 2020-01-24 18:34:42.208023 [info] VPN_REMOTE defined as 'us-sf.vpnunlimitedapp.com' 2020-01-24 18:34:42.259106 [info] VPN_PORT defined as '1194' 2020-01-24 18:34:42.313931 [info] VPN_PROTOCOL defined as 'udp' 2020-01-24 18:34:42.363237 [info] VPN_DEVICE_TYPE defined as 'tun0' 2020-01-24 18:34:42.413479 [info] VPN_PROV defined as 'custom' 2020-01-24 18:34:42.477205 [info] LAN_NETWORK defined as '192.168.0.0/24' 2020-01-24 18:34:42.527449 [info] NAME_SERVERS defined as '209.222.18.222,84.200.69.80,37.235.1.174,1.1.1.1,209.222.18.218,37.235.1.177,84.200.70.40,1.0.0.1' 2020-01-24 18:34:42.576336 [info] VPN_USER defined as 'xxxxxx' 2020-01-24 18:34:42.624870 [info] VPN_PASS defined as 'xxxxxx' 2020-01-24 18:34:42.678636 [info] VPN_OPTIONS not defined (via -e VPN_OPTIONS) 2020-01-24 18:34:42.727447 [info] ENABLE_PRIVOXY defined as 'no' 2020-01-24 18:34:42.776571 [info] WEBUI_PORT defined as '8080' 2020-01-24 18:34:42.865980 [info] Deleting files in /tmp (non recursive)... 2020-01-24 18:34:42.912344 [info] Starting Supervisor... 2020-01-24 18:34:44,716 INFO Included extra file "/etc/supervisor/conf.d/qbittorrent.conf" during parsing 2020-01-24 18:34:44,717 INFO Set uid to user 0 succeeded 2020-01-24 18:34:44,722 INFO supervisord started with pid 6 2020-01-24 18:34:45,725 INFO spawned: 'start-script' with pid 152 2020-01-24 18:34:45,728 INFO spawned: 'watchdog-script' with pid 153 2020-01-24 18:34:45,729 INFO reaped unknown pid 7 2020-01-24 18:34:45,738 DEBG 'start-script' stdout output: [info] VPN is enabled, beginning configuration of VPN 2020-01-24 18:34:45,739 INFO success: start-script entered RUNNING state, process has stayed up for > than 0 seconds (startsecs) 2020-01-24 18:34:45,739 INFO success: watchdog-script entered RUNNING state, process has stayed up for > than 0 seconds (startsecs) 2020-01-24 18:34:45,740 DEBG 'watchdog-script' stdout output: [info] qBittorrent config file doesnt exist, copying default to /config/qBittorrent/config/... 2020-01-24 18:34:45,754 DEBG 'start-script' stdout output: [warn] Username contains characters which could cause authentication issues, please consider changing this if possible 2020-01-24 18:34:45,759 DEBG 'start-script' stdout output: [warn] Password contains characters which could cause authentication issues, please consider changing this if possible 2020-01-24 18:34:45,778 DEBG 'watchdog-script' stdout output: [info] Removing session lock file (if it exists)... 2020-01-24 18:34:45,842 DEBG 'start-script' stdout output: [info] Default route for container is 172.17.0.1 2020-01-24 18:34:45,847 DEBG 'start-script' stdout output: [info] Adding 209.222.18.222 to /etc/resolv.conf 2020-01-24 18:34:45,852 DEBG 'start-script' stdout output: [info] Adding 84.200.69.80 to /etc/resolv.conf 2020-01-24 18:34:45,857 DEBG 'start-script' stdout output: [info] Adding 37.235.1.174 to /etc/resolv.conf 2020-01-24 18:34:45,862 DEBG 'start-script' stdout output: [info] Adding 1.1.1.1 to /etc/resolv.conf 2020-01-24 18:34:45,866 DEBG 'start-script' stdout output: [info] Adding 209.222.18.218 to /etc/resolv.conf 2020-01-24 18:34:45,871 DEBG 'start-script' stdout output: [info] Adding 37.235.1.177 to /etc/resolv.conf 2020-01-24 18:34:45,876 DEBG 'start-script' stdout output: [info] Adding 84.200.70.40 to /etc/resolv.conf 2020-01-24 18:34:45,881 DEBG 'start-script' stdout output: [info] Adding 1.0.0.1 to /etc/resolv.conf 2020-01-24 18:35:00,991 DEBG 'start-script' stdout output: [info] Attempting to load iptable_mangle module... 2020-01-24 18:35:00,993 DEBG 'start-script' stderr output: modprobe: FATAL: Module iptable_mangle not found in directory /lib/modules/4.19.94-Unraid 2020-01-24 18:35:00,993 DEBG 'start-script' stdout output: [warn] Unable to load iptable_mangle module using modprobe, trying insmod... 2020-01-24 18:35:00,995 DEBG 'start-script' stderr output: insmod: ERROR: could not load module /lib/modules/iptable_mangle.ko: No such file or directory 2020-01-24 18:35:00,995 DEBG 'start-script' stdout output: [warn] Unable to load iptable_mangle module, you will not be able to connect to the applications Web UI or Privoxy outside of your LAN [info] unRAID/Ubuntu users: Please attempt to load the module by executing the following on your host: '/sbin/modprobe iptable_mangle' [info] Synology users: Please attempt to load the module by executing the following on your host: 'insmod /lib/modules/iptable_mangle.ko' 2020-01-24 18:35:01,044 DEBG 'start-script' stdout output: [info] Docker network defined as 172.17.0.0/16 2020-01-24 18:35:01,049 DEBG 'start-script' stdout output: [info] Adding 192.168.0.0/24 as route via docker eth0 2020-01-24 18:35:01,051 DEBG 'start-script' stdout output: [info] ip route defined as follows... -------------------- 2020-01-24 18:35:01,053 DEBG 'start-script' stdout output: default via 172.17.0.1 dev eth0 172.17.0.0/16 dev eth0 proto kernel scope link src 172.17.0.2 192.168.0.0/24 via 172.17.0.1 dev eth0 2020-01-24 18:35:01,053 DEBG 'start-script' stdout output: -------------------- 2020-01-24 18:35:01,158 DEBG 'start-script' stdout output: [info] iptables defined as follows... -------------------- 2020-01-24 18:35:01,160 DEBG 'start-script' stdout output: -P INPUT DROP -P FORWARD DROP -P OUTPUT DROP -A INPUT -s 172.17.0.0/16 -d 172.17.0.0/16 -j ACCEPT -A INPUT -i eth0 -p udp -m udp --sport 1194 -j ACCEPT -A INPUT -i eth0 -p tcp -m tcp --dport 8080 -j ACCEPT -A INPUT -i eth0 -p tcp -m tcp --sport 8080 -j ACCEPT -A INPUT -s 192.168.0.0/24 -i eth0 -p tcp -m tcp --dport 8080 -j ACCEPT -A INPUT -p icmp -m icmp --icmp-type 0 -j ACCEPT -A INPUT -i lo -j ACCEPT -A INPUT -i tun0 -j ACCEPT -A OUTPUT -s 172.17.0.0/16 -d 172.17.0.0/16 -j ACCEPT -A OUTPUT -o eth0 -p udp -m udp --dport 1194 -j ACCEPT -A OUTPUT -o eth0 -p tcp -m tcp --dport 8080 -j ACCEPT -A OUTPUT -o eth0 -p tcp -m tcp --sport 8080 -j ACCEPT -A OUTPUT -d 192.168.0.0/24 -o eth0 -p tcp -m tcp --sport 8080 -j ACCEPT -A OUTPUT -p icmp -m icmp --icmp-type 8 -j ACCEPT -A OUTPUT -o lo -j ACCEPT -A OUTPUT -o tun0 -j ACCEPT 2020-01-24 18:35:01,162 DEBG 'start-script' stdout output: -------------------- 2020-01-24 18:35:01,164 DEBG 'start-script' stdout output: [info] Starting OpenVPN... 2020-01-24 18:35:01,394 DEBG 'start-script' stdout output: Fri Jan 24 18:35:01 2020 WARNING: file 'credentials.conf' is group or others accessible Fri Jan 24 18:35:01 2020 OpenVPN 2.4.8 [git:makepkg/3976acda9bf10b5e+] x86_64-pc-linux-gnu [SSL (OpenSSL)] [LZO] [LZ4] [EPOLL] [PKCS11] [MH/PKTINFO] [AEAD] built on Jan 3 2020 Fri Jan 24 18:35:01 2020 library versions: OpenSSL 1.1.1d 10 Sep 2019, LZO 2.10 2020-01-24 18:35:01,395 DEBG 'start-script' stdout output: [info] OpenVPN started 2020-01-24 18:35:01,395 DEBG 'start-script' stdout output: Fri Jan 24 18:35:01 2020 NOTE: the current --script-security setting may allow this configuration to call user-defined scripts 2020-01-24 18:35:01,403 DEBG 'start-script' stdout output: Fri Jan 24 18:35:01 2020 TCP/UDP: Preserving recently used remote address: [AF_INET]209.58.135.108:1194 Fri Jan 24 18:35:01 2020 UDP link local: (not bound) Fri Jan 24 18:35:01 2020 UDP link remote: [AF_INET]209.58.135.108:1194 2020-01-24 18:35:02,182 DEBG 'start-script' stdout output: Fri Jan 24 18:35:02 2020 [openvpn2.vpnunlimitedapp.com] Peer Connection Initiated with [AF_INET]209.58.135.108:1194 2020-01-24 18:35:08,736 DEBG 'start-script' stdout output: Fri Jan 24 18:35:08 2020 TUN/TAP device tun0 opened Fri Jan 24 18:35:08 2020 /usr/bin/ip link set dev tun0 up mtu 1500 2020-01-24 18:35:08,738 DEBG 'start-script' stdout output: Fri Jan 24 18:35:08 2020 /usr/bin/ip addr add dev tun0 local 10.200.0.86 peer 10.200.0.85 2020-01-24 18:35:08,740 DEBG 'start-script' stdout output: Fri Jan 24 18:35:08 2020 /root/openvpnup.sh tun0 1500 1553 10.200.0.86 10.200.0.85 init 2020-01-24 18:35:08,750 DEBG 'start-script' stdout output: Fri Jan 24 18:35:08 2020 Initialization Sequence Completed 2020-01-24 18:35:08,885 DEBG 'start-script' stdout output: [info] Application does not require port forwarding or VPN provider is != pia, skipping incoming port assignment 2020-01-24 18:35:08,886 DEBG 'start-script' stdout output: [info] Checking we can resolve name 'www.google.com' to address... 2020-01-24 18:35:09,219 DEBG 'start-script' stdout output: [info] DNS operational, we can resolve name 'www.google.com' to address '172.217.16.36' 2020-01-24 18:35:09,223 DEBG 'start-script' stdout output: [info] Attempting to get external IP using Name Server 'ns1.google.com'... 2020-01-24 18:35:09,986 DEBG 'start-script' stdout output: [info] Successfully retrieved external IP address 209.58.135.108 2020-01-24 18:35:10,074 DEBG 'watchdog-script' stdout output: [info] qBittorrent listening interface IP 0.0.0.0 and VPN provider IP 10.200.0.86 different, marking for reconfigure 2020-01-24 18:35:10,079 DEBG 'watchdog-script' stdout output: [info] qBittorrent not running 2020-01-24 18:35:10,080 DEBG 'watchdog-script' stdout output: [info] Removing session lock file (if it exists)... 2020-01-24 18:35:10,081 DEBG 'watchdog-script' stdout output: [info] Attempting to start qBittorrent... 2020-01-24 18:35:10,602 DEBG 'watchdog-script' stdout output: [info] qBittorrent process started [info] Waiting for qBittorrent process to start listening on port 8080... 2020-01-24 18:35:10,728 DEBG 'watchdog-script' stdout output: [info] qBittorrent process listening on port 8080

