



groot-stuff
Members
-
Joined
-
Last visited
-
-
I don't use pfsense personally, but in my firewall I block my cameras from connecting to anything on the WAN port. Only downside is they can't connect to NTP servers for time/clock syncing... but that's far better than seeing them phone home to foreign countries for god knows what.
-
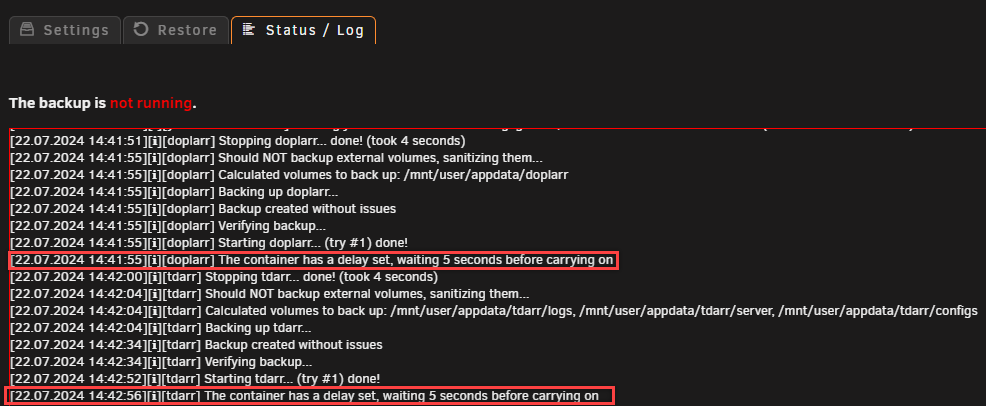
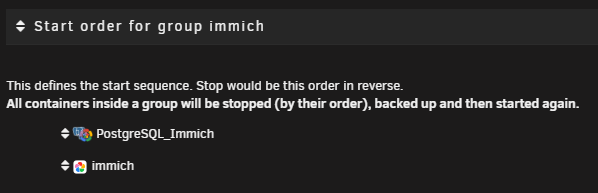
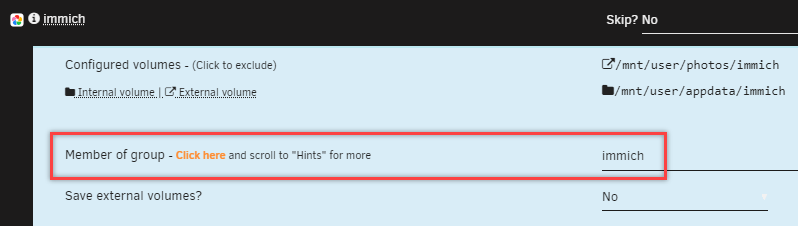
Correct, the Wait/Delay set in the Docker tab is utilized by the Backup/Restore Appdata plugin as well. You can verify this in the logs (see below). Also - groups can be defined in the Backup/Restore Appdata plugin to ensure container dependencies are cared for (discovered this recently). Which can be set by clicking on the docker container when on the settings tab of the Backup/Restore Appdata plugin. Just set the Member of group to the same value for all related docker containers and save (then they will show up like my immich ones above).
-
That is the entirety of the abc.subdomain.conf file for my unraid subdomain located in /mnt/user/appdata/swag/nginx/proxy-confs/ You may have a slightly different path to the proxy-confs folder though, depending on your setup.
-
I quoted part of my post from way earlier in the thread, the next thing I'd suggest is capturing some packets to inspect/investigate with WireShark or similar tool. Just switch out the IP in the command below for the one of the machine you are using to SSH into unRaid with. Then take the .pcap file into WireShark and see if there are any oddities, feel free to share the .pcap if you'd like (DM it so you don't have to post potentially identifying IP info to the world). tcpdump -i any -nn -t -e dst not 192.168.0.254 and src not 192.168.0.254 -w unraid.pcap Refer to my older post for more info/instruction. Definitely make sure to reduce network traffic to clean up the tcpdump (turn off Dockers & VMs). https://forums.unraid.net/topic/96835-dns-resolution-issues/?do=findComment&comment=892657
-
What address are you pinging... a domain or an IP? Are the results of these two commands the same? and same initial delay? ping ns1.google.com ping 216.239.32.10 Are the VM's being assigned their own IP addresses? Same subnet as host unRaid machine? Are they assigned the same or different DNS servers?
-
After resetting my Plex account password I ran into this same issue. Solved it by doing 2 things: 1. Following the Remove Certain Entries > Linux instructions at this link (delete 4 PlexOnline attribute/key pairs from Preferences.xml file) https://support.plex.tv/articles/account-requires-password-reset/ 2. Following the Sign In/Claim Your Plex Media Server > Docker instructions at this link (to generate a new claim token) https://support.plex.tv/articles/account-requires-password-reset/ Once I updated the claim token in the docker's config and clicked Apply, the docker restarted. I immediately went to http://unraidIP:32400/web in an incognito browser and signed in. Everything was restored and no further action was needed. Signed back in through a normal Chrome browser and I am 100% back to expected functionality.
-
This is what I've got configured and the progress UI updates, but at a much slower rate than without using the reverse proxy (maybe every 15-30 secs), so often times the entire docker update is completed by the time it updates. When installing/updating larger dockers (like Android Studio) I can see the progress updates come through mid-process. server { listen 443 ssl; listen [::]:443 ssl; server_name unRaidSubdomain.*; include /config/nginx/ssl.conf; client_max_body_size 0; # https://forums.unraid.net/topic/73158-progress-ui-not-working-through-reverse-proxy/page/2/ gzip off; proxy_buffering off; # enable for ldap auth, fill in ldap details in ldap.conf #include /config/nginx/ldap.conf; # enable for Authelia #include /config/nginx/authelia-server.conf; location / { # enable the next two lines for http auth #auth_basic "Restricted"; #auth_basic_user_file /config/nginx/.htpasswd; # enable the next two lines for ldap auth #auth_request /auth; #error_page 401 =200 /ldaplogin; # enable for Authelia #include /config/nginx/authelia-location.conf; include /config/nginx/proxy.conf; proxy_pass https://[unRaidIP]; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "Upgrade"; } } Its been a while, but I think these are all of the additions I made when I was messing with it... In the server block: gzip off; proxy_buffering off; In the location block (my webui is set for HTTPS only): proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "Upgrade";
-
Trying to help here but you'll need to provide more information than just symptoms... What DNS servers are you using? Have you tried others? Which ones? How long after a reboot can you resolve a domain? Minutes, hours, days? Are you using an ISP provided modem/router or have your own equipment? Do you have any "safe browsing" or security services included from your ISP? (like the person above) Are you running through any VPN or proxy connections/services? Are you able to ping 8.8.8.8 from the terminal when the problem is occuring? (that would rule out a more general loss of connectivity) What other troubleshooting steps have you tried aside from just rebooting?
-
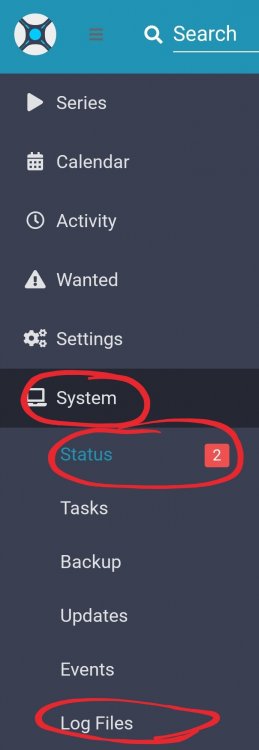
Possible, but unlikely if it is only Sonarr. Would need more information to help troubleshoot, which Sonarr container you are using for starters. Also, rather than rebooting your whole server, have you tried just restarting the container? Verifying a DNS resolution issue with one container would also require getting into it's own shell, are you familiar with that? (it's easy after setting up the docker-shell script) If it's binhex's Sonarr container I would highly recommend shifting your dialog to his support thread here. Occasionally I see indexers not working in Sonarr/Radarr simply because the API's limit has been reached for whatever "request per time period" it is restricted to. Nothing to fix that particular issue aside from waiting. Have you check for errors under System > Status & System > Log Files?
-
It is entirely possible that your ISP is blocking outbound requests on port 53 (DNS). Quoting that answer so you don't have to click the link... "Yes, they can block custom DNS - and its fairly trivial. All they need to do is block port 53 exiting their network (except from their nameservers - but in practice its more likely to be from their broadband IP ranges) The logical reasons for doing this include (which I vehemently disagree with, but thats besides the point) tracking usage, forcing traffic to local caches, blocking access to certain sites, injecting adverts instead of errors for non-existent domain names. There could theoretically also be benefits to you (prevent some kinds of malware, faster DNS resolution times for people with wrong DNS settings)" To test if they are, just run this at the terminal: telnet 8.8.8.8 53 If it times out/fails to connect then your ISP is blocking outbound requests on port 53. This is what my successful result looks like (not blocked):
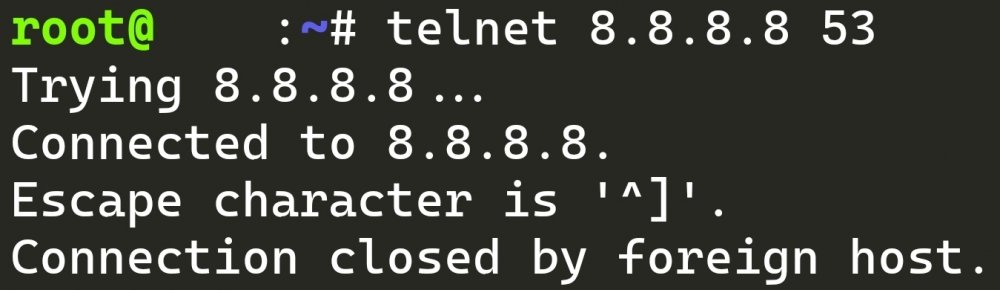
-
Wow... 10gig - impressive for in-the-home speed availability! 💪 I'm not sure if I mention this anywhere, but the one thing that did change in my setup was the firewall (but not the config). Went from an old Zyxel USG50 to a Zyxel VPN100... maybe some differences in the firmware that cause it to handle DNS requests differently. I have updated the VPN100's firmware a couple times since this issue but haven't bothered to take my array offline to test going back to using OpenDNS rather than my router's IP for the DNS entry in unRaid. As far as ISP, I've always been on a dual-WAN setup through a basic Arris coax modem (SB6141 before, SB8200 now) and Zyxel firewall (USG50 before, VPN100 now), with 1gig (now 1.2gig) Xfinity/Comcast as the primary and CenturyLink/Level3 as failover-only (no round robin or least-load-first because clink is SO slow (20/1Mbps)). If you don't have much configurability with the ISP provided fiber box... have you tried altering the DNS entries within unRaid (Settings > Network) to test using public DNS options as well as your default gateway/fiber box IP?
-
What worked for me was (strangely) setting the first DNS entry to my router's default gateway... typically something like 192.168.1.1 unless you have a custom subnet setup. Worth a try - but IMO setting up a custom network is more fun than using ISP provided equipment. ☺️
-
Did you fix the typo? See the blue text in my post above
-
Please provide the DNS entries you see when using both of the configurations... the finest details can be the culprit with these types of issues (see my post above for all I went through) These can be acquired from Settings > Network Settings or the results from cat /etc/resolv.conf at the command line





