




Strayer
Members
-
Joined
-
Last visited
Everything posted by Strayer
-
Of course, no rush! I wasn't sure if you'd rather like to handle contributions here or on Github, so I decided to… uhh, spam, I guess… sorry about that
-
Hey @ich777, thanks for supporting these plugins! I recently tried out the smartctl exporter and opened a PR for more NVMe data: https://github.com/ich777/unraid-prometheus_smartctl_exporter/pull/1 May I ask why you never released the plugin? It works fine for me. I read the comments about spinning up sleeping disks, which is not a problem for me. Is that the only reason? I saw some code that should avoid this, so I assume this was already fixed? I think its a fine addition to the plugin list!
-
So, preface: I know what I'm doing here is unsupported, but I now know what is happening and want to document it in case somebody else runs into this. As I mentioned in my edit, this was 100% related to the ip6tables option of Docker. At first I didn't assume this would actually have any influence on VMs running through the br0 bridge, since usually that traffic shouldn't be affected by iptables at all, but, and I didn't realize this beforehand, Docker loads the br_netfilter kernel module that is actually causing traffic on bridge interfaces to be handled by iptables too (see link at the end of this post for technical details). The actual problem: After Docker started with the ip6tables option enabled, it set the default FORWARD policy for IPv6 to DROP. That policy caused all IPv6 traffic to not be passed from the VM to my local network and vice versa. This is explicitly done by Docker itself (see here for the relevant code in the patch that introduced ip6tables to Docker). I noticed that the default FORWARD policy for IPv4 was ACCEPT, this is why this didn't cause any issues for IPv4 traffic to the VMs. The workaround in my case was to simply add a new rule on ip6tables and everything seems to work fine: ip6tables -A FORWARD -i br0 -o br0 -j ACCEPT Now, what I don't understand is why the default FORWARD policy on IPv4 is ACCEPT. Based on Dockers code it should be set to DROP too… I checked the init scripts of Docker and libvirt in Unraid and couldn't find anything… in case anyone from Limetech reads this, I'd love to know if you did anything to make this work for IPv4. A lot more context on Docker, libvirt, bridge interfaces and br_netfilter can be found here: https://serverfault.com/a/964491
-
So, I think this may be related to me enabling ip6tables in Docker using this Docker daemon.json: { "experimental": true, "ip6tables": true } Today IPv6 stopped working for VMs again. After disabling my custom daemon.json and rebooting the Unraid server (which didn't help the last time I worked on this) fixed IPv6 in VMs again. Kind of annoying, since I utilize this to have correct IPv6 port forwarding for my PiHole, but at least I now have something concrete to test. Edit: This is definitely the case. To test this I stopped Docker with /etc/rc.d/rc.docker stop, put the above daemon.json at /etc/docker/daemon.json, startet Docker with /etc/rc.d/rc.docker start and rebooted my VM. After the reboot, the VM couldn't get an IPv6 via SLAAC again.
-
Sadly I again have trouble with this… now none of my Linux VMs get an IPv6 address at all. I recently switched all VMs that were using DHCPv6 to SLAAC and while everything worked fine for a while, I realized there is no IPv6 connectivity at all now. I can see the router solicitation request from the VM with tcpdump: tcpdump -i vnet1 icmp6 tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on vnet1, link-type EN10MB (Ethernet), capture size 262144 bytes 21:05:33.962275 IP6 :: > ff02::1:fff9:6584: ICMP6, neighbor solicitation, who has fe80::5054:ff:fef9:6584, length 32 21:05:34.986326 IP6 fe80::5054:ff:fef9:6584 > ip6-allrouters.lan.gru.earth: ICMP6, router solicitation, length 16 21:05:38.954235 IP6 fe80::5054:ff:fef9:6584 > ip6-allrouters.lan.gru.earth: ICMP6, router solicitation, length 16 21:05:47.146270 IP6 fe80::5054:ff:fef9:6584 > ip6-allrouters.lan.gru.earth: ICMP6, router solicitation, length 16 21:06:04.554282 IP6 fe80::5054:ff:fef9:6584 > ip6-allrouters.lan.gru.earth: ICMP6, router solicitation, length 16 This is also visible on br0. None of those packets are visible when running tcpdump on eth0 or on the router. I don't know how to investigate this further… rebooting the server didn't help this time. All my other devices using SLAAC are getting an IPv6 just fine, this is only happening with VMs on Unraid. Edit: Since I was at a total loss I decided to upgrade to Unraid 6.9.10-rc2 and now the VMs get an IPv6 via SLAAC again. No idea if this was just the reboot or the newer kernel/libvirt fixed anything. Ugh. I'll have to keep an eye on this.
-
I rebooted the Unraid server and now it is working 🤔 Not sure what happened there.
-
It's a standard Debian 11 VM (tried Ubuntu 20.04 too). As far as I can see the ICMP6 packets appear on the br0 interfaces on the Unraid server but don't reach my router, so I assume some multicast packets don't get forwarded for some reason. Any tips on how to further debug this would be appreciated.
-
I'm trying to get a VM running in my local network with IPv4 and IPv6. The VM is getting an IPv4 from my router, but it seems that neither SLAAC nor DHCPv6 are able to get an IPv6. My network config is fairly simple and VMs in VMware Fusion on my Macbook have no trouble getting both an IPv4 and IPv6 from my router via a bridge network. Is this to be expected with Unraid? Do I need to change some settings for this to work? Unraid itself and Docker containers have working IPv6. The VM is in network br0 and both virtio and virtio-net did have this problem.
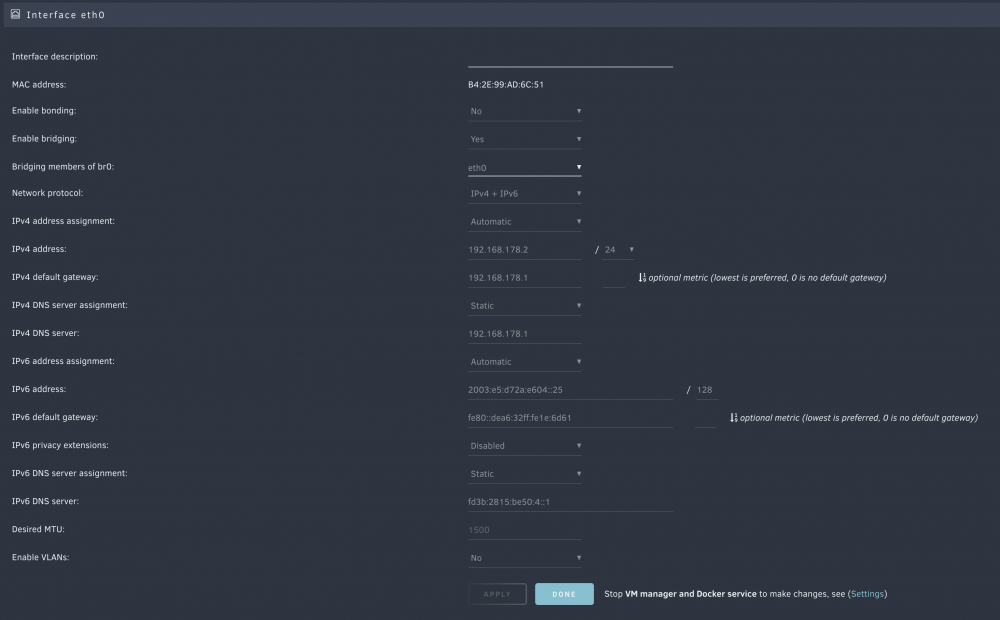
-
Warning is gone now, thanks for looking into this!
-
Thank you! Interesting, thanks for letting me know. I issued a new certificate with the wildcard as its common name and the warning is gone now. Any particular reason why this is unsupported?
-
I seem to have trouble with the new 'Invalid DNS entry for TLD' warning too… it says: "The DNS entry for 'noatun.lan.gru.earth' resolves to 192.168.178.2, you should ensure that it resolves to Array." Not really sure what to do with this… that is the local IP address of the Unraid server. noatun is its name and lan.gru.earth is the local domain. Everything network related works perfectly and has always worked. My local machine resolves this exactly as expected (.1 is my local OpenWRT, .2 is PiHole on the Unraid server, Unraid uses .1): ❯ dig +short @192.168.178.1 noatun.lan.gru.earth 192.168.178.2 ❯ dig +short @192.168.178.2 noatun.lan.gru.earth 192.168.178.2 ❯ host noatun.lan.gru.earth noatun.lan.gru.earth has address 192.168.178.2 noatun.lan.gru.earth has IPv6 address fd3b:2815:be50:4::25 noatun.lan.gru.earth has IPv6 address <redacted> Edit: I also have an incorrect error with "Invalid Certificate 1": "Your noatun_unraid_bundle.pem certificate is for 'lan.gru.earth' but your system's hostname is 'noatun.lan.gru.earth'. Either adjust the system name and local TLD to match the certificate, or get a certificate that matches your settings. Even if things generally work now, this mismatch could cause issues in future versions of Unraid." The certificate I'm using is a wildcard certificate and definitely valid for the server: root@noatun certs ❯ openssl x509 -in /boot/config/ssl/certs/noatun_unraid_bundle.pem -text Certificate: Data: Version: 3 (0x2) [...] Issuer: C = US, O = Let's Encrypt, CN = R3 Validity Not Before: Nov 26 13:29:03 2021 GMT Not After : Feb 24 13:29:02 2022 GMT Subject: CN = lan.gru.earth [...] X509v3 Subject Alternative Name: DNS:*.lan.gru.earth, DNS:lan.gru.earth [...]
-
Nice! Do you work on these plugins in the open? I couldn't find anything on Github, but I may be blind. I'm a bit wary of using precompiled 3rd party kernel modules. Sorry if this comes off rude, but I'd rather compile these myself like with the build script of this topic, where I at least have some kind of oversight on what happens. I wouldn't mind moving less used stuff to a swap space placed in compressed RAM, yes. This is how most modern operating systems work anyway. There are some nice articles on this, I managed to find these that I read a while ago: https://haydenjames.io/linux-performance-almost-always-add-swap-space/ https://haydenjames.io/linux-performance-almost-always-add-swap-part2-zram/ I pretty much started installing Debians zram-tools on all (mostly cloud) servers that I manage and so far didn't run into any issues. That package creates swap on compressed ram disks based on the RAM size and CPU count. But my primary use case is to be able to use compressed ram disks as described with the docker containers in my previous post. Ha, thanks. Have been using the avatar for more than 10 years now and the people who recognized it are shockingly few. I started moving on to a custom commissioned avatar on most of my profiles though, I just forgot to change it here. Now I'm happy that I did forget :D
-
Sorry, I was still playing around with this this morning and didn't finish anything yet. What I did for testing zram was essentially this: modprobe zstd modprobe zsmalloc modprobe zram zramctl -f -s 200MiB -a zstd # returns device name, e.g. /dev/zram0 mkfs.ext4 /dev/zram0 mount /dev/zram0 /tmp/zramtest I would probably throw something like this in my go file with a better mount point than /tmp/zramtest. I'd then use this mount point as a bind mount in the docker-compose.yml of the container I'm running, replacing the current bind mount on the array for the log files. Doing this for swap is mostly the same, except using mkswap and swapon instead of mkfs and mount. Most of the popular zram packages (e.g. zram-tools from Debian) do some percentage calculation to determine how much ram should be used for swap. Thats a very different topic.
-
First of all, thanks for replying! I'm using it as a replacement for tmpfs and because I want to add a little amount of compressed memory for swap (see the various discussions and blog posts about if the Linux kernel benefits from having at least a bit of swap available). Biggest specific use case for me is putting some very VERY verbose debug log files of a container on a compressed ram disk. I don't want to thrash my SSDs with them, but also want to avoid having array disks running because of log files. I can use tmpfs for that, but after testing a bit zram manages to compress the data down to 25% of the initial size. This needs a bit of custom code in a user script or the go file to create the block devices, file systems and mount them, obviously, but I do like the way it works. I definitely see myself using this for more files that don't need to be persisted through reboots. zstd just because it is a bit more efficient at compressing compared to the default lzo. (see e.g.
-
I want to add ZRAM and ZSTD support to my Unraid instance. I assume this helper would be the easiest way to go about this, but I'm wondering about how to use it properly. As far as I can see I can add user patches and user scripts, but the patches are run before 'make oldconfig' and the user scripts after the kernel is compiled. I don't need to patch anything, I only need to enable these config options: CONFIG_ZSMALLOC=m CONFIG_ZRAM=m CONFIG_CRYPTO_ZSTD=m Does this helper have any way to achieve this? For now I add this manually after 'make oldconfig' in the buildscript: cd ${DATA_DIR}/linux-$UNAME ./scripts/config --set-val CONFIG_ZSMALLOC m ./scripts/config --set-val CONFIG_ZRAM m ./scripts/config --set-val CONFIG_CRYPTO_ZSTD m make olddefconfig It seems to have worked fine since I can create zram devices with zstd compression without problems after loading the modules: modprobe zstd modprobe zsmalloc modprobe zram
-
Docker recently gained the option to also set IPv6 NAT rules to forward IPv6 traffic to containers: https://github.com/moby/moby/pull/41622 It is relatively easy to enable, but requires enabling experimental features. As a quick test, I added this daemon.json to a Debian VM that has Docker 20.10 installed: { "ipv6": true, "ip6tables": true, "experimental": true, "fixed-cidr-v6": "fd00:dead:beef::/48" } Now Docker will automatically create IPv6 NAT rules to forward ports to containers: root@debian:~# docker run --rm -p 80:80 nginx [...] fd15:4ba5:5a2b:1008:c87b:a4ed:6798:4006 - - [11/Apr/2021:12:08:29 +0000] "GET / HTTP/1.1" 200 612 "-" "curl/7.64.1" "-" I'm using IPv6 a lot and would love it to be able to forward IPv6 traffic with this option. Not sure when Unraid would be able to update to 20.10, as 6.9 seems to be using 19.03 for now, but I wanted to add this feature request anyway.
-
I played around with this a bit more and changing <timer name='hpet' present='no'/> to yes reduced the idle CPU usage down to ~5% on the Unraid host, which is much more acceptable. I'll have to monitor the VM since I'm not really sure if this has any downsides.
-
I'm running OpenWRT inside a VM that is only used for WireGuard VPN as my router doesn't support it itself. The VM is running at 99-100% idle, according to top inside the VM. The qemu-system-x86 process on the Unraid host on the other hand runs at a constant ~30% CPU usage according to top. Note: I'm on Unraid 6.9.0-rc.2, the system itself is a repurposed QNAP TS-451A with a slow Celeron N3060, so having 30% of the CPU blocked full-time is quite annoying. top in the VM: Mem: 40100K used, 203720K free, 392K shrd, 9608K buff, 8828K cached CPU: 0% usr 0% sys 0% nic 99% idle 0% io 0% irq 0% sirq Load average: 0.00 0.04 0.01 2/64 2088 PID PPID USER STAT VSZ %VSZ %CPU COMMAND 2071 1430 root S 1000 0% 0% /usr/sbin/dropbear -F -P /var/run/dropbear.1.pid -p 22 -K 300 -T 3 1801 1 root SN 3484 1% 0% /usr/sbin/collectd -C /tmp/collectd.conf -f 1591 1 root S 1384 1% 0% /usr/sbin/uhttpd -f -h /www -r OpenWrt -x /cgi-bin -t 60 -T 30 -k 20 -A 1 -n 3 -N 100 -R -p 0.0.0.0:80 1334 1 root S 1320 1% 0% /sbin/rpcd -s /var/run/ubus.sock -t 30 1485 1 root S 1268 1% 0% /sbin/netifd 1 0 root S 1160 0% 0% /sbin/procd 1397 1 dnsmasq S 1120 0% 0% /usr/sbin/dnsmasq -C /var/etc/dnsmasq.conf.cfg01411c -k -x /var/run/dnsmasq/dnsmasq.cfg01411c.pid 2072 2071 root S 1084 0% 0% -ash 2080 2072 root R 1080 0% 0% top 1968 1 root S< 1076 0% 0% /usr/sbin/ntpd -n -N -S /usr/sbin/ntpd-hotplug -p 0.openwrt.pool.ntp.org -p 1.openwrt.pool.ntp.org -p 2 1606 1485 root S 1072 0% 0% udhcpc -p /var/run/udhcpc-eth0.pid -s /lib/netifd/dhcp.script -f -t 0 -i eth0 -x hostname:OpenWrt -C -O 1519 1 root S 1064 0% 0% /usr/sbin/odhcpd 1303 1 root S 964 0% 0% /sbin/logd -S 64 1131 1 root S 888 0% 0% /sbin/ubusd 1430 1 root S 888 0% 0% /usr/sbin/dropbear -F -P /var/run/dropbear.1.pid -p 22 -K 300 -T 3 1146 1 root S 780 0% 0% /sbin/urngd 1133 1 root S 720 0% 0% /sbin/askfirst /usr/libexec/login.sh 1132 1 root S 720 0% 0% /sbin/askfirst /usr/libexec/login.sh top on the Unraid host: top - 22:45:54 up 1 day, 7:22, 1 user, load average: 0.27, 0.47, 0.52 Tasks: 204 total, 1 running, 203 sleeping, 0 stopped, 0 zombie %Cpu(s): 3.7 us, 15.4 sy, 0.0 ni, 80.7 id, 0.2 wa, 0.0 hi, 0.0 si, 0.0 st MiB Mem : 7879.5 total, 184.3 free, 421.6 used, 7273.6 buff/cache MiB Swap: 0.0 total, 0.0 free, 0.0 used. 6412.5 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 29335 root 20 0 620200 181356 22816 S 28.9 2.2 1:55.99 qemu-system-x86 I tried assigning only one or both of the CPU threads, removing all USB devices and switching the machine type from Q35 to i440fx, nothing helped with the idle CPU usage. VM configuration: <?xml version='1.0' encoding='UTF-8'?> <domain type='kvm' id='6'> <name>OpenWRT</name> <uuid>54195be1-b90f-58ad-7843-a526bd2235e3</uuid> <metadata> <vmtemplate xmlns="unraid" name="Linux" icon="linux.png" os="linux"/> </metadata> <memory unit='KiB'>262144</memory> <currentMemory unit='KiB'>262144</currentMemory> <memoryBacking> <nosharepages/> </memoryBacking> <vcpu placement='static'>1</vcpu> <cputune> <vcpupin vcpu='0' cpuset='0'/> </cputune> <resource> <partition>/machine</partition> </resource> <os> <type arch='x86_64' machine='pc-i440fx-5.1'>hvm</type> </os> <features> <acpi/> <apic/> </features> <cpu mode='host-passthrough' check='none' migratable='on'> <topology sockets='1' dies='1' cores='1' threads='1'/> <cache mode='passthrough'/> </cpu> <clock offset='utc'> <timer name='rtc' tickpolicy='catchup'/> <timer name='pit' tickpolicy='delay'/> <timer name='hpet' present='no'/> </clock> <on_poweroff>destroy</on_poweroff> <on_reboot>restart</on_reboot> <on_crash>restart</on_crash> <devices> <emulator>/usr/local/sbin/qemu</emulator> <disk type='file' device='disk'> <driver name='qemu' type='qcow2' cache='writeback'/> <source file='/mnt/cache-sdcard/domains/openwrt/vdisk1.qcow2' index='1'/> <backingStore/> <target dev='hdc' bus='virtio'/> <boot order='1'/> <alias name='virtio-disk2'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x05' function='0x0'/> </disk> <controller type='usb' index='0' model='ich9-ehci1'> <alias name='usb'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x07' function='0x7'/> </controller> <controller type='usb' index='0' model='ich9-uhci1'> <alias name='usb'/> <master startport='0'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x07' function='0x0' multifunction='on'/> </controller> <controller type='usb' index='0' model='ich9-uhci2'> <alias name='usb'/> <master startport='2'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x07' function='0x1'/> </controller> <controller type='usb' index='0' model='ich9-uhci3'> <alias name='usb'/> <master startport='4'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x07' function='0x2'/> </controller> <controller type='pci' index='0' model='pci-root'> <alias name='pci.0'/> </controller> <controller type='virtio-serial' index='0'> <alias name='virtio-serial0'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x04' function='0x0'/> </controller> <interface type='bridge'> <mac address='52:54:00:76:94:0f'/> <source bridge='br0'/> <target dev='vnet0'/> <model type='virtio-net'/> <alias name='net0'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x03' function='0x0'/> </interface> <serial type='pty'> <source path='/dev/pts/0'/> <target type='isa-serial' port='0'> <model name='isa-serial'/> </target> <alias name='serial0'/> </serial> <console type='pty' tty='/dev/pts/0'> <source path='/dev/pts/0'/> <target type='serial' port='0'/> <alias name='serial0'/> </console> <channel type='unix'> <source mode='bind' path='/var/lib/libvirt/qemu/channel/target/domain-6-OpenWRT/org.qemu.guest_agent.0'/> <target type='virtio' name='org.qemu.guest_agent.0' state='disconnected'/> <alias name='channel0'/> <address type='virtio-serial' controller='0' bus='0' port='1'/> </channel> <input type='tablet' bus='usb'> <alias name='input0'/> <address type='usb' bus='0' port='1'/> </input> <input type='mouse' bus='ps2'> <alias name='input1'/> </input> <input type='keyboard' bus='ps2'> <alias name='input2'/> </input> <graphics type='vnc' port='5900' autoport='yes' websocket='5700' listen='0.0.0.0' keymap='en-us'> <listen type='address' address='0.0.0.0'/> </graphics> <video> <model type='qxl' ram='65536' vram='65536' vgamem='16384' heads='1' primary='yes'/> <alias name='video0'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x02' function='0x0'/> </video> <memballoon model='virtio'> <alias name='balloon0'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x06' function='0x0'/> </memballoon> </devices> <seclabel type='dynamic' model='dac' relabel='yes'> <label>+0:+100</label> <imagelabel>+0:+100</imagelabel> </seclabel> </domain>
-
That does make sense, as the TS-451A does include an eMMC module that is used for installing the official QNAP firmware. That would indeed be detected as a drive when the MMC module is available. Maybe it could be built but blacklisted in a way that the user can remove the blacklist entry if they want to use it? I don't mind paying extra for the included eMMC that I wouldn't use. An empty SD slot shouldn't count towards the drive count, as far as I know Linux only shows a block device for the slot if something is in there.
-
I'm running Unraid on a QNAP TS-451A which includes a SD card reader. The kernel in Unraid 6.8.3 and 3.9.0-rc2 doesn't seem to include the relevant kernel configuration. See for example: https://www.thinkwiki.org/wiki/How_to_get_the_internal_SD_card_working The Unraid kernel config doesn't have this enabled: # CONFIG_MMC is not set I'd like to use the SD card slot for a (mostly) read-only storage for Docker container configuration files and such with a high endurance SD card. Currently, SD cards aren't detected at all. root@Tower:~# lspci 00:00.0 Host bridge: Intel Corporation Atom/Celeron/Pentium Processor x5-E8000/J3xxx/N3xxx Series SoC Transaction Register (rev 35) 00:02.0 VGA compatible controller: Intel Corporation Atom/Celeron/Pentium Processor x5-E8000/J3xxx/N3xxx Integrated Graphics Controller (rev 35) 00:10.0 SD Host controller: Intel Corporation Atom/Celeron/Pentium Processor x5-E8000/J3xxx/N3xxx Series MMC Controller (rev 35) 00:13.0 SATA controller: Intel Corporation Atom/Celeron/Pentium Processor x5-E8000/J3xxx/N3xxx Series SATA Controller (rev 35) 00:14.0 USB controller: Intel Corporation Atom/Celeron/Pentium Processor x5-E8000/J3xxx/N3xxx Series USB xHCI Controller (rev 35) 00:1a.0 Encryption controller: Intel Corporation Atom/Celeron/Pentium Processor x5-E8000/J3xxx/N3xxx Series Trusted Execution Engine (rev 35) 00:1b.0 Audio device: Intel Corporation Atom/Celeron/Pentium Processor x5-E8000/J3xxx/N3xxx Series High Definition Audio Controller (rev 35) 00:1c.0 PCI bridge: Intel Corporation Atom/Celeron/Pentium Processor x5-E8000/J3xxx/N3xxx Series PCI Express Port #1 (rev 35) 00:1c.2 PCI bridge: Intel Corporation Atom/Celeron/Pentium Processor x5-E8000/J3xxx/N3xxx Series PCI Express Port #3 (rev 35) 00:1c.3 PCI bridge: Intel Corporation Atom/Celeron/Pentium Processor x5-E8000/J3xxx/N3xxx Series PCI Express Port #4 (rev 35) 00:1f.0 ISA bridge: Intel Corporation Atom/Celeron/Pentium Processor x5-E8000/J3xxx/N3xxx Series PCU (rev 35) 00:1f.3 SMBus: Intel Corporation Atom/Celeron/Pentium Processor x5-E8000/J3xxx/N3xxx SMBus Controller (rev 35) 01:00.0 SATA controller: ASMedia Technology Inc. Device 0625 (rev 01) 02:00.0 PCI bridge: ASMedia Technology Inc. Device 1182 03:03.0 PCI bridge: ASMedia Technology Inc. Device 1182 03:07.0 PCI bridge: ASMedia Technology Inc. Device 1182 04:00.0 Ethernet controller: Realtek Semiconductor Co., Ltd. RTL8111/8168/8411 PCI Express Gigabit Ethernet Controller (rev 06) 05:00.0 Ethernet controller: Realtek Semiconductor Co., Ltd. RTL8111/8168/8411 PCI Express Gigabit Ethernet Controller (rev 06) 06:00.0 Ethernet controller: Realtek Semiconductor Co., Ltd. RTL8111/8168/8411 PCI Express Gigabit Ethernet Controller (rev 06)
-
Still on 6.8.3, yes. I'm looking forward to a few changes in 6.9, but I still prefer to wait for a stable release.
-
Its also still broken for me and makes me crazy. Everytime I login, I see that broken icon 😡 😉 I fixed this manually for now by replacing the PNG in /var/lib/docker/unraid/images/ with the correct one and removing the cached PNG from /var/local/emhttp/plugins/dynamix.docker.manager/images.
-
No, this was just a testing container. The actual container I have the issue with is the only mongo:4.0 container (even the only mongo container at all) on the system. Since it is not really an important issue, I will probably wait for 6.9 to check this again. Thanks for the help so far!
-
Sorry, should have mentioned that. I'm on 6.8.3. Tried clearing the cache and also tried it with dev tools (and disable cache option), doesn't seem to make a difference. I just tried it with a new container and it happens again. Initial container configuration: Initial icon URL: https://i.imgur.com/KDZALBF.png Updated icon URL: https://i.imgur.com/ajVjfzk.png When trying to change the icon URL to the updated URL, the icon still stays the same.
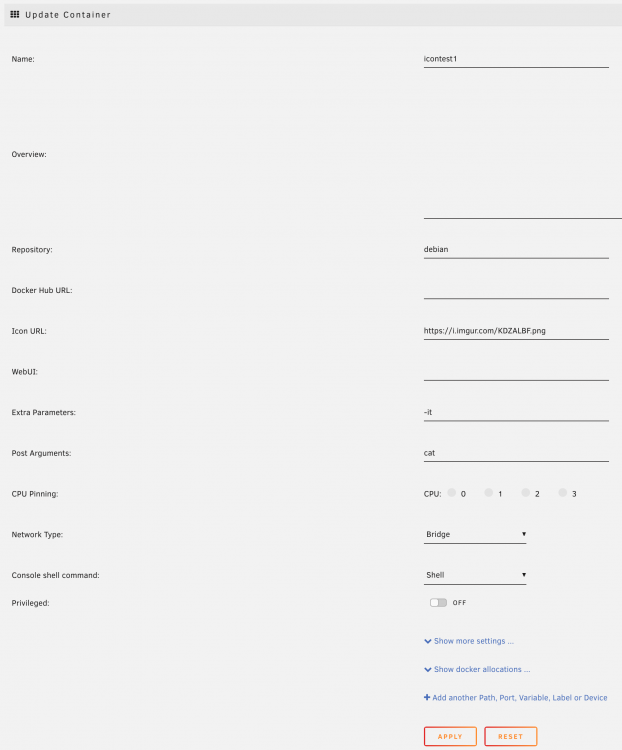
-
That is what I assumed, but the new image is under a completely different URL, unraid still doesn't download it again. I even tried setting it to the icon URL of one of the other containers, still no avail.




