




helpermonkey
Members
-
Joined
Everything posted by helpermonkey
-
Hi, I'm having trouble accessing the GUI - the docker seems to start okay and I'm on Unraid 6.8.3. I'm not entirely sure what's going on but I grabbed this log off the Unraid docker GUI: https://pastebin.com/m1vRwqwC Any suggestions?
-
cool - glad it helped contribute and wasn't a complete waste of everyone's time 🙂
-
@binhex that was it! the password was too long. Odd that it has worked for years but anywho - all good now.
-
yeah - its my Pxxxxxxx but my password is over 99 characters. I'll shorten that up right now and give that a try. I'll be back momentarily.
-
yup - i did that already - i entered in the password and userid i use to login to the website. I've checked it in the container settings and i've checked it the credentials file that's created in the openvpn directory and it matches my credentials. I've been setup like that for years. Strange isn't it?
-
Here's my log file 🙂 i've removed my userid and password. supervisord.log
-
that was a great suggestion! (sadly it didn't work) but i appreciate the help and definitely know that they can' sometimes repackage things for those that are logged in versus those that arent. Strange. FWIW in case anyone else reads this - here is the error message: 2020-11-09 13:55:13,017 DEBG 'start-script' stdout output: [info] Starting OpenVPN (non daemonised)... 2020-11-09 13:55:13,022 DEBG 'start-script' stdout output: 2020-11-09 13:55:13 DEPRECATED OPTION: ncp-disable. Disabling cipher negotiation is a deprecated debug feature that will be removed in OpenVPN 2.6 2020-11-09 13:55:13,022 DEBG 'start-script' stdout output: 2020-11-09 13:55:13 DEPRECATED OPTION: --cipher set to 'aes-256-gcm' but missing in --data-ciphers (AES-256-GCM:AES-128-GCM). Future OpenVPN version will ignore --cipher for cipher negotiations. Add 'aes-256-gcm' to --data-ciphers or change --cipher 'aes-256-gcm' to --data-ciphers-fallback 'aes-256-gcm' to silence this warning. 2020-11-09 13:55:13 WARNING: file 'credentials.conf' is group or others accessible 2020-11-09 13:55:13 OpenVPN 2.5.0 [git:makepkg/a73072d8f780e888+] x86_64-pc-linux-gnu [SSL (OpenSSL)] [LZO] [LZ4] [EPOLL] [PKCS11] [MH/PKTINFO] [AEAD] built on Oct 27 2020 2020-11-09 13:55:13 library versions: OpenSSL 1.1.1h 22 Sep 2020, LZO 2.10 2020-11-09 13:55:13,022 DEBG 'start-script' stdout output: 2020-11-09 13:55:13 NOTE: the current --script-security setting may allow this conf
-
so i have verified that my username and password are correct - i do see where it says you should only use simple alpha numeric numbers; however, i have had the same password for years so that can't be the problem. Perhaps the logs i posted in this recent thread might help us figure out what's going on:
-
i have - i've used CA Montreal and Netherlands and keep getting that message. Currently trying CA Montreal and this is what the top of that file looks like: client dev tun proto udp remote ca-montreal.privacy.network 1198 resolv-retry infinite nobind persist-key cipher aes-256-gcm ncp-disable auth sha1 tls-client remote-cert-tls server auth-user-pass credentials.conf compress verb 1 <crl-verify> here's the recent log: 2020-11-07 23:02:03,600 DEBG 'start-script' stdout output: 2020-11-07 23:02:03 DEPRECATED OPTION: --cipher set to 'aes-256-gcm' but missing in --data-ciphers (AES-256-GCM:AES-128-GCM). Future OpenVPN version will ignore --cipher for cipher negotiations. Add 'aes-256-gcm' to --data-ciphers or change --cipher 'aes-256-gcm' to --data-ciphers-fallback 'aes-256-gcm' to silence this warning. 2020-11-07 23:02:03,601 DEBG 'start-script' stdout output: 2020-11-07 23:02:03 WARNING: file 'credentials.conf' is group or others accessible 2020-11-07 23:02:03 OpenVPN 2.5.0 [git:makepkg/a73072d8f780e888+] x86_64-pc-linux-gnu [SSL (OpenSSL)] [LZO] [LZ4] [EPOLL] [PKCS11] [MH/PKTINFO] [AEAD] built on Oct 27 2020 2020-11-07 23:02:03 library versions: OpenSSL 1.1.1h 22 Sep 2020, LZO 2.10 2020-11-07 23:02:03,601 DEBG 'start-script' stdout output: 2020-11-07 23:02:03 NOTE: the current --script-security setting may allow this configuration to call user-defined scripts 2020-11-07 23:02:03,601 DEBG 'start-script' stdout output: 2020-11-07 23:02:03 CRL: loaded 1 CRLs from file -----BEGIN X509 CRL----- MIICWDCCAUAwDQYJKoZIhvcNAQENBQAwgegxCzAJBgNVBAYTAlVTMQswCQYDVQQI EwJDQTETMBEGA1UEBxMKTG9zQW5nZWxlczEgMB4GA1UEChMXUHJpdmF0ZSBJbnRl cm5ldCBBY2Nlc3MxIDAeBgNVBAsTF1ByaXZhdGUgSW50ZXJuZXQgQWNjZXNzMSAw HgYDVQQDExdQcml2YXRlIEludGVybmV0IEFjY2VzczEgMB4GA1UEKRMXUHJpdmF0 ZSBJbnRlcm5ldCBBY2Nlc3MxLzAtBgkqhkiG9w0BCQEWIHNlY3VyZUBwcml2YXRl aW50ZXJuZXRhY2Nlc3MuY29tFw0xNjA3MDgxOTAwNDZaFw0zNjA3MDMxOTAwNDZa MCYwEQIBARcMMTYwNzA4MTkwMDQ2MBECAQYXDDE2MDcwODE5MDA0NjANBgkqhkiG 9w0BAQ0FAAOCAQEAQZo9X97ci8EcPYu/uK2HB152OZbeZCINmYyluLDOdcSvg6B5 jI+ffKN3laDvczsG6CxmY3jNyc79XVpEYUnq4rT3FfveW1+Ralf+Vf38HdpwB8EW B4hZlQ205+21CALLvZvR8HcPxC9KEnev1mU46wkTiov0EKc+EdRxkj5yMgv0V2Re ze7AP+NQ9ykvDScH4eYCsmufNpIjBLhpLE2cuZZXBLcPhuRzVoU3l7A9lvzG9mjA 5YijHJGHNjlWFqyrn1CfYS6koa4TGEPngBoAziWRbDGdhEgJABHrpoaFYaL61zqy MR6jC0K2ps9qyZAN74LEBedEfK7tBOzWMwr58A== -----END X509 CRL----- 2020-11-07 23:02:03,601 DEBG 'start-script' stdout output: 2020-11-07 23:02:03 TCP/UDP: Preserving recently used remote address: [AF_INET]199.36.223.162:1198 2020-11-07 23:02:03 UDP link local: (not bound) 2020-11-07 23:02:03 UDP link remote: [AF_INET]199.36.223.162:1198 2020-11-07 23:02:03,727 DEBG 'start-script' stdout output: 2020-11-07 23:02:03 [montreal411] Peer Connection Initiated with [AF_INET]199.36.223.162:1198 2020-11-07 23:02:04,729 WARN received SIGTERM indicating exit request 2020-11-07 23:02:04,729 DEBG killing watchdog-script (pid 173) with signal SIGTERM 2020-11-07 23:02:04,729 INFO waiting for start-script, watchdog-script to die 2020-11-07 23:02:04,746 DEBG fd 11 closed, stopped monitoring <POutputDispatcher at 23342285760160 for <Subprocess at 23342286252352 with name watchdog-script in state STOPPING> (stdout)> 2020-11-07 23:02:04,746 DEBG fd 15 closed, stopped monitoring <POutputDispatcher at 23342285988768 for <Subprocess at 23342286252352 with name watchdog-script in state STOPPING> (stderr)> 2020-11-07 23:02:04,746 INFO stopped: watchdog-script (terminated by SIGTERM) 2020-11-07 23:02:04,747 DEBG received SIGCHLD indicating a child quit 2020-11-07 23:02:04,747 DEBG killing start-script (pid 172) with signal SIGTERM 2020-11-07 23:02:04,896 DEBG 'start-script' stdout output: 2020-11-07 23:02:04 AUTH: Received control message: AUTH_FAILED is it possible that it's having a problem b/c I have 2 factor enabled on PIA? I can't imagine that's it b/c that's been in place for a long long time but that's the only thing i can think of ... shrug.
-
is there anything else i can share with you to see what might be going on with my setup? I have followed that Q22 tutorial and that did not seem to fix the problem.
-
yup - that's what i'm using.
-
So I downloaded the 4th gen configuration files from here: https://www.privateinternetaccess.com/helpdesk/kb/articles/where-can-i-find-your-ovpn-files and vancouver isn't an option but i did switch to DE Frankfurt and made the adjustments suggested in this thread by @binhex and others and it's still not working :-(. what version of the config files are you using?
-
they are also in my container settings.... i just double checked and had no problem signing into the PIA website from my browser and all of my other clients are logging in without a problem.
-
so how would i do that? in my credentials.conf file - the first line is my userid for PIA and the second line is my password that i login to the website with.
-
Thanks - so i gave that a twirl and i'm still getting some errors ... here is the log file on pastebin here is the .ovpn file minus the cert and the X509 portion.... client dev tun proto udp remote ca-toronto.privacy.network 1198 resolv-retry infinite nobind persist-key cipher aes-256-gcm ncp-disable auth sha1 tls-client remote-cert-tls server auth-user-pass credentials.conf compress verb 1 <crl-verify>
-
excellent - thanks! so in my config file i see: cipher aes-128-cbc but none of the other ones ... so do i just add cipher aes-256-gcm ncp-disable or do i also remove "cipher aes-128-cbc"
-
Hi there, So last night - my docker container wouldn't startup - i checked the log and saw a message about my PIA endpoint not working b/c it's been phased out ... so I visited this PIA page and downloaded "OPENVPN CONFIGURATION FILES (DEFAULT)". I put the CA-Toronto end point on my server and relaunched delugeVPN. The container will start but I am unable to access it via gui. I looked at the log and here is the latest error: 2020-11-06 01:59:06,469 DEBG 'start-script' stdout output: 2020-11-06 01:59:06 DEPRECATED OPTION: --cipher set to 'aes-128-cbc' but missing in --data-ciphers (AES-256-GCM:AES-128-GCM). Future OpenVPN version will ignore --cipher for cipher negotiations. Add 'aes-128-cbc' to --data-ciphers or change --cipher 'aes-128-cbc' to --data-ciphers-fallback 'aes-128-cbc' to silence this warning. 2020-11-06 01:59:06,469 DEBG 'start-script' stdout output: 2020-11-06 01:59:06 WARNING: file 'credentials.conf' is group or others accessible 2020-11-06 01:59:06 OpenVPN 2.5.0 [git:makepkg/a73072d8f780e888+] x86_64-pc-linux-gnu [SSL (OpenSSL)] [LZO] [LZ4] [EPOLL] [PKCS11] [MH/PKTINFO] [AEAD] built on Oct 27 2020 How would i go about fixing this?
-
having a lot of trouble with sonarr --- seems to be tied to mono ... any ideas? https://paste.ubuntu.com/p/FVW2N4V6Dd/ Not really sure what to do :-)
-
bumping as i'd still love some help with this.
-
hey folks - so I need help with a problem + a little hand holding/how-to. First, when I go to setup the docker, it fails to start because it wants to map to port 8080 for device communication (i have sabnzbd on port 8080). So to that end, is there a recommended alternative port? I'd rather not adjust sab b/c of how many other utilities rely on it. Then my next question is what's a good "Idiots Guide to Moving Controllers"? I setup my unifi a long time ago and when i did it - i did not realize that the device married itself to the controller - i no longer have the computer that was the original controller. Furthermore - i don't remember all of the tweaks i made to the configuration and finally - while i would like to use my unraid server as the controller - i usually use wifi to connect into it - so i'm guessing that i'll need to attach KVM to it and i just want to make sure I don't screw it up. I looked at this https://community.ui.com/questions/Transferring-Unifi-Controller/1e541dee-e484-407e-aaec-28c2711db6d7 but when i go to wizards in EdgeOSX i get Any advice would be welcomed.
-
yup - i had netherlands in there - just found out it was bunk and fixed it by moving to toronto 🙂 woot.
-
So a few months back my delugevpn stopped working ... i didn't decide to fix it until now and looking at the log file i see this: Created by... ___. .__ .__ \_ |__ |__| ____ | |__ ____ ___ ___ | __ \| |/ \| | \_/ __ \\ \/ / | \_\ \ | | \ Y \ ___/ > < |___ /__|___| /___| /\___ >__/\_ \ \/ \/ \/ \/ \/ https://hub.docker.com/u/binhex/ 2019-06-13 00:23:18.241690 [info] System information Linux 072d4aa08eae 4.19.41-Unraid #1 SMP Wed May 8 14:23:25 PDT 2019 x86_64 GNU/Linux 2019-06-13 00:23:18.278918 [info] PUID defined as '99' 2019-06-13 00:23:18.568110 [info] PGID defined as '100' 2019-06-13 00:23:18.873367 [info] UMASK defined as '000' 2019-06-13 00:23:18.892447 [info] Setting permissions recursively on volume mappings... 2019-06-13 00:23:19.114592 [info] DELUGE_DAEMON_LOG_LEVEL defined as 'info' 2019-06-13 00:23:19.133916 [info] DELUGE_WEB_LOG_LEVEL defined as 'info' 2019-06-13 00:23:19.153238 [info] VPN_ENABLED defined as 'yes' 2019-06-13 00:23:19.193262 [crit] No OpenVPN config file located in /config/openvpn/ (ovpn extension), please download from your VPN provider and then restart this container, exiting... Created by... ___. .__ .__ In case the problem is with OpenVPN ... my log file basically just says this: ./run: line 3: /usr/local/openvpn_as/scripts/openvpnas: No such file or directory i cannot launch the webui for my vpn either .... so if it's a problem with that - i will ask in the appropriate place.
-
Prudent advice - thanks!
-
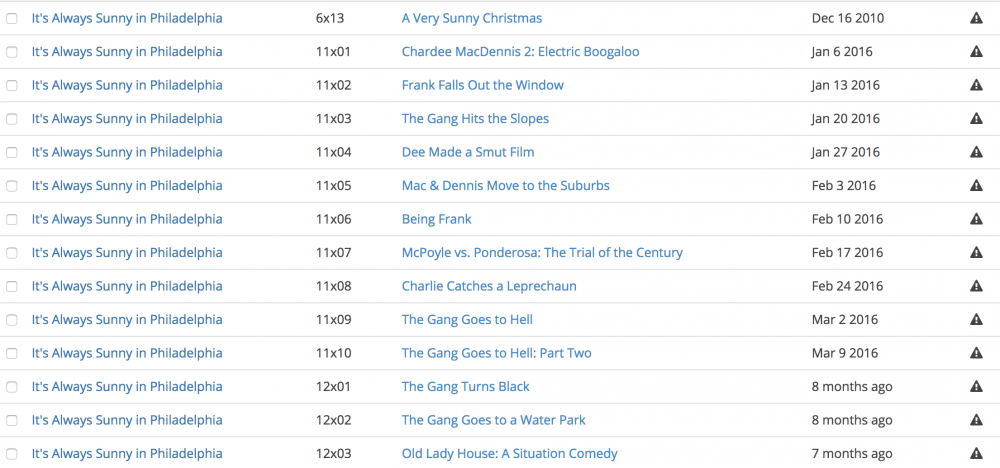
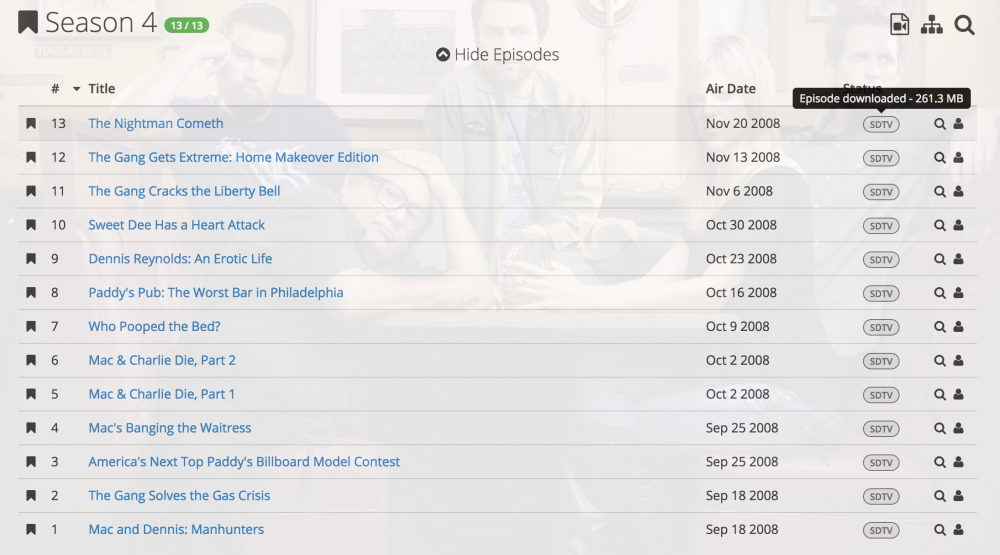
Gotcha - I had: /data /mnt/user/Downloads/Sabnzbd/ /data /mnt/user/Downloads/Sonarr/ Will Sonarr rename stuff already in that folder or do i need to run them through filebot and move them manually? I thought I had done that properly but i can't tell. So here's is a screen shot of a profile i've setup for quality - the show page for S04 of IASIP and the Wanted Page.... the existing episodes don't show up on the wanted even though i've got them highlighted to do so...

-
Yeah, i'm getting the "no files found are eligible for import" display in my history - but in looking at my file permissions, i have things set to 777. i have zero idea how to fix this problem ... is there a log file i can post here that might help someone tell me what i'm doing wrong?



