




unr41dus3r
Members
-
Joined
-
Last visited
Everything posted by unr41dus3r
-
Yeah but the problem is i cant mount a share which is only set to Read Only on the Server Side, i can only mount a share which is set to RW (read write mode) on the server I want to limit the rights on the server in the first place and the limit on the client how i mount the share would be in 2nd place.
-
A bug or feature request? I want to mount a NFS Share in Read Only mode, BUT i want to achieve this from the Dst Server and not from the Src. Unraid Server. My problem, 2 unraid servers and one will be a NFS Server and one the client. When i configure the server with the Rule "serverIP(sec=sys,rw)" i can connect fine with unassigned devices from the Src unraid server and i will use "Read Only" Mode. Problem, when i use the rule "serverIP(sec=sys,r)" (without W) then i cant mount the share from the Src. unraid server. It doesnt matter if i use the "Read Only" Button or not.
-
Is it possible to use an AMD APU? 5650G in my Case. I found the parameter, --runtime=nvidia and i read on the sygil github, AMD should be possible but i couldnt find any parameters
-
I dont know if this was asked already, but would it be possible to keep the folder view expanded after i start a container or do something else in a folder?
-
Thank you very much! Nothing more to add
-
Feature Request for System Temp and System Auto Fan. A option to give the Fan and Name. In my system all fans are called Array Fan and it would be great if i could name a Fan. Example: Fan 1 = CPU Fan 2 = Case CPU Fan 3 = Case HDD Fan 4 = Font Fan Fan 5 = Rear Fan
-
It is working fine! No email tonight and the mover force task ran. This means the change from "2>/dev/null\" to "&> /dev/null\" fixed my problem with the emails!
-
Its fixed ! As i see in my short testing. (will see definitly tonight) I did edit the "/usr/local/emhttp/plugins/ca.mover.tuning/updateCron.php" file and replaced the logging part: ".../usr/local/sbin/mover.old start &> /dev/null\n\n ..." Then i set a new time in the advanced mover schedule setting and the mover run without sending an email! About your questions 1. it never send an email (didnt matter if i used 2 or &) 2. didnt test now it because &> fixed it (as i remember the mover.old cron line was removed and only the original mover schedule was there) This are the 2 mover lines in my cron file now: # Generated mover schedule: 0 */6 * * * /usr/local/sbin/mover |& logger # Generated schedule for forced move 0 */24 * * * /usr/local/sbin/mover.old start &> /dev/null Is mover.old correct in my system?
-
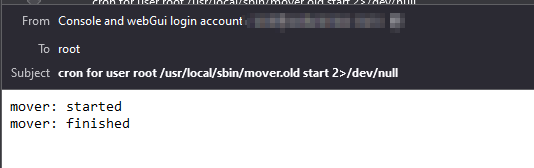
Thanks I think it isnt working to edit the file normally. Is it possible to reload the root file? When i chance the time for example it doesnt will be executed. When i use update_cron command to reload cron (i found in the forums) the command will be resettet to 2> Edit: But i found something else. When i use "/usr/local/sbin/mover.old start 2>/dev/null" in the CLI the information about mover: started mover: finished is written in the CLI When i use "/usr/local/sbin/mover.old start &> /dev/null" there is no output in the CLI
-
Thanks for the response. Tested your steps 1.) Logging was disabled. I enabled the setting and tested a scheduled force run and recieved the same error (same log in syslog) 2.) I still dont recieve the email when i manually start the mover process and enable "Move Now button follows plug-in filters:" 3.) No difference if i enable Test Mode or disable, Log looks the same 4.) Did a uninstall, sadly didnt help. (uninstall, reboot, install) 5.) No other plugin or log message looks like the message from the mover schedule. So sadly no solution, but still interesting, that also the "Move Now button follows plug-in filters:" does not create the error. Only if the task runs with the cron.d About my comment, that i recieve the message since 6.12 RC. What also is possible that i recieve the message since i use a ZFS cache pool, but cant say this for sure. Is it possible that it happens because of ZFS and something like "zfs destroy/create/..." Edit: I also recieve the error if i disable all alerts in Unraid. Really strange Edit 2: I am no expert with Linux CLI etc. and maybe it nothing but one thing is confusing me. mover.old in the /etc/cron.d/root is the only command which uses the parameter "2>/dev/null" to send the log into the black hole. All other commands in my root file are using "&> /dev/null" or "> /dev/null 2>&1" or > "/dev/null 2>&1", which are sending no mails. Maybe its nothing but still one of the little things.
-
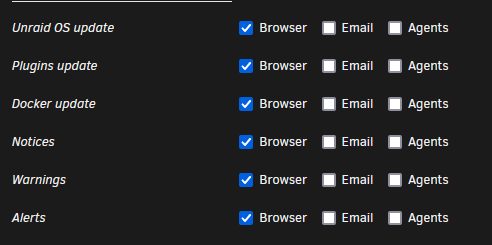
It looks normal? Is the command mover.old? I deleted the entry and reapply the setting, the entry is back. This is the email i recieve: Do you know where it logs this? mover: started and mover: finished?

-
Can i provide any info for you to check this problem? I did missconfigured my smtp settings and the mail failed, so the mover/cron is using the smtp settings. I checked the syslog but nothing interesting in the timeframe when the force mover is running. I did already an uninstall of the plugin, is this deleting all related information to the plugin?
-
Hey, anybody what this error means in syslog? 6.12.1 I have netdata in a docker container running but i get this error from time to time PD[debugfs][1641]: segfault at 153581b493b0 ip 0000559fa640fdf6 sp 000015358681ec00 error 4 in netdata[559fa6279000+3e7000] likely on CPU 3 (core 3, socket 0)
-
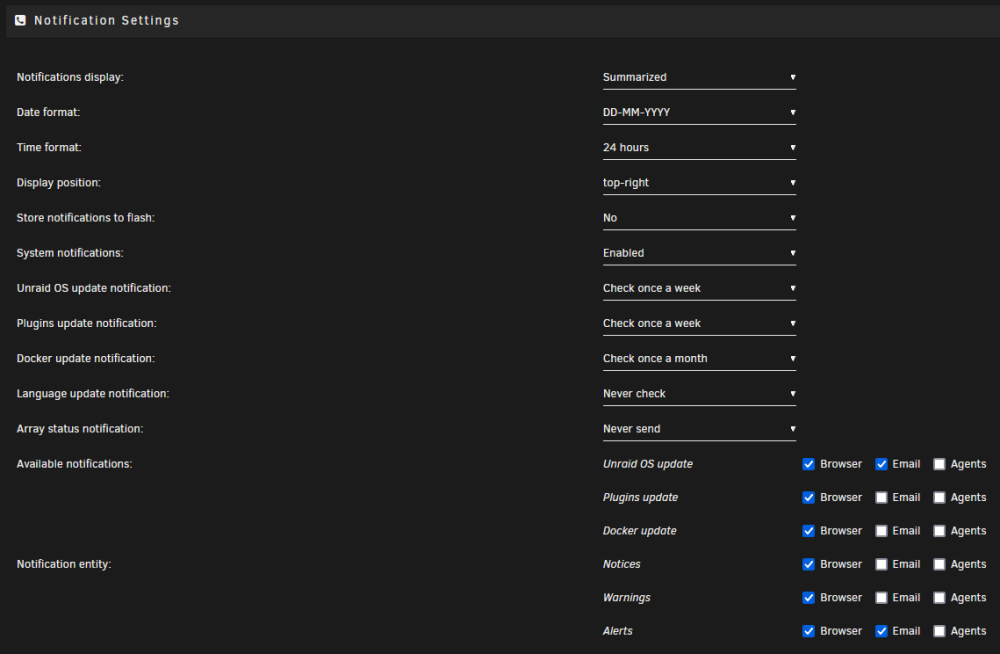
Thanks for checking, this is my notification page:
-
I have the problem that i recieve every night an email notification about the force mover run. I configured to 00:00 and every time it runs it sends me the log per mail, i set also an different time to run the force mover and the notification switches. It is possible that it is an old setting which i set, but i cant find any information: subject of mail: cron for user root /usr/local/sbin/mover.old start 2>/dev/null Message: (if files will be moved, they are logged also) mover: started mover: finished Edit: This happens since upgrade to 6.12 RC Releases
-
Do you use an custom network on the working/not working box? Name resolution inside a internal docker network is only working on a custom network and does not work on the bridge network.
-
Did you remove the database and tried to create a new one? Would rename the sonarr folder in the appdata folder, so you have the old files. If a new database is working, you should ask in radarr/sonarr forum around how to repair the old/ corrupt database. Did you stop the docker service before running mover? With prefer it should move the files from array to cache as i know
-
Anybody know if the plugin is still maintained and will be updated? I dont wanna but pressure on any developer. I only would like to know if i should switch to disable the plugin because the arrangement of the dockers would be important because of dependencies. Thanks
-
Is this a firefox bug or is it a bug from unraids web gui with firefox engine? It would be great if this could be fixed, i dont wanna use/support a chromium based browser. Another annoyance i have sometimes with firefox, after unlocking raid it is asking me to refresh page or stay on page, if i press "cancel" / stay on page everything works fine. If i refresh the page the gui is broken Thanks for your hard work
-
Hi everyone, i dont know if this is a Unraid, Docker or Borgmatic problem. (Using RC8) I want todo the following. Create ZFS Snapshot of dataset appdata for borgmatic cache-mirror/appdata zfs snapshot cache-mirror/appdata@borgmatic Mount the complete cache-mirror pool into borgmatic container /mnt/cache-mirror to /mnt/cache-mirror Try to backup /mnt/cache-mirror/appdata/.zfs/snapshot/borgmatic Problem: If Container is started BEFORE the snapshot is created, i recieve this error when i want to access the folder: dir_open: [Errno 40] Symbolic link loop: 'borgmatic' this happens with the 'ls' command and with borgmatic Solution: If Container is started AFTER the Snapshot is created, it works fine Next problem: Every time the container is started AFTER the Snapshot is created (Solution), i cant delete the snapshot afterwards. It doesnt matter if the borgmatic container is stopped or not. cannot destroy snapshot cache-mirror/appdata@borgmatic: dataset is busy Sometimes (couldnt reproduce it every time) when the container is started BEFORE the snapshot is created (when access in the container is not working to the snapshot (.zfs folder), a snapshot destroy is possible. It is possible i use the snapshot command wrong or should do this another way, but because its ZFS maybe there is another problem in the RCs @JorgeB sorry for pinging you directly but we communicated already in the RC7 thread and maybe this is related to the other dataset is busy problems. Edit: Can you tell me how i could force remove the snapshot or unmount? I do every time a reboot if the error happens because the force unmount or force delete snapshot commands dont work for me.
-
Hey everyone, as i understand the Estimated finish time of a parity check is based on the current Speed of the HDDs As the HDDs are getting slower the estimated finish time is most of the time miscalculated. My idea now is, when the Array configuration did not change from the last run, use this time for the estimated finish. For a little bit more accurated time, you could additionally use the elapsed time with the % Status of the last run and current running job to get an better estimated finish time. So we could use this to calculate the estimated time (really simple example) (time needed last run, to complete run) - (time needed last run, to achieve x%) + (time needed current run, to achieve x%) = estimated time current run Example calculate 25% estimate last Run (finished after 10 hours) Finished 25% after 2 hours Current Run (needs to calculated) Finished 25% after 2:30 hours Example calculation at the 25% mark and example times above 10hours (time needed last run to complete) - 2 hours (time needed last run for 25%) + 2:30 hours (time needed current run for 25%) = 8:30 hours minimum estimate to finish current run If the current run is faster, it would work the same way. I know if the array is strongly in use while the check is running, the time differs again, but at the moment the estimated finish time is worse i would say
-
Hi, danke für die Antwort, habe ich total übersehen. Nach vielen suchen bin ich draufgekommen, dass es sich dabei um das Docker Image gehandelt hat. Habe das Image neu erstellt und der Fehler war weg bzw. bin ich mittlerweile auf Docker Folder umgestiegen.
-
Will the @Squid Docker Folder Plugin be fixed for 6.12 ? I use RC6 and the problem is i cant sort my containers in the folders. This would be necessary for dependencies. Thanks for your work
-
Hi everyone, quick question, i am thinking about to add a graphics card into my unraid server. It would be a 7900XT and as i know the idle power consumption is high. Would this be the same if the VM is not running and disconnect from the unraid system (only in use if vm is running) Best regards
-
Hi Leute, ich habe ein kleines Problem. Mir ist in netdata aufgefallen, dass anscheinend ein BTRFS Pool errors aufweist. Habe darauf hin auf meinen beiden BTRFS Pools (Raid 1 mit 2 Disks + einmal Single Disk Pool) Scrub laufen lassen, was keinen Fehler findet. Im nächsten Schritt ist mir erst aufgefallen das netdata 4 BTRFS Pools anzeigt obwohl ich nur 2 im Einsatz habe. Ich vermute dies ist ein alter Pool der mit einer alten Disk Probleme gemacht hat. Habe das Cache Array aber bereits gelöscht und die Disk entfernt. Wenn ich nun den Ordner "/sys/fs/btrfs/" mit ls prüfe sehe ich dort auch 4 "Ordner" und auch den Problematischen. Da ich mir nicht komplett sicher bin was los ist, wollte ich fragen ob ich solch einen Ordner entfernen kann bzw. prüfen kann ob hier auch wirklich nichts mehr im Einsatz ist? Status: Pool 1 - 2 Disks = UUID: b5f48a8e-3cfb-436e-bbc8-233cb498d28c Status; Pool 2 - 1 Disk = UUID: fcadba9d-cb01-40a0-b31c-51cf51e33406 Im btrfs folder vorhanden mit "ls" Befehl 427bd3c5-3a21-493b-9da1-f283c337c00e/ b5f48a8e-3cfb-436e-bbc8-233cb498d28c/ features/ acc67e5b-c774-46f7-9faa-029b2ebc0e00/ fcadba9d-cb01-40a0-b31c-51cf51e33406/





