




TrondHjertager
Members
-
Joined
-
Last visited
Everything posted by TrondHjertager
-
I have my unraid server joined to my home AD-domain. In the AD-section under SMB-settings the initial owner is Administrator and group is domain users. This is all fine, but I have some problems with my nextcloud-container. It seems like Nextcloud needs to have nobody:nobody, so every time I update the container the owner/group changes to administrator:domain users, and I have to manually change it back to nobody:nobody. Apart from creating a script and running it as a cronjob, is there an easy way of fixing this? Can I configure this in the docker config or something? Thanks!
-
This solved the problem for me. Thanks! ❤️
-
Ah! Thanks! I will try that!
-
Hi! I added 10 new (used) drives to my server the other day. I started preclearing all of them, but 4 of them failed before even starting the process. The HBA, cables and backplane have been working perfectly so far, but because of the ongoing preclear-job on the other 6 drives I haven't had the opportunity to try other slots in my server yet. I ran an extended selftest on the four problematic drives, but I cannot see anything wrong. When I open the drivelogs I see the same errors on all the drives I have added diagnostics. Anyone have any tips or ideas on what may cause the problem? Thanks in advanced! -Trond unraid02-diagnostics-20240102-0757.zip
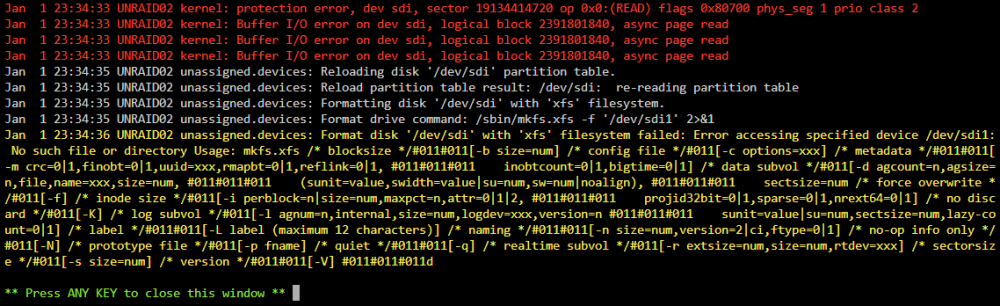
-
Nope, nothing yet. I posted the DebugLogId in this thread, but haven't heard anything yet. If I can't get the plugin to work with plex, then I guess I'll just have to write an rsync script or something to backup up my plex appdata ☹️
-
DebuglogID: 97b5df4c-4eea-448c-bb13-71fe0f6186cb
-
I installed this plugin yesterday after upgrading Unraid to version 6.12.4. It seemed to work fine, except when it tried to back up the Krusader and Plex containers. Krusader isn't important, but Plex is quite critical. Plex's app data folder is about 34GB and has over 1.1 million files. Could this be related to the issue? This is the error I get [16.10.2023 06:29:28][❌][Plex] tar creation failed! Tar said: ; gzip: stdout: Input/output error; tar: Child returned status 1; tar: Error is not recoverable: exiting now
-
Looks like I had to use nobody:nobody isted of root:root. Seems to have done the trick for me.
-
I'm having issues with my Nextcloud installation. I'm running the LinuxServer's Nextcloud container. When I tried to log in to the webui, I received the following error message: "Error Your data directory is readable by other users. Please change the permissions to 0770 so that the directory cannot be listed by other users." I then ran chmod -R 0770 /mnt/user/Nextcloud. After doing this, when I try to access it, I get the following error message: "Error Your data directory is invalid. Ensure there is a file called ".ocdata" in the root of the data directory. Your data directory is not writable. Permissions can usually be fixed by giving the web server write access to the root directory. See https://docs.nextcloud.com/server/27/go.php?to=admin-dir_permissions." I have a .ocdata file under /mnt/user/Nextcloud. The permissions on /mnt/user/Nextcloud are as follows: drwxrwx--- 1 root root 113 Sep 26 07:55 NextCloud/ I can't seem to get this to work correctly. Does anyone have any tips? Do I need to set another owner/group?
-
Ah! Thanks! Will try this when I get home from work! Love this community! ❤️
-
Got 12 used dell enterprise SSD drives from work today, but I am having some problems with the unassigned device plugin. They are not showing up as unassigned devices. They show up in the unassigned preclear-thingie, but they are all marked as "cannot preclear". I see them in the filesystem under /dev/dsXXX. I even get smart data off them by using smartctl. Anyone know how come the preclear and mounting is not working? I am running version 6.11.5 of unraid. Diagnostics attached. unraid02-diagnostics-20230228-2311.zip


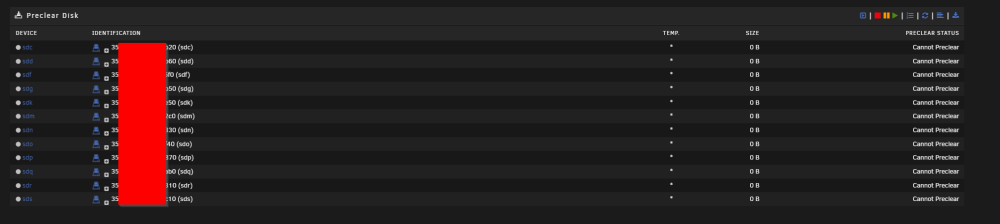
-
Both Radarr and Sonarr was set in bridgemode. Worked with Sonarr but not Radarr. Sat both of them in hostmode, and everything worked
-
Looks like changing the network type from bridge mode to host mode did the trick. Not sure why. All three containers were set to use bridge mode, but changing radarr to host mode solved the problem.
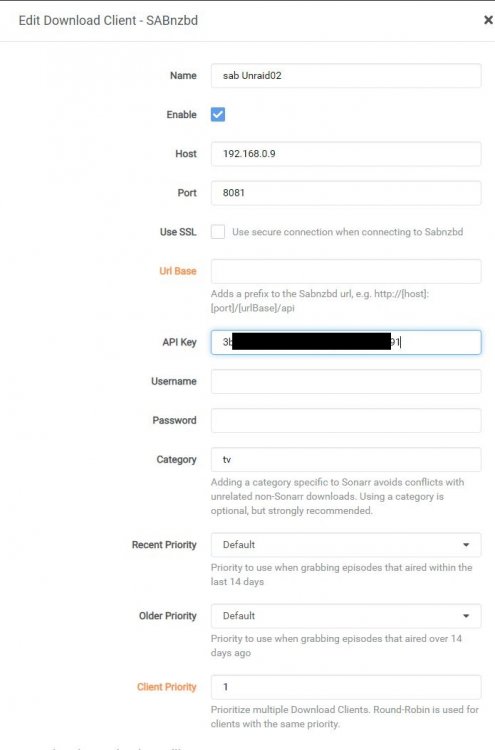
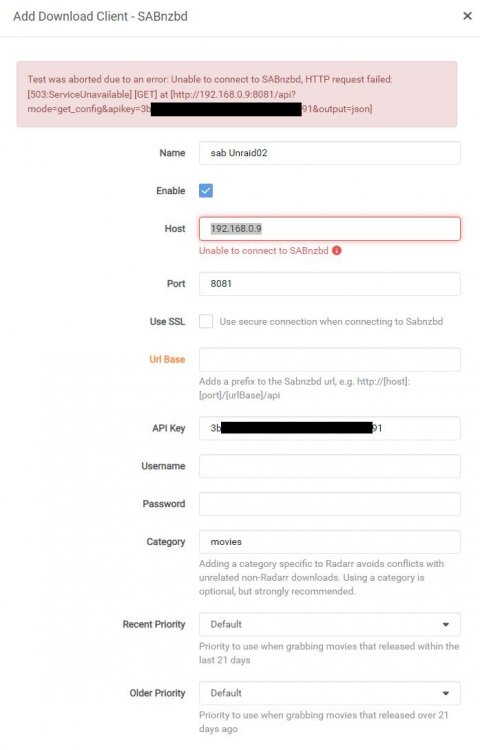
-
I am moving all my download-stuff from a windows server to unraid containers, but I am having some problems with Radarr. I am using binhex for Radarr, Sonarr and sabnzb. Sonarr works perfectly, and I have configured Radarr in the same way as Sonarr, but I cannot get Radarr to connect to Sab. Any idea what might be wrong? unraid02-diagnostics-20220722-0346.zip
-
I am in the process of creating a backup-scheme for all my servers and data, but when it comes to plex I am not sure what would be the best way. I was thinking of maybe using rsync and just copy everything to my backup server. But I se that my metadata-folder is 22Gb and hundreds of thousands (if not millions) of tiny files. I guess this is just things like thumbnails etc? Is this something that I need to backup? If I need to do a disaster recovery I would like to get my plex up and running with all the userdata and watchprogress etc, but I don't have any problems re-downloading things like thumbnails and other non-essential data. I have a 1gbit internet connection and a beefy server. My total appdata/plex folder is 33GB. 22GB of this is the /appdata/plex/Library/Application Support/Plex Media Server/Metadata folder. Can I just exclude this folder from the backup without breaking it?
-
looks like I made it the wrong way. I made the partition in the commandline. Looks like I am transfering 18TB of data yet again
-
Hi! I have three new 18TB disks that I got to replace a bunch of smaller 2 and 3 tb drives. Previously used two 8Tb disks as parity, so two of the new 18Tb's will be parity, and the last will be a data disk. The two old 8TB disks will be new data disks as well. I also have 3 8 TB data disks. I connected the new 18 TBs and did a preclear a while ago. I also made an xfs fs on the one that will be used for data, and I copied all the data of the smaller drives to this while mounting it as an unassigned device. Everything was well so far. Now I have made a new array config, removed all the smaller drives, and tried to make a new array config (without parity for now, as I still need to move some data between some disks), but the 18TB disk shows up as "auto" under FS, and "unmountable: unsupported partition layout". If I try to mount it as an unassigned device again, everything works. Is there anything I can do to fix this without having to move all the data of the drive and reformat it? That is going to take AGES as it is almost full.
-
If anyone else finds themselves in my position, I can report that i fixed this issue by just renaming one of the old database-backup files, and then putting the plex-server on the same subnet as my client machine. The reason I didn't find the server the frist time I tried this was because of swag and a configured proxy-net. I set the plex network to bridge mode, then renamed my old app-folder, downloaded a new docker from the old template and then renamed and moved the backup of the old DB-file over to the new appfolder. I had to reset the customization for all my plex players/apps, and there were some configurations that I needed to set. But after all this was done, I put the plex-docker in the proxy-net again, and all was good!
-
So, the errors are still displayed in the GUI, but the extended selftest worked as expected with smartctl. Not sure why the GUI is reporting errors though...No errors where found on any of the disks. But it's no big deal. Thanks for your help @SimonF
-
root@UNRAID01:/dev# smartctl --test=short /dev/sdh smartctl 7.1 2019-12-30 r5022 [x86_64-linux-5.10.28-Unraid] (local build) Copyright (C) 2002-19, Bruce Allen, Christian Franke, www.smartmontools.org Can't start self-test without aborting current test (97% remaining), add '-t force' option to override, or run 'smartctl -X' to abort test. looks like there might be an ongoing selftest causing the problems. All the SAS-drives are running the test. Will let it run over night and se if it finishes. Thanks for the tip!
-
I will try it, thanks for tip!
-
Hi! I got 12 used Hitatchi Ultrastar 3TB drives from work (Dell rebranded, but it's these disks https://www.disctech.com/Hitachi-Ultrastar-0B26311-HUS723030ALS640-3TB-7200RPM-Enterprise-SAS-Hard-Drive), but all of them shows "Errors occurred - Check SMART report" under "last SMART result", even if I have never run any smart tests on them. I mounted them in my off-server yesterday, and did a preclear on all disks. All pre-cleared without errors. But I cannot run SMART tests on them. When I hit any of the SMART-test buttons, nothing happens. Does anyone know why? I don't want to run these drives without extensive testing because of old age. All disks are the same as the one shown below. I am running two LSI SAS-compatible HBA's. LSI 9xxx-something (If it's relevant, I can get the exact names of the cards). The disks seem to work just fine. unraid01-diagnostics-20220417-0101.zip
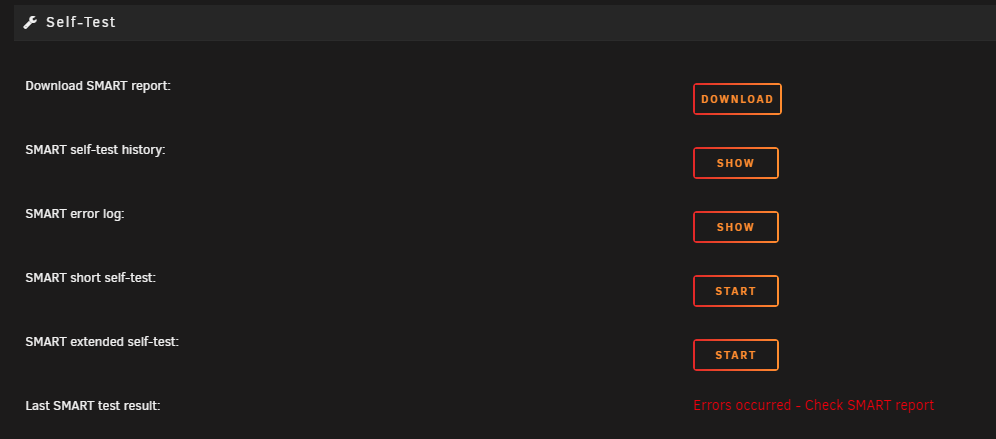
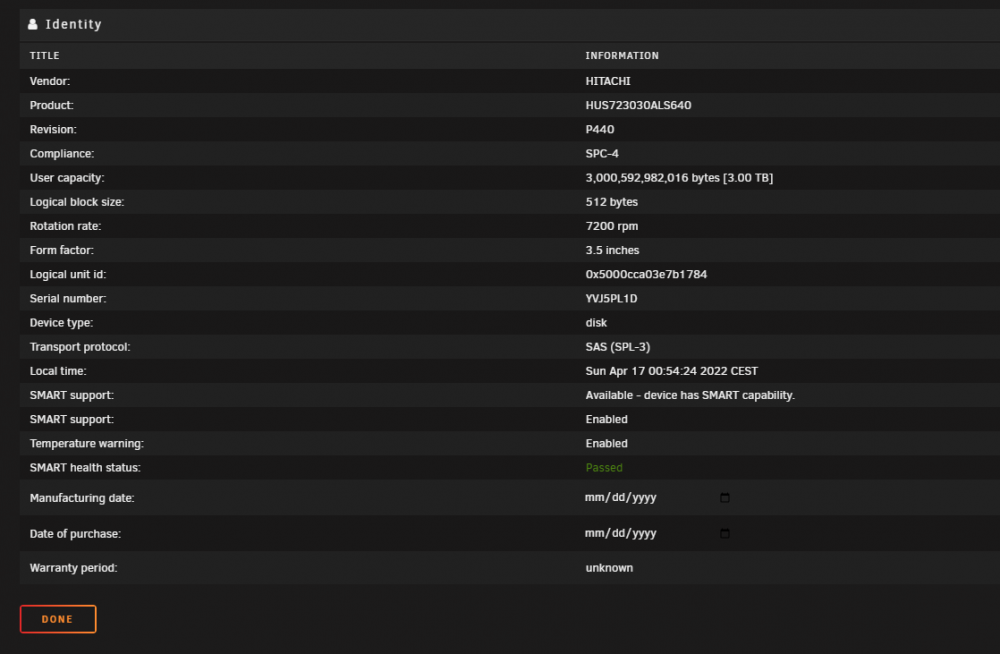
-
Last week i flamingoed up with my plex-container. For those not familiar with the term, it's like a cockup, only bigger! What I think happend is that I by mistake transferede some old and outdated appdata from another disk over to my cachedisk which stores my appdata. After that happend I got some errors from my container log: "Error: Unable to set up server: sqlite3_statement_backend::prepare: database disk image is malformed for SQL: PRAGMA cache_size=2000 (N4soci10soci_errorE)" I have tried to follow spaceinvaderone's corrupt plexdb-video, but that didn't fix anything. I also see that I have backups of the plex database from a few days before my f*ckup. Is there any way of saving my server? I have tried to rename the original appdata folder, removing the docker, installing a new docker, renaming and copying one of the older versions of the db, but I cannot seem to get it to work. Then it just doesn't find any servers when I login to my account under plex.tv. But the docker doesn't give any errors when I do this. I am using the linuxserver plex docker. I am really hoping to save my watched-data for both me and my users. Anyone know how I can save this trainwreck?
-
Looks like it just took a long time. After 15-20 minutes without any indication of anything, it let me use it as normal.
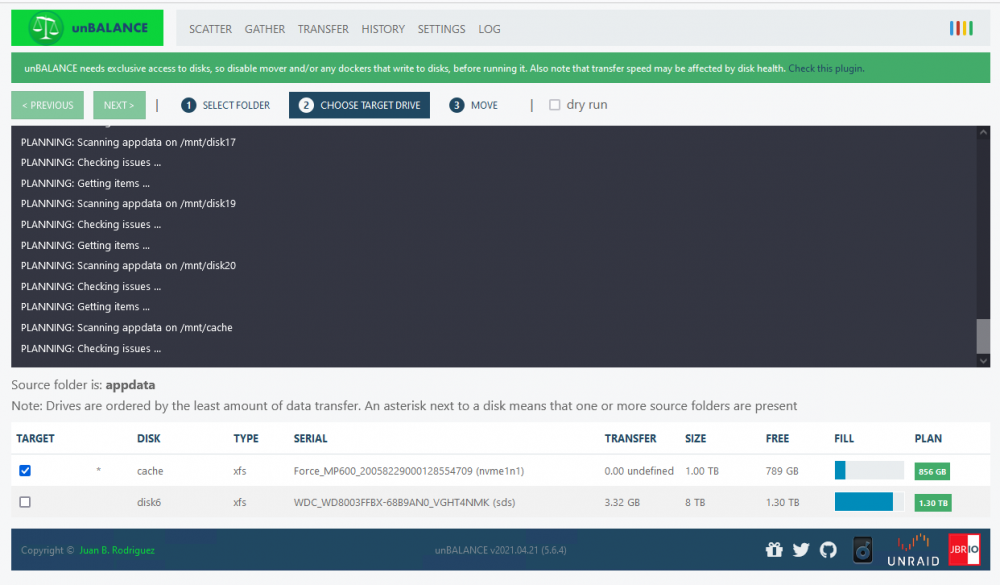
-
I am having some problems with unBallance. When I try to use it it just stops during the planning stage. It runs through the "checking issues..." stage, and just stops. The working-logo in the top right corner is "pulsating", but nothing else happens. I have never been able to use unBallance consistantly. Sometimes it works, sometimes it doesn't. I have tried multiple client machines and multiple browsers to see if that could be the issue. It's really frustrating, because this is an awesome tool. Any tips? Any logs that could give me an indication on what the problem might be?








