




corgan
Members
-
Joined
-
Last visited
Everything posted by corgan
-
I hadn't seen that there was already a thread about this. In principle, my container does exactly what you did manually.
-
Added 8. ManicTimeServer- ManicTime Server receives data from ManicTime clients installed on your network and provides reports, which you can view with a web browser. Project Page: https://www.manictime.com/ Dockerhub Page: https://hub.docker.com/r/manictime/manictimeserver Latest Version: 2024.3.4.1 Release 06.02.2025
-
Great! That's are good news! I have some questions regards the update interval. Is there any rule that defines how often components are updated? Sometimes it takes forever after a Home assistant restart till the components are available, and sometimes there are dozens of updates in one minute. And is there any way to request or trigger an update? Is it an expected behavior that the API sends the discovery message over and over, or is there something broken? For me, the API sends all sensors from the server, docker and the VMs. I don't have broken entities after discovery. Thanks and greetz Stefan
-
Valid question. Is there any development on this project? vg Stefan
-
I already had these settings. Thank you for the fast reply! It's all fine now.
-
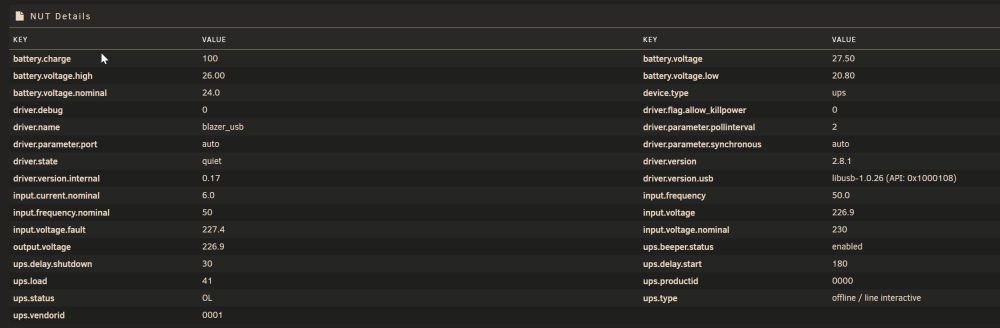
Thanks for the fast reply! I did as you told me, but no difference. Then I spotted the notice regarding powertop. I had powertop installed for months and never had issues. But in this case, after removing powertop, the errors are gone, and I can see the ups details again. One notice, If I choose nutdrv_qx as driver, "Battery Charge" is not displayed. If I choose the blazer_usb, Battery Charge is shown. Is there any chance to get the "Runtime Left" Infos from the greencell USV?
-
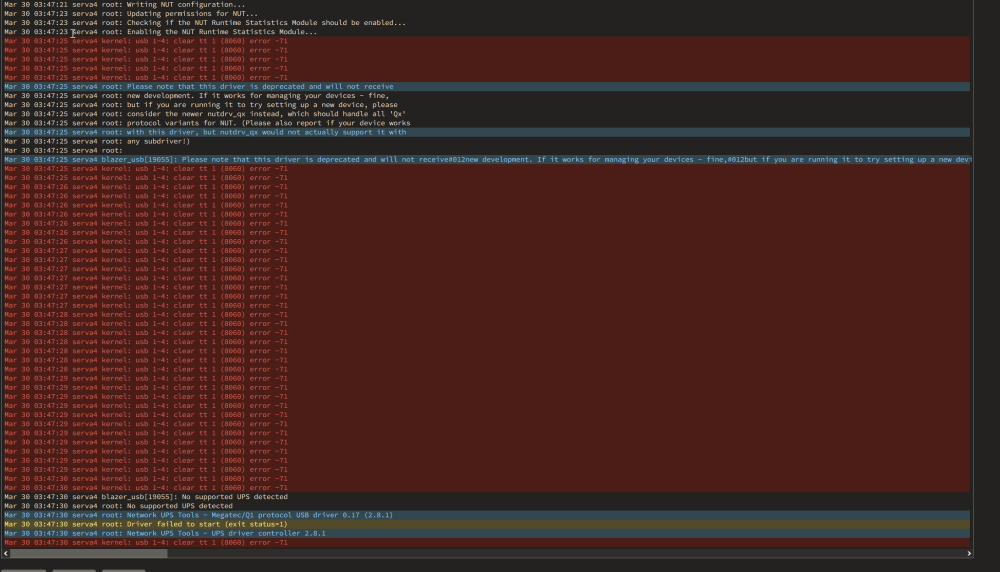
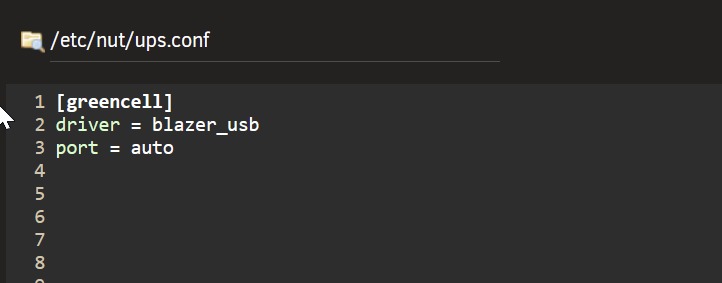
Hey Rysz I updated today to 2024.03.28. Before the update, my Green Cell UPS 1500VA (900W) could be read. But now I get these errors: Is there anything I have to change, to get it back working? Thanxs, greetz Stefan
-
Hey all.. After removing the gpu driver, the GPU Errors in the ipmi logs are gone. That's good. But tonight the server crashed again, but with a different error. The server was not reachable from the network with a 100% packet loss. But I could log in via the onboard KVM and use the terminal. Strangely, a ping from the server to the network was successful. Now I have a ton of these errors in the log. The CPU Numer (CPU 14 to CPUs 0:) itterated from 0-15. I then wanted to stop the array from the command line and reboot, but the server got stuck and hung for over an hour. Then I send a CRTL+ALT+DEL but got stuck at the "starting diagnostic collection" step. So I had to send a "power cycle" via ipmi to reboot and now have to do the parity check again.
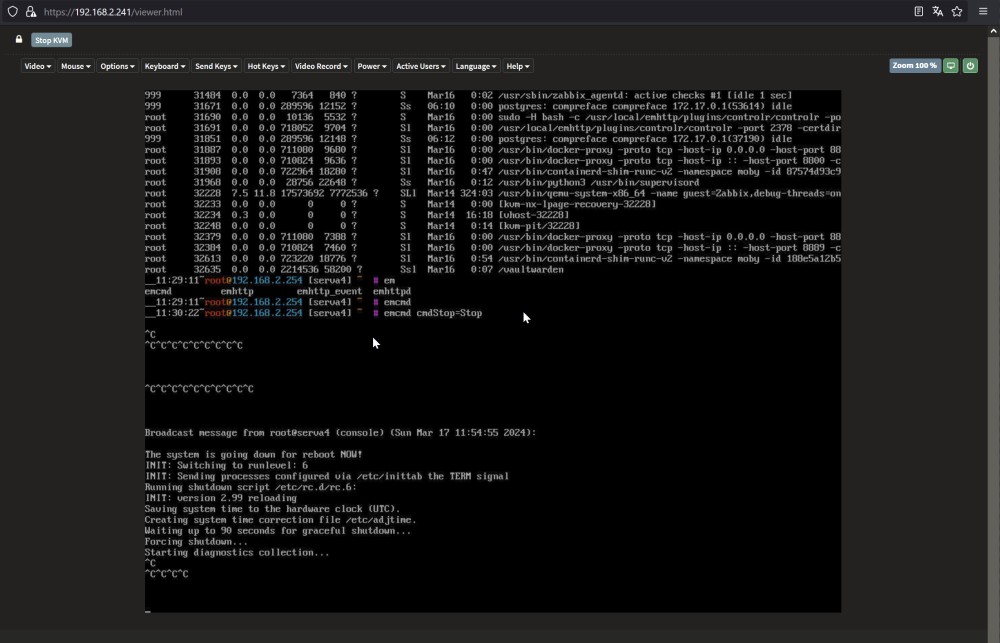
-
Hello, if I activate the "Provide UPS status" option in the plugin settings, the plugin will not start. Status "Stopped". If I deactivate the option, everything works fine. I would assume the reason is, that I use the "Network UPS Tools (NUT) for UNRAID" Plugin and not the build-in "UPS Settings". Any change to get the Infos from this plugin integrated?

-
-
Back in the days in 2021 I created 2 templates. One for the normal compreface and on for compreface-gpu. This was the Icon I used for the nvidia gpu version. TBH, I didn't think about. If this is more pleasant, just use the normal one. https://github.com/corgan2222/unraid-templates/blob/main/img/compreface.png
-
https://github.com/SimonFair/gpustat-unraid/pull/25 ^^
-
perfect! This works. Will create a PR.
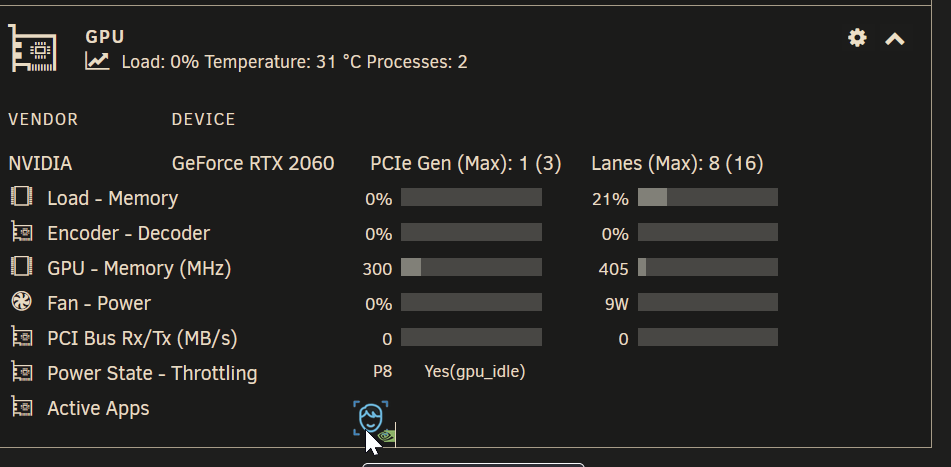
-
I'm trying to add compreface-gpu to the SUPPORTED_APPS. But it looks like the plugin don't use the files /usr/local/emhttp/plugins/gpustat/ for the running dashboard version. I wanted to test this, before creating an PR. Is there a trick? gpustatus.page: $apps = [ 'plex', 'jellyfin', 'handbrake', 'emby', 'tdarr', 'unmanic', 'dizquetv', 'ersatztv', 'fileflows', 'frigate', 'deepstack', 'nsfminer', 'shinobipro', 'foldinghome', 'compreface', ]; /lib/Nvidia.php const SUPPORTED_APPS = [ // Order here is important because some apps use the same binaries -- order should be more specific to less . . 'compreface' => ['uwsgi'], ]; and added compreface.png to /usr/local/emhttp/plugins/gpustat/images/ Did I miss something?
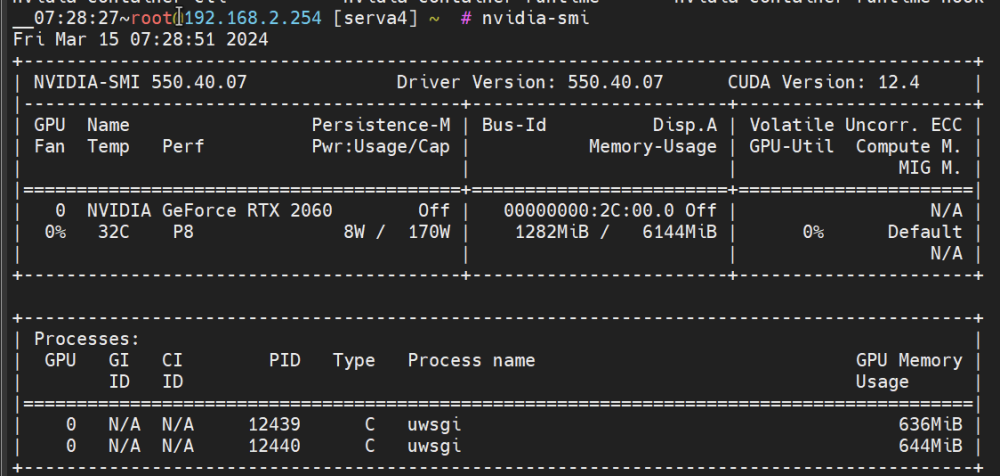
-
Sorry, I was "offline" for some time. Updated today. 2024 update - compreface:1.2.0-mobilenet-gpu - compreface:1.2.0 - skrashevich/double-take:latest
-
nope, use this one
-
After I deinstalled the second ATI GPU, I had hopes that the System is more stable now. But sadly it crashed again after 3 days uptime. The stop was at 21:02. Ipmi Log: Last Unraid Log was 6min before. So it looks like, that there is nothing written. The ipmi log says that the Video controller had a failure, but not which. I have a RTX2060 and the onboard in the system. How can I deactivate the onboard VGA for unraid? I think I can't do that in the bios. greetz Stefan

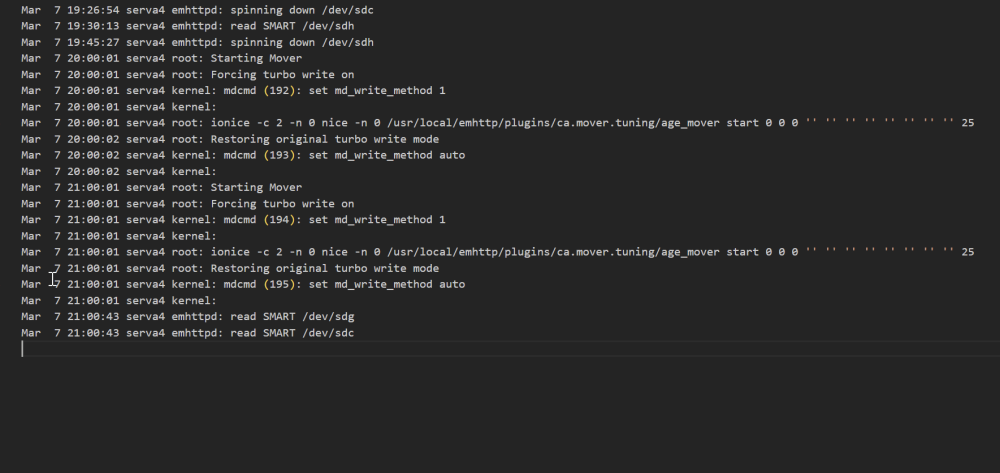


-
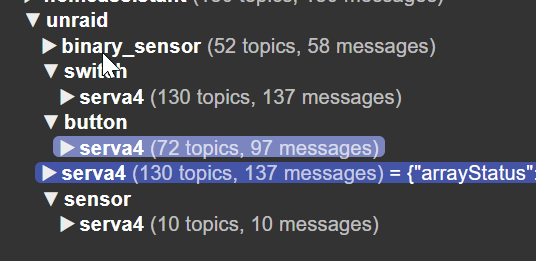
I'm looking for a way to filter what is published via mqtt to not clutter up my home assistant with dozen of switches again. Sadly with autodiscover ON in HA I can't filter which devices are discovered. With autodiscover, it woudl create 130 switches, 52 sensors, aso. I found the mqttDisabledDevices.json in the appdata folder, but no documentation or example how to use this file. In the end, I only want to have 2 docker container controlled via HA and don't want all the information inside HA.
-
Really, nobody has an Idea?
-
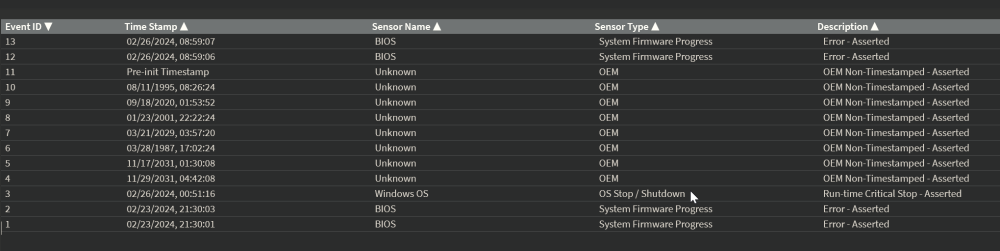
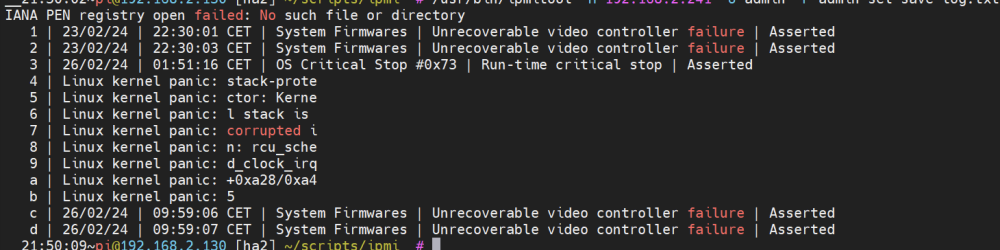
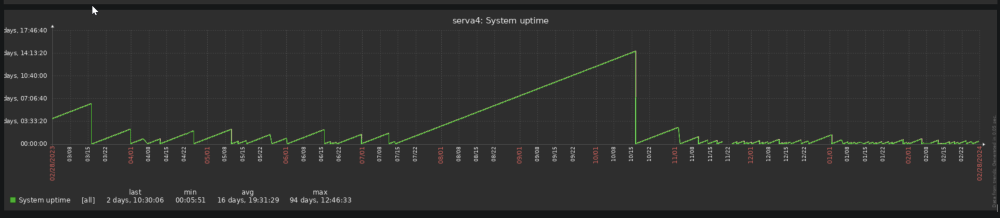
Hey guys, this is my last attempt to fix these random kernel panics. I'm fighting this issue since years, but never had a hint where to start. Because I never got anything in the logs. I had set up an external rsyslog server for this, but the last log was minutes before the blackout and had nothing to do with kernel panics. The Screen was always black and in the ipmi log was only this: Not really helpful for finding the root course, but I could react on "OS Critical Stop" | "kernel panic" and send an ipmitool -I lanplus -H 192.168.2.241 -U user -P pass power cycle Command to automatically reboot. But today I played around with the ipmi tools and the first time I got something what maybe can help. So that's my hope. The string is not complete, and I don't get more information from the ipmi tool. But maybe this helps. Any Idea? Hardware: AMD Ryzen 7 3700X 8-Core 3600 MHz @ ASRockRack X470D4U2-2T American Megatrends International, LLC., Version P4.10 BIOS dated: Tuesday, 18.05.2021 Unraid 6.12.8 1x GeForce RTX 2060 1x Radeon RX 470 (VFIO Binded) 8x HDD 84tb - xfs Raid 5x SSD Cache 1,3tb 1x Samsung_SSD_970_EVO_500GB nvme for docker 1x SanDisk_SDSSDH3_2T00 2tb for VM Full Hardware: Running Aps: The RTX is pass through to Shinobi I have this problem nearly since 3-4 years as the server exists. At the beginning, this only happens once in a month. But since a year this happens once a week. After a power cycle while the server is checking parity, this never happens. Only 1-2 days after the parity got checked, what takes around 19h. Here is my uptime diagram from the last year. Every drop was a black screen. So any Ideas what to check, or what's the root cause of this problem? Thanks in advance, Stefan serva4-diagnostics-20240228-2204.zip raw.txt sel.txt
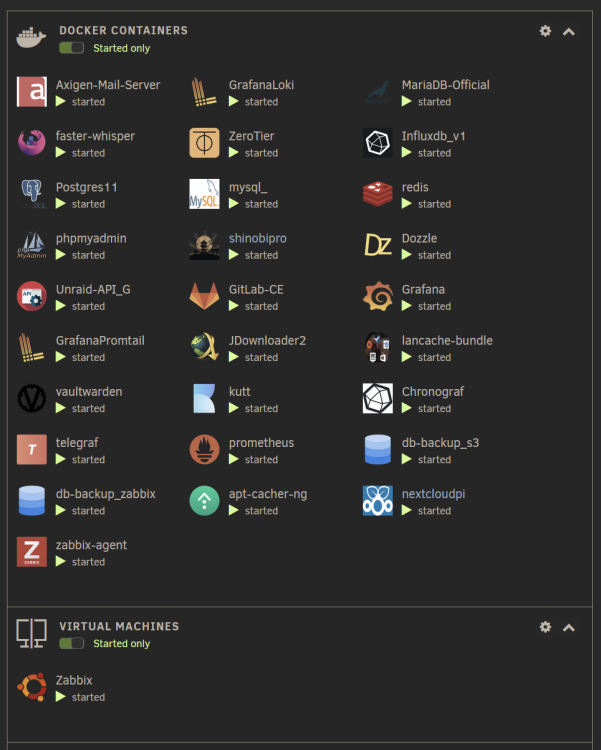
-
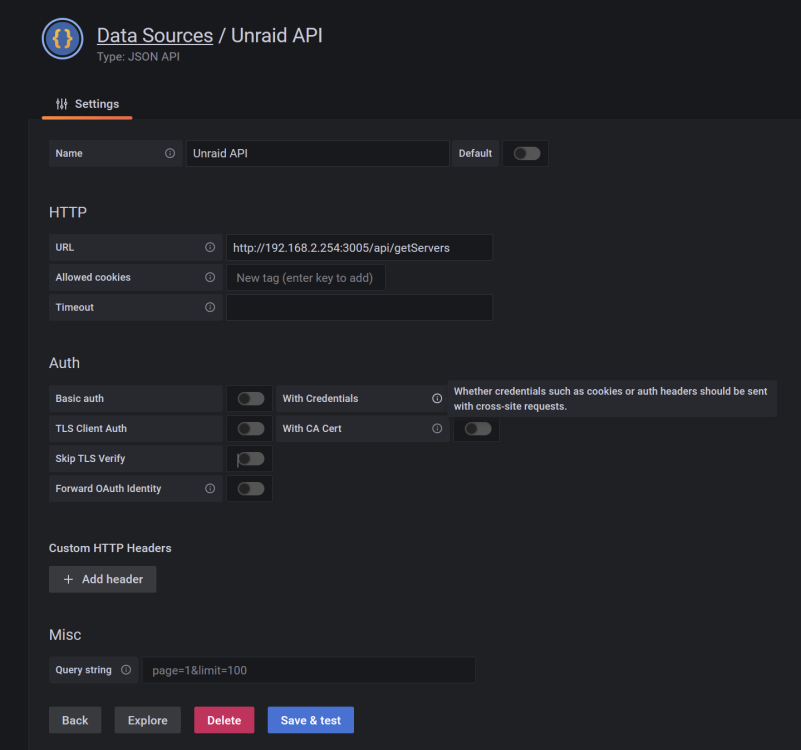
Data Source: Type: JSON API Data Source Config: my server is on 192.168.2.254 port of the api: 3005 So the URL must be http://192.168.2.254:3005/api/getServers Grafana Panel Config for Docker Container: Panel https://grafana.com/grafana/plugins/dalvany-image-panel/ use your IP! $.['servers']['192.168.2.254']['docker']['details']['containers'][*].name $.['servers']['192.168.2.254']['docker']['details']['containers'][*].imageUrl $.['servers']['192.168.2.254']['docker']['details']['containers'][*].status
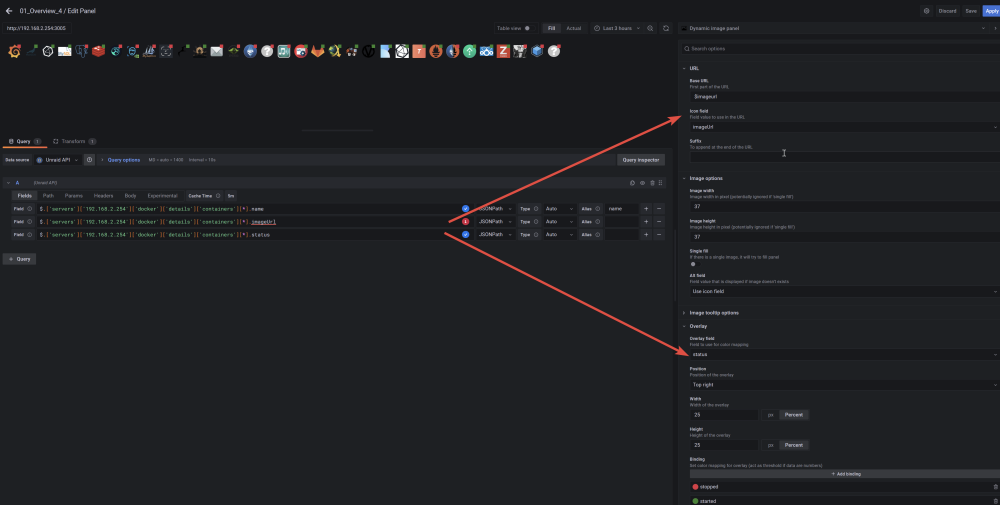
-
This looks good. Not one error in 13min uptime. But if I understand this correct, with this check we have restricted the access from unraid to the amd, but If I want to use it in a VM/Docker, this will work? Anyway, thanks a lot!!!
-
Ok, is checked. But have to reboot. brb
-
you mean this one?

-
Not without a bigger operation and shutting down my homelab and all services. (not wife approved) So sadly not really. If everything runs fine some day, I want to use the AMD with path trough in a window WM. Which worked till the update. Thanks, Stefan






















