




corgan
Members
-
Joined
-
Last visited
Everything posted by corgan
-
Hello, after I updated today from 6.9.2 to 6.12.2 my syslog gets extremly flodded with these messaged: serva4-diagnostics-20240214-2049.zip Ruffly every 10 second 3 lines. Hardware: ASRockRack X470D4U2-2T with onboard GPU AMD Ryzen 7 3700X 1x NVIDIA GeForce RTX 2060 1x Radeon RX 470/480/570/570X/580/580X/590 System Drivers: What I already tried: - I updated all outdated plugins - deinstall/install radeonTop - deinstall/install gpu statistic - deinstall/install AMD Vendor Reset The Radoen RX is not used in any way. No VM/Docker is using it. I saw [1], [2], [3], [4], [5] Post here in the Forum with the same problem, but no solution. Any Ideas?
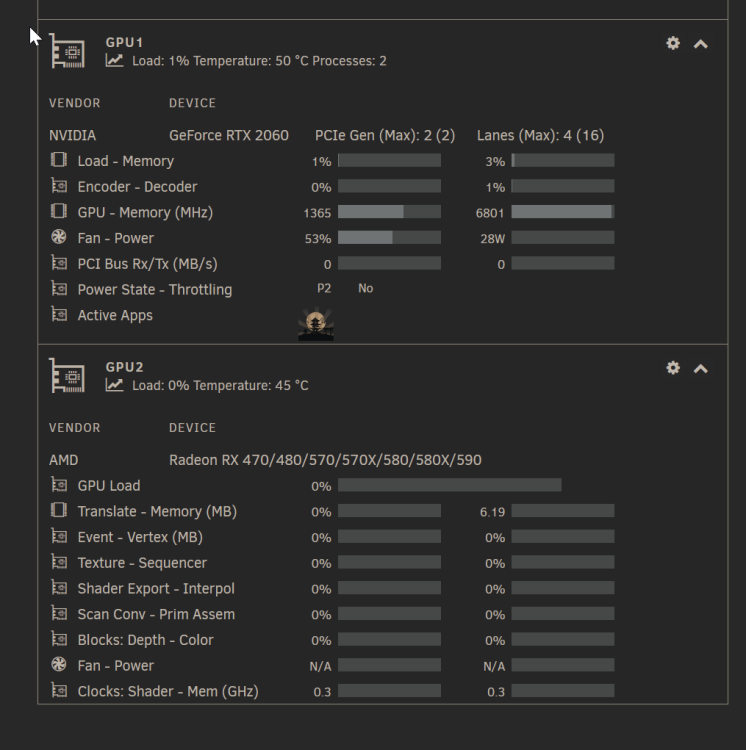
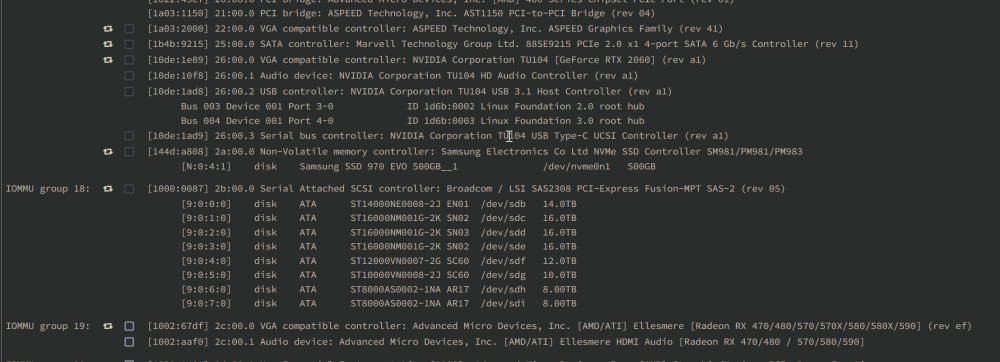

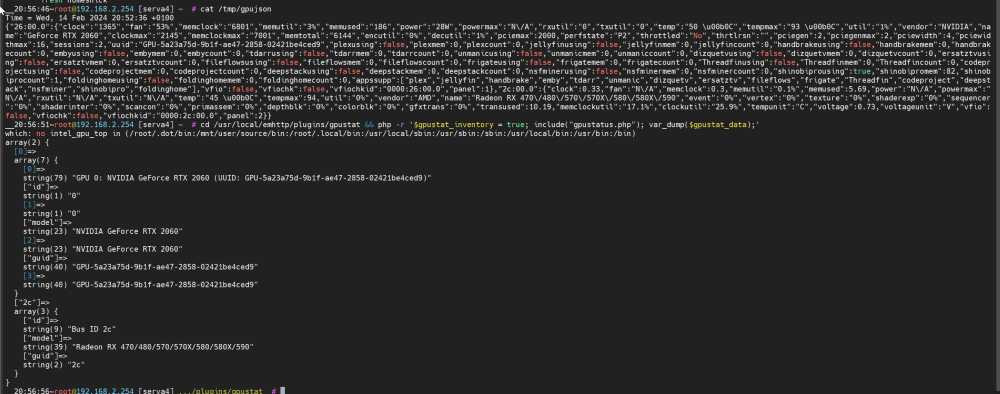

-
thank you so much! Works great directly as datasource in grafana.

-
in your logs i found clock source: unix detected number of CPU cores: 24 current working directory: /app/ml sure that you use the gpu version? Have you tried the normal version, without gpu?
-
The replacement is "on the way"..
-
In the logs you find: com.impossibl.postgres.jdbc.PGSQLSimpleException: Connection Error: connection timed out: /192.168.2.254:5432 That means, that the container trys to connect to the external DB. Can you please delete the IP from the external_DB field and try again?
-
ahhh, ok, that's the Problem. As i can see in your screen, the compose DB is using the same folder. So there is a conflict. If you don't need the compose app/db data anymore, then it makes sense to delete it. I did this today also.
-
ähm, are you doing the installation from the command line?
-
What I'm wondering, the webui part is wrong. I had the port:80 Part wrong in an old Version. But this was fixed. https://github.com/corgan2222/unraid-templates/blame/0c12ba77b8ea5df95510ac5c41dddf61842c2e2f/CompreFace-GPU/CompreFace-GPU.xml#L37 Maybe you still have an old cached version. Please delete the compreface apps. If its still exist, delete /mnt/user/appdata/compreface Reinstall the app and then check if /mnt/user/appdata/compreface exists and if there are data inside.
-
FATAL: "/var/lib/postgresql/data" is not a valid data directory The Data Folder is wrong. Can you show me your configuration ?
-
EaseUS is now running for around 30min and still needs 41h on my 16tb Drive?! Is this normal? Is it safe to start the array? ATM I get the "Stopped. Missing disk." Message.
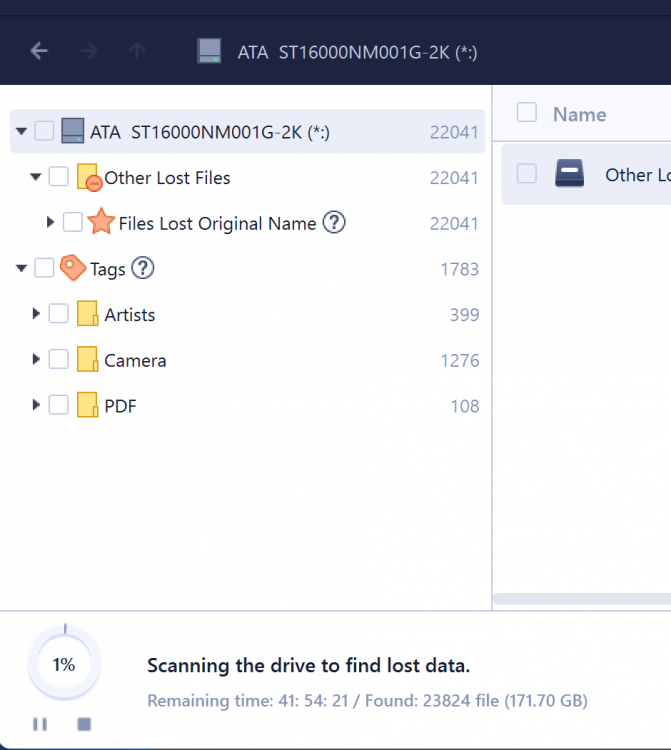
-
Thanks so much for the clarification. Will try the free version and hope the best. And actually there are indeed some baby photos of my kid on the drive. (from which I luckily have a backup )
-
We had some Problems with the Data Folder to get persistent. This should now be fixed. Additionally, there is the possibility to use an external Postgres Server. The new Template Version is pushed to Github. We just have to wait till it's available in the CA Store.
-
Thanks Squid for the quick answer! I will look into the software. But I still don't know what's the best way to move forward. First trying to repair? Or putting in a new replacement disk and rebuild the array without xfs_repair?
-
Hallo today, my server crashed, and I needed to reboot. After reboot, the first array Disk was missing and corrupted. Disk: ST16000NM001G-2KK103_ZL20FTBK (sdb) No Smart Errors xfs 68 TB Array with 7 Disk + 1 Parity Dec 12 17:10:48 serva4 kernel: SGI XFS with ACLs, security attributes, no debug enabled Dec 12 17:10:48 serva4 kernel: XFS (md1): Mounting V5 Filesystem Dec 12 17:10:48 serva4 kernel: XFS (md1): Ending clean mount Dec 12 17:10:48 serva4 kernel: XFS (md1): Metadata CRC error detected at xfs_agi_read_verify+0x86/0xcf [xfs], xfs_agi block 0x67fffff9a Dec 12 17:10:48 serva4 kernel: XFS (md1): Unmount and run xfs_repair Dec 12 17:10:48 serva4 kernel: XFS (md1): First 128 bytes of corrupted metadata buffer: Dec 12 17:10:48 serva4 kernel: 00000000: 91 c7 3f e9 3d 0a f6 09 ca d3 88 6e 72 47 6c 25 ..?.=......nrGl% Dec 12 17:10:48 serva4 kernel: 00000010: 65 72 51 16 6b 30 5d c4 34 ad 5d 56 bb f1 52 a6 erQ.k0].4.]V..R. Dec 12 17:10:48 serva4 kernel: 00000020: 45 16 39 a1 ac c2 6e 03 a5 ab 9e c3 ce fb 23 e0 E.9...n.......#. Dec 12 17:10:48 serva4 kernel: 00000030: 7a 27 f4 f6 51 34 ce 8e f1 e3 6e 04 02 5d 41 4a z'..Q4....n..]AJ Dec 12 17:10:48 serva4 kernel: 00000040: 44 27 61 60 6c e5 02 6b 6a 29 fb 58 f5 06 98 f1 D'a`l..kj).X.... Dec 12 17:10:48 serva4 kernel: 00000050: 54 90 4f 6b bd 55 3c 71 c9 61 10 a0 47 69 c9 22 T.Ok.U<q.a..Gi." Dec 12 17:10:48 serva4 kernel: 00000060: 60 62 c6 25 26 60 59 92 65 ee 58 64 3b c4 fb 3e `b.%&`Y.e.Xd;..> Dec 12 17:10:48 serva4 kernel: 00000070: bb 41 07 79 60 3a fd 3f e0 fe 81 80 31 8d 9e 02 .A.y`:.?....1... Dec 12 17:10:48 serva4 kernel: XFS (md1): metadata I/O error in "xfs_read_agi+0x7c/0xc8 [xfs]" at daddr 0x67fffff9a len 1 error 74 Dec 12 17:10:48 serva4 kernel: XFS (md1): Error -117 reserving per-AG metadata reserve pool. Dec 12 17:10:48 serva4 kernel: XFS (md1): xfs_do_force_shutdown(0x8) called from line 540 of file fs/xfs/xfs_fsops.c. Return address = 000000009ffc26d9 Dec 12 17:10:48 serva4 kernel: XFS (md1): Corruption of in-memory data detected. Shutting down filesystem Dec 12 17:10:48 serva4 kernel: XFS (md1): Please unmount the filesystem and rectify the problem(s) Dec 12 17:10:48 serva4 root: mount: /mnt/disk1: mount(2) system call failed: Structure needs cleaning. Dec 12 17:10:48 serva4 emhttpd: shcmd (40): exit status: 32 Dec 12 17:10:48 serva4 emhttpd: /mnt/disk1 mount error: not mounted Dec 12 17:10:48 serva4 emhttpd: shcmd (41): umount /mnt/disk1 Dec 12 17:10:48 serva4 root: umount: /mnt/disk1: not mounted. Dec 12 17:10:48 serva4 emhttpd: shcmd (41): exit status: 32 Dec 12 17:10:48 serva4 emhttpd: shcmd (42): rmdir /mnt/disk1 Dec 12 17:10:48 serva4 emhttpd: shcmd (43): mkdir -p /mnt/disk2 Dec 12 17:10:48 serva4 emhttpd: shcmd (44): mount -t xfs -o noatime /dev/md2 /mnt/disk2 - Then I stopped the array - activate Maintenance Mode - Checked the corrupted drive from the gui, with testing and verbose. -nv No changes written to the Disk I got thousands of these logs entry "corporate bag Layers" in directory inode 14739857867 points to non-existent inode 28614441717, would junk entry and around 75000 of these disconnected dir inode 19665158868, would move to lost+found Complete Log So I red though the Forum and the documents. [1] [2] But now I'm more confused as before. What is the correct workflow to not lose any Data or found, thousands of files with wrong names in the lost+found folder. First repair the disk with xfs_repair, or simple swap the disk with a new one and let the array rebuild? Array and Cache Disks:
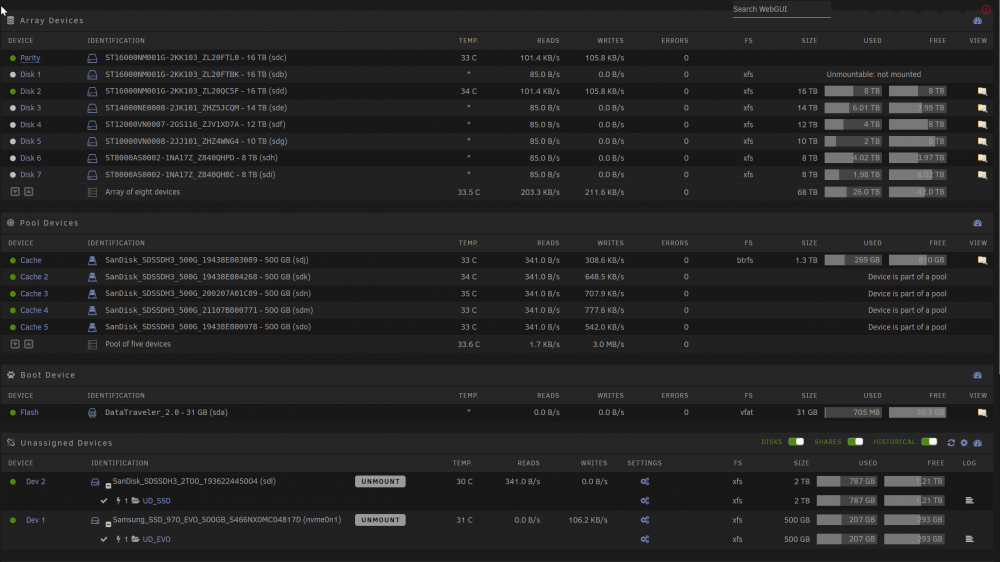
-
Thanks for the Info! I got a response that the developer will make the changes on his side.
-
After I used this container for a long time, it's stopped working. I deleted the container and the appdata folder and made a fresh install, but still have the same error. Does anyone get this running?
-
This can be a solution. But the Dockerfile are developed by the app developer, so he has to make these changes?
-
Hello, we tried for weeks to get compreface working on Unraid Docker. I asked for help about this some month ago, but sadly the unraid docker was not out of the box capable to handle the app structure, as we discussed here. The Developer was so kind to rewrite the structure and made a single dockerfile version for unraid and home assistant user. I could create a Template for the normal and the GPU Version. But we have the problem, that the developers used named volumes. If i try to expose the folder to make it persistent, the app can't start. We can only use the app without persistent data, which is not ideal. He explained the problem over at github quite well. Read the conversation on Github for better readability.. @corgan2222 in my example I used named volume: -v compreface-db:/var/lib/postgresql/data The default behavior of named volume is that when it first created the volume, docker copies all content of the image to the volume with all permissions. Docker in its documentation recommends using named volumes because of portability. When you set the exact folder to mount, docker created a bind mounts: -v '/mnt/user/appdata/compreface':'/var/lib/postgresql/data':'rw' By default, docker does not copy image content into bind mounts. This is why the Postgres data folder is empty inside your container and Postgres can't start. So I would follow docker recommendations and use named volumes. In case this is impossible or you still prefer using binding to a folder, there is a workaround for such case if you still want to mount the exact folder into the docker container: You need to create a named bind mount: docker volume create --driver local \ --opt type=none \ --opt device=/mnt/user/appdata/compreface \ --opt o=bind \ compreface-db And then use it as named volume during start: docker run -it --name=CompreFace -v compreface-db:/var/lib/postgresql/data -p 8000:80 exadel/compreface:0.6.1 Maybe I miss some essential details here. What are the options to get the app running in the unraid docker, with persistent data (and without docker compose) It would be great to have some Dev Comments on this. Thanks greetz Stefan
-
Actually no Idea. I have only an AMD and a Nvidia GPU in my Unraid Server.
-
Same for me. Started my IT education 2001 with ASP and PHP and worked around 10 Years in the industry. But stopped coding it 11 Years ago. Cool, thanks. I finished the Compreface Template on the weekend and saw that they have also a GPU Version of it, which is easy to detectable. But I didn't had the time to make another PR. Hope to find some time next weekend for this. Thanks, greetz Stefan
-
added 6. compreface - CompreFace is a leading free and open-source face recognition system Project Page: https://github.com/exadel-inc/CompreFace Dockerhub Page: https://hub.docker.com/r/exadel/compreface/ Github Issue: https://github.com/exadel-inc/CompreFace/issues/651
-
Yes, I totally understand. I started a new job 4 weeks ago and there is very little time left. But will take a look into the branch. Maybe nice to come back to PHP after around 10 Years. :) I changed the filename to lowercase. But this PR Menu at GitHub is such a mess. This confuses me every time.
-
OK, understand.
-
Ahhh, ok. For technical reasons, or just a design choose? Are there any restrictions or any other (driver) things, why not show both?
-
@b3rs3rk Sorry for the mess with the last PR. I rewrote it. as i asked some time ago, I can't display my second AMD GPU, if I select first my main nvidia GPU. If I start without the nvidia GPU, I can display the AMD fine. Is this plugin designed to show only one GPU Vendor at the time?










